
基础知识:生成与解码基础
生成模型训练时学的是概率分布,推理时要把这个分布一步步变成具体输出。解码就是从 logits 到 token、从 token 到长回答、从概率到系统成本的执行过程。
这页先回答“生成与解码基础”在「基础知识」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先知道 token、softmax、Transformer 和 KV cache 的基本读法。必要时先回 Transformer 输入与注意力、数值、显存与运行时 或 术语表。
主线关系:把 logits、temperature、top-k/top-p、beam、autoregressive generation、exposure bias 和 KV cache 串起来,给 LLM、推理系统、RLHF 和投机解码打底。
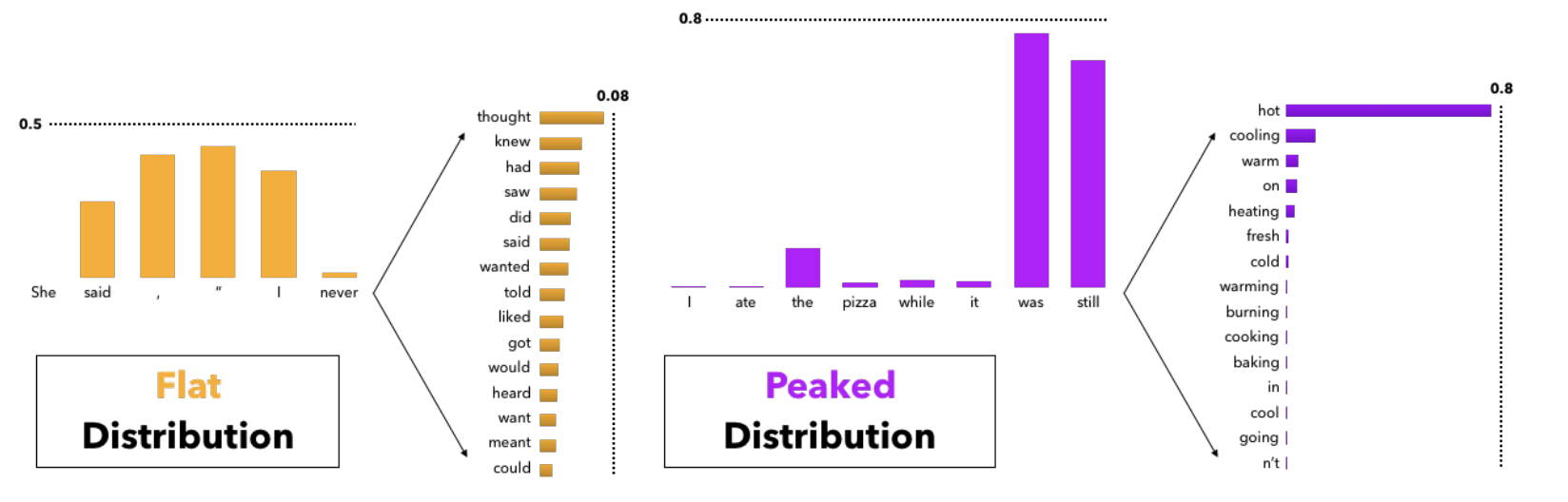
图源:The Curious Case of Neural Text Degeneration,Figure 5。原论文图意:展示不同上下文下 next-token probability distribution 可能是 flat 或 peaked,因此固定 top-k 在不同上下文里会截断过多或保留过多候选。
左侧 flat distribution 里,很多 token 都有中等概率;如果固定取很小的 top-k,可能砍掉合理候选。右侧 peaked distribution 里,概率集中在少数 token;如果固定取很大的 top-k,又会把长尾噪声放进采样。Nucleus sampling / top-p 的核心是按累计概率动态决定候选集合大小。
模型每一步先输出 logits,再经 softmax 变成概率分布。解码策略决定从这个分布里选哪个 token。低温度和 greedy 更稳定但可能死板;高温度和采样更多样但更不稳定;KV cache 决定长上下文生成时历史怎么被复用。
同一个 prompt 每次答案差很远、top-p 调大后格式崩、beam search 输出重复模板、长回答越写越偏、RL rollout 吞吐被 decode 卡住、KV cache 爆显存,先回看本页。本页帮你把“采样质量问题”和“推理系统问题”分开。
从 logits 到概率
最后一层语言模型通常输出 vocabulary 上的 logits:
softmax 把 logits 变成概率:
Temperature 会改变分布尖锐程度:
| 参数 | 直觉 | 典型效果 |
|---|---|---|
| 放大 logit 差异 | 更确定、更保守 | |
| 原始 softmax | 默认分布 | |
| 压平 logit 差异 | 更多样、更随机 |
Temperature 不会改变模型知道什么,只会改变从分布里取样的方式。
常见解码策略
| 策略 | 怎么选 token | 优点 | 风险 |
