
MPI-note-2
MPI编程笔记
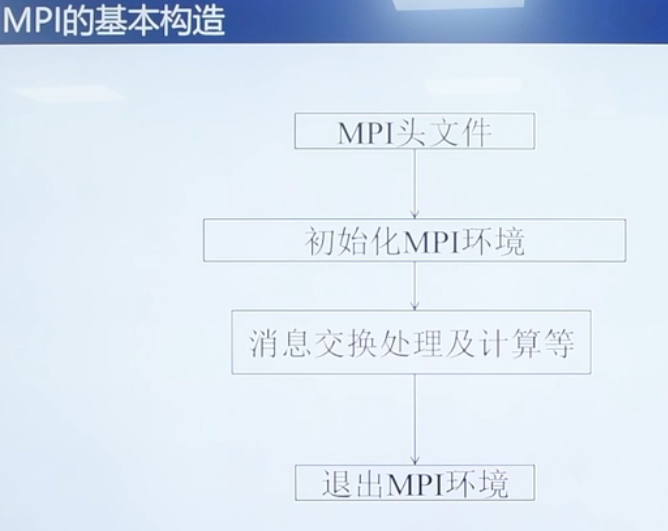
C语言中的头文件 #include "mpi.h"
4个基本函数
MPI_Init(int *argc,char ***argv)
完成MPI程序初始化工作,通过获取main函数的参数,让每一个MPI程序都能获取到main函数
MPI_Comm_rank(MPI_Comm comm,int *rank)
用于获取调用进程在给定的通信域中的进程标识号。默认一个最大通信域word。
通信域中的序号是有序的
假设一个通信域中有p个进程,编号为0到p-1,利用进程的序号来决定负责计算数据集的哪一个部分。
MPI_Comm_size(MPI_Comm comm,int *size)
返回给定的通信域中所包含的进程总数
MPI_Finalize(void)
MPI程序的最后一个调用,清除全部MPI环境
MPI点对点通信函数
MPI的通信机制是在一对进程之间传递数据,称为点对点通信
MPI提供的点对点通信数据传输有两种机制
- 阻塞:等消息从本地发出之后,才进行执行后续的语句
- 非阻塞:不需要等待,实现通信与计算的重叠
非阻塞MPI_Send/MPI_Recv
MPI_Send用于发送方
MPI_Send(void*buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm)
- buf 发送的数据缓存区的起始地址
- count 需要发送数据的个数
- datatype 需要发送的数据类型
- dest 目的进程的标识号
- tag 消息标志为tag
- comm 进程所在的域
MPI_Recv用于接收方
MPI_Recv(void*buf,int count,MPI_Datatype datatype,int source,int tag,MPI_Comm comm,MPI_Status *status)
从comm通信域中标识号为source的进程,接受消息标记为tag,消息数据类型为datatype,个数为count的消息并存储在buf缓冲区中,并将该过程的状态信息写入status中
在C语言中,status是一个结构体,包含了MPI_SOURCE(数据来源进程标识号),MPI_TAG(消息标记),MPI_ERROR
在Fortran语言中,status是一个整型的数组
阻塞MPI_Isend
Isend
int MPI_Isend(void*buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm,MPI_Request *request)
Irecv
int MPI_Irecv(void*buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm,MPI_Request *request)
MPI集合通信函数

1-n/n-1
集合通信还包括一个同步操作Barrier,所有进程都到达后才继续执行
MPI_Bcast(void *buffer,int count,MPI_Datatype datatype,int root,MPI_Comm comm)
从指定的一个根进程中把相同的数据广播发送给组中的所有其他进程
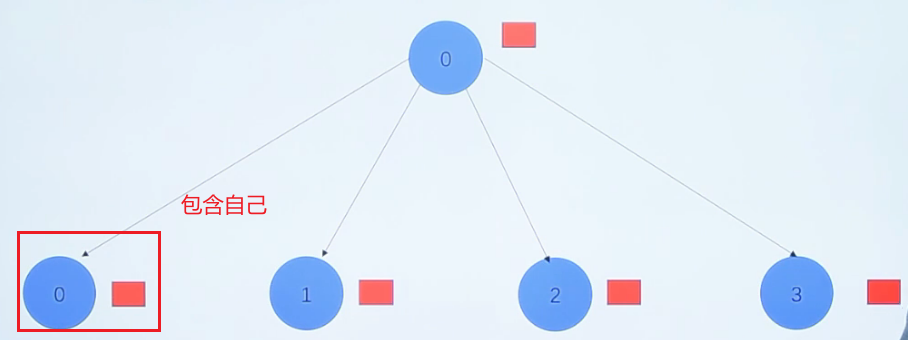
MPI_Scatter(void send_data,int send_count,MPI_Datatype send_datatype,void recv_data,int recv count,MPI_Datatype recv_datatype,int root,MPI_Comm communicator)
把指定的根进程中的数据分散发送给组中的所有进程(包括自己)

