
基础知识:泛化、正则化与分布偏移
训练 loss 下降,只说明模型更会优化训练目标;泛化要问的是:它能不能在没见过的数据、没调过的场景和真实部署分布上继续工作。泛化是连接“优化看起来成功”和“模型真实可用”的桥。
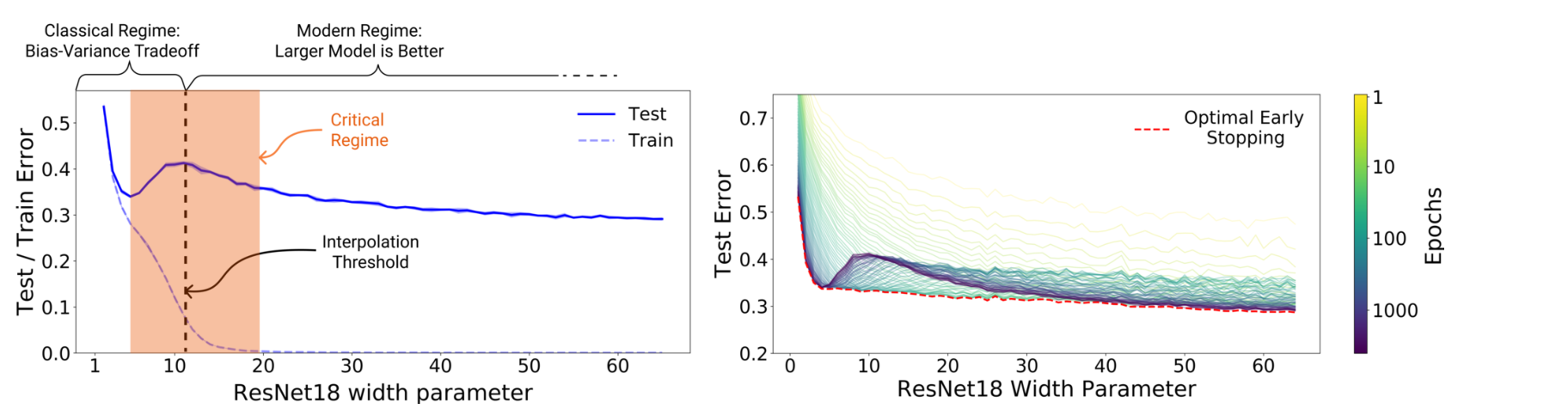
图源:Deep Double Descent: Where Bigger Models and More Data Hurt,Figure 1。原论文图意:左图展示 ResNet18 宽度变化时 train/test error 的 double descent;右图展示不同训练 epoch 下 test error 与 early stopping 曲线。
左图里 train error 持续下降,test error 却先降、再升、再降。它说明现代深度模型的泛化不能只用“模型越大越过拟合”一句话解释。右图提醒你,训练时间本身也会影响泛化;early stopping 不是让模型少学一点,而是在验证信号恶化前截住一个更可用的 checkpoint。
过拟合不是“模型太聪明”,而是模型把训练数据里的偶然模式、噪声或泄漏当成了规律。欠拟合是模型连训练数据里的主要规律都没学到。两者都要同时看 train loss、validation loss、分桶指标和错误样本。
train loss 继续下降但 validation 不涨、平均指标变好但新来源样本变差、数据增强一开主分布掉分、线上出现训练集从没覆盖的输入格式,回看本页。它能帮你判断该加正则、补数据、做分桶、停训,还是承认当前评测没有覆盖真实分布。
泛化误差怎么读
训练时最小化的是经验风险:
真正关心的是部署分布上的风险:
两者的差距就是泛化问题的核心。训练集上的 降低,不保证 降低,尤其当训练数据有噪声、泄漏、偏差或部署分布变化时。
过拟合、欠拟合和 train-val gap
| 现象 | 曲线表现 | 常见原因 | 优先检查 |
|---|---|---|---|
| 欠拟合 | train 和 validation 都差 | 模型容量不够、目标不对、训练不足 | loss、模型容量、学习率、数据标签 |
| 过拟合 | train 变好,validation 变差 | 记住训练样本、标签噪声、数据泄漏 | split、去重、正则、early stopping |
| 假泛化 | validation 好,真实场景差 | 验证集太像训练集或被反复调参 | holdout、线上回放、分桶 |
| 桶退化 | 平均分好,关键桶差 | 大桶主导优化,长尾覆盖不足 | per-bucket loss、样本权重、hard set |
Train-val gap 是一个信号,不是最终诊断。差距变大可能是过拟合,也可能是 validation 分布更难;差距很小也不代表没问题,可能是 train 和 validation 一起被泄漏污染。
Bias-Variance 直觉
Bias 可以理解成模型假设太硬,学不到真实规律;variance 可以理解成模型对训练样本太敏感,换一批数据就变。
| 视角 | 高 bias | 高 variance |
|---|---|---|
| 模型表现 | 训练集也学不好 | 训练集很好,验证集不稳 |
| 常见原因 | 模型太小、特征不足、目标不对 | 数据少、噪声大、模型太自由 |
| 常见处理 | 加模型容量、改输入、改目标 | 正则化、数据增强、去重、早停 |
现代大模型里,这个框架仍然有用,但不能机械套用。Double descent 说明,在某些区域里更大模型反而重新改善泛化;因此更稳的工程读法是:用曲线和分桶证据判断,而不是只按参数量下结论。