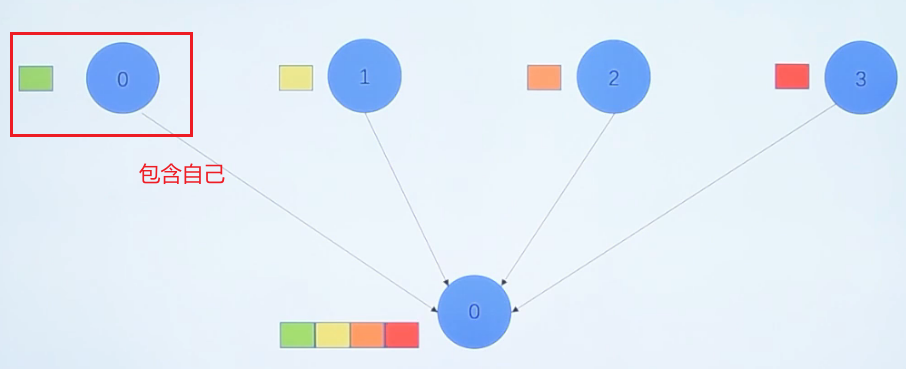
MPI_Gather(void *sendbuf,int sent_count,MPI_Datatype send_datatype,void *recv_data,int recv_count,MPI_Datatype recv_datatype,int root,MPI_Comm communicator)
在组中指定一个进程收集组中进程发来的消息,这个函数操作与MPI_Scatter函数操作相反
所有进程调用该函数,把指定位置的数据发送给根进程的指定位置
MPI_Reduce(void *send_data,void *recv_data,int count,MPI_Datatype datatype,MPI_Op op, int root,MPI_Comm communicator)
在组内所有的进程中,执行一个规约操作(算术等),并把结果存放在指定的一个进程中
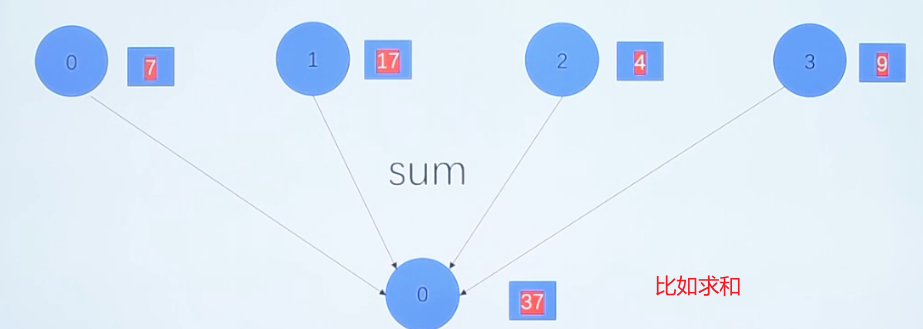
举例

n-n

常用函数
计时函数
double MPI_Wtime(void)
功能:返回某一时刻到调用时刻经历的时间(s)
案例
1 | double start_time,end_time,total_time; //初始化 |
获得本进程的机器名函数
int MPI_Get_processor_name(char name,intresultlen)
name为返回的机器名字符串,resultlen为返回的机器名长度
1 | //MPI_MAX_PROCESSOR_NAME代表MPI中允许机器名字的最大长度 |
测试案例
send
home/mpi/example/send_test.cpp
1 |
|
编译运行
1 | []$ mpicxx -o testmpi send_test.cpp |
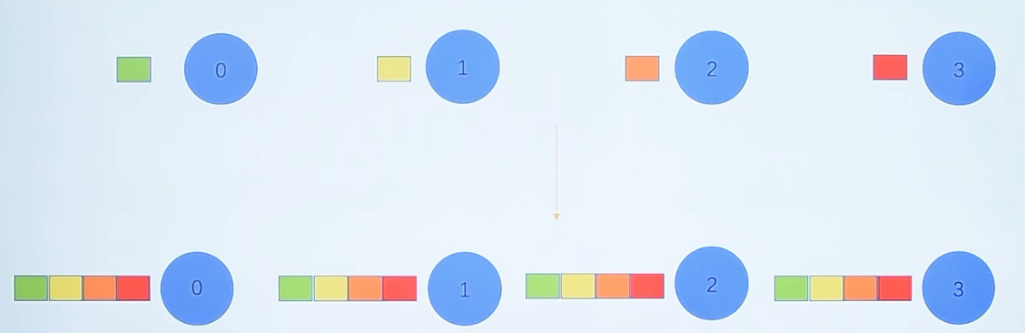
MPI_Scatter 与 MPI_Gather
1 |
|