正则化在做什么
正则化的目标不是“让模型变弱”,而是限制它利用脆弱捷径。
| 方法 | 直觉 | 适合解决 |
|---|---|---|
| Weight decay | 惩罚过大的权重 | 减少尖锐、脆弱的拟合 |
| Dropout | 训练时随机丢部分激活 | 防止过度依赖少数路径 |
| Data augmentation | 制造合理输入变化 | 提升对视角、噪声、裁剪的鲁棒性 |
| Label smoothing | 不把标签推成绝对 one-hot | 减少过度自信 |
| Early stopping | 验证信号变差前停住 | 防止后期记噪声或适配训练集 |
过强正则会压掉真实任务信号。比如视觉任务中过度 crop 会删掉小物体,VLA 中过强颜色增强可能破坏物体材质线索,语言任务中过度去重可能删掉合法重复格式。正则化要看分桶收益,不是看配置名字。
分布偏移和 OOD
OOD 是 out-of-distribution,意思是输入或任务落在训练分布之外。更一般地,可以把分布偏移写成:
| 场景 | 分布偏移表现 | 应对方式 |
|---|---|---|
| LLM | 新格式、新知识、新工具协议 | RAG、回归集、格式校验 |
| VLM | 小字、图表、屏幕、低光 | 模态分桶、OCR 专项、hard set |
| 世界模型 | 新物体动态、新碰撞、新天气 | action-sensitive eval、rollout 分桶 |
| VLA | 新机器人、新夹爪、新相机 | embodiment metadata、闭环回放 |
OOD 不一定能完全消除。更实际的目标是:识别哪些分布已经覆盖,哪些分布只做了 paper-only 评测,哪些必须设置拒绝、人工接管或安全层。
一个泛化排查顺序
1 | 1. 看 train / validation / test 曲线是否一致 |
这个顺序的重点是先排除证据污染,再讨论模型和优化。否则很容易用更复杂的训练 recipe 掩盖数据划分问题。
和后续专题的关系
- 数据与数据集基础:泛化问题通常先从数据来源、去重和版本查起。
- 优化与训练入门:loss、梯度和 optimizer 如何产生训练曲线。
- 数据划分与评测指标:用 split、bucket 和 holdout 判断结论是否可信。
- 训练评测与消融:更完整的实验可信度判断。
- 世界模型评测与失效模式:rollout 漂移和闭环失效如何暴露分布偏移。
本页结论
泛化不是训练结束后的附加检查,而是从数据切分、训练目标、正则化、评测分桶到部署回放贯穿全程的问题。只看 train loss,会把“模型学会了训练集”误读成“模型可用”。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:数据划分与评测指标。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:泛化、正则化与分布偏移
- Author: Charles
- Created at : 2026-05-05 09:00:00
- Updated at : 2026-05-05 09:00:00
- Link: https://charles2530.github.io/2026/05/05/ai-files-foundations-generalization-regularization-and-distribution-shift/
- License: This work is licensed under CC BY-NC-SA 4.0.