补充问题
MPI如何与CUDA一起使用
答案来自文心一言
MPI(Message Passing Interface)和CUDA(Compute Unified Device Architecture)是两种不同的并行计算技术,它们可以结合使用,以在多个GPU和多个节点之间实现高效的并行计算。
MPI是一种基于消息传递的并行计算技术,它可以在多个节点之间分配和同步计算任务。MPI通过发送和接收消息来在节点之间传递数据,并且可以使用各种通信协议和网络接口来连接不同的节点。
CUDA是一种基于GPU的并行计算技术,它可以在单个GPU上实现高效的并行计算。CUDA使用一种称为“核函数”的编程模型,该模型使得开发者可以在GPU上执行大量的并行计算任务。
将MPI与CUDA结合使用,可以充分发挥多个GPU和多个节点的计算能力,从而加速各种高性能计算任务。下面是一些将MPI与CUDA结合使用的方法:
- 使用CUDA-aware MPI库:CUDA-aware MPI库是一种特殊的MPI库,它可以识别GPU设备,并在需要时将数据直接传输到GPU设备中。这样可以避免通过CPU进行数据传输的开销,从而提高并行计算的效率。
- 将计算任务分配给多个GPU:通过MPI将计算任务分配给多个GPU,可以使用CUDA在每个GPU上执行并行计算任务。这种方法可以加速各种深度学习和高性能计算任务。
- 在MPI中使用CUDA核函数:可以将CUDA核函数作为MPI进程的一部分来使用。这样可以在MPI进程之间共享CUDA核函数,并在多个节点上并行执行这些核函数。
总之,将MPI与CUDA结合使用可以加速各种高性能计算任务,但需要开发者熟悉这两种技术,并了解如何在它们之间进行有效的交互和数据传输。
NUMA架构简介
NUMA(Non-Uniform Memory Access)架构是一种计算机内存设计,它用于多处理器系统,其中不同的处理器或处理器组具有其自己的局部内存,而这些局部内存又与系统中的其他处理器共享。
在NUMA架构中,处理器可以访问自己的局部内存(本地内存访问)比访问其他处理器的内存(远程内存访问)更快。因此,内存访问时间不再是均匀的,这与传统的统一内存访问(UMA)模型形成对比,UMA模型中所有处理器访问内存的速度是相同的。
NUMA的主要特点:
-
本地和远程内存:每个处理器或处理器组有自己的本地内存。当处理器需要访问非本地内存时,它必须通过一个连接到其他处理器的内部互联网络。
-
内存访问延迟:访问本地内存的延迟比访问远程内存的延迟小。
-
扩展性:NUMA是为了解决多处理器系统的可扩展性问题而设计的,特别是在处理器数量增加时,UMA架构中的内存带宽和延迟成为瓶颈。
-
数据局部性:在NUMA系统中,软件优化通常着重于提高数据局部性,这意味着尽量确保处理器从其本地内存中访问数据。
为什么需要NUMA:
随着处理器核心数量的增加,UMA架构中的总线和内存访问成为瓶颈,因为所有处理器都试图访问同一个内存控制器和内存块。NUMA通过为每个处理器或处理器组提供自己的内存控制器和内存块,从而缓解了这个瓶颈。
注意事项:
在NUMA系统上编写和优化代码需要对NUMA架构有深入的了解。例如,操作系统和应用程序可能需要进行特定的调整,以确保数据和线程尽可能地局部于特定的处理器和内存。
总的来说,NUMA是一种解决高性能、多处理器系统中内存瓶颈问题的架构。随着现代服务器和数据中心中多核和多处理器系统的普及,NUMA的知识和优化技巧变得越来越重要。
- Title: MPI-note-2
- Author: Charles
- Created at : 2023-09-15 08:34:15
- Updated at : 2024-05-03 09:17:40
- Link: https://charles2530.github.io/2023/09/15/mpi-note-2/
- License: This work is licensed under CC BY-NC-SA 4.0.