|---|---|---|---|
| Greedy | 每步选概率最高 token | 快、稳定、可复现 | 容易重复或卡局部最优 |
| Beam search | 保留多条高概率路径 | 适合翻译等短结构任务 | 生成开放文本时可能模板化 |
| Top-k | 只在概率最高的 k 个 token 中采样 | 简单控制候选集合 | flat/peaked 分布下 k 难固定 |
| Top-p | 选累计概率达到 p 的最小集合 | 候选数随上下文变化 | p 太大仍会放进长尾噪声 |
| Full sampling | 从完整分布采样 | 多样性最大 | 低概率坏 token 也会被采到 |
很多 API 会组合使用 temperature 和 top-p。比如先用 temperature 调整分布,再用 top-p 截断候选,最后从候选集合中采样。
自回归生成
Autoregressive generation 的核心是:前面生成的 token 会成为下一步输入。
1 | prompt |
公式上可以写成:
这里 是 prompt 或条件输入, 是第 个生成 token, 是已经生成的前缀。这个乘积说明一个现实问题:早期 token 选错,后面的条件也会变,错误可能滚雪球。
Exposure bias 是什么
训练时,模型常用 teacher forcing:每一步都看到真实前缀。推理时,模型看到的是自己刚生成的前缀。
1 | training: ground-truth prefix -> predict next token |
这个 train-inference mismatch 就是 exposure bias 的来源之一。它会导致长生成、代码补全、视频自回归和动作序列生成中出现累积漂移。缓解方式包括更好的数据覆盖、scheduled sampling、自回归 rollout 训练、强化学习、self-correction、投机验证和短 horizon 重规划。
Prefill、Decode 和 KV cache
生成请求通常分两段:
| 阶段 | 做什么 | 成本画像 |
|---|---|---|
| Prefill | 处理 prompt,把上下文写进 KV cache | 大矩阵、大 batch、并行度高 |
| Decode | 每次生成一个或少量新 token | 反复读 KV cache,容易受内存带宽影响 |
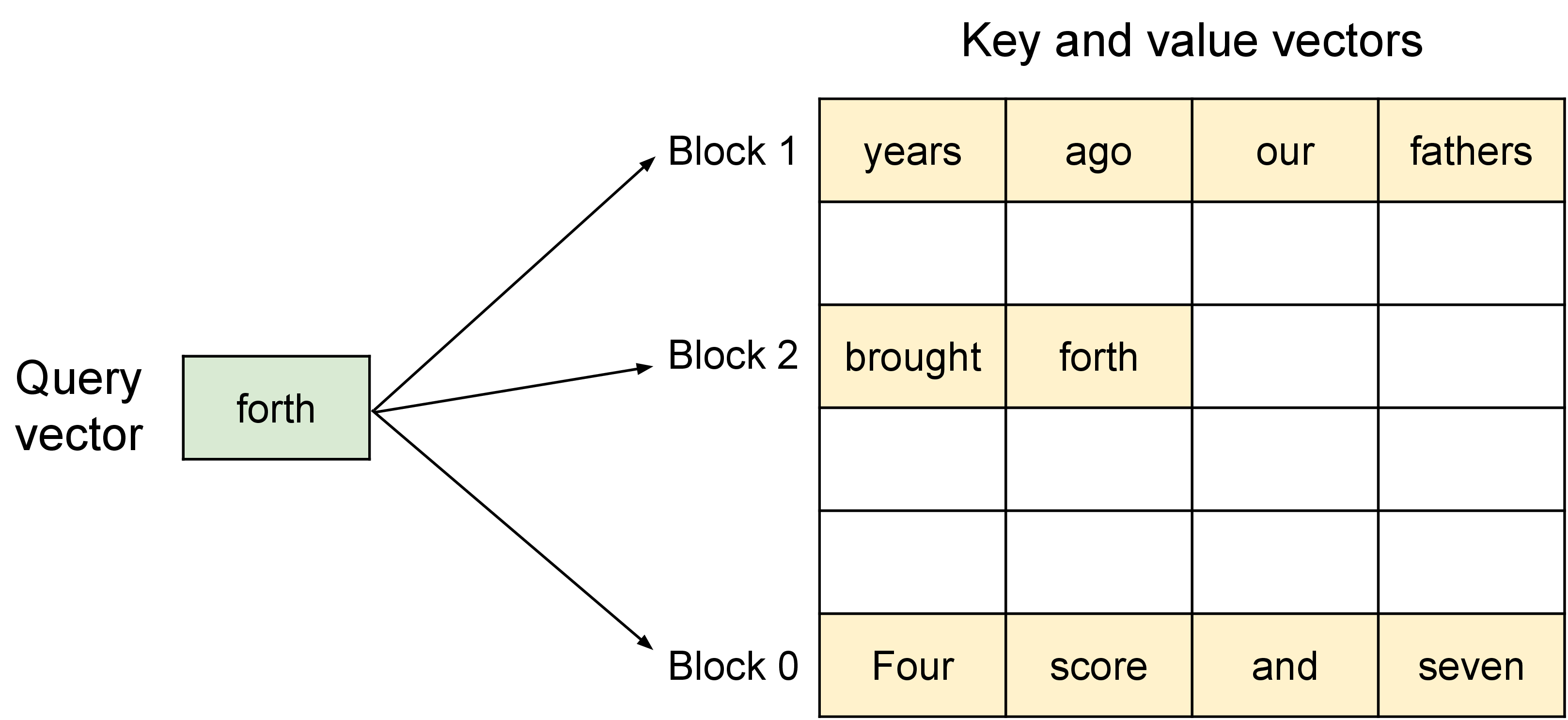
图源:Efficient Memory Management for Large Language Model Serving with PagedAttention,Figure 4。原论文图意:PagedAttention 允许 attention 的 K/V 向量存放在非连续物理内存块中,kernel 通过 block table 找到对应 KV block 并完成注意力计算。
PagedAttention 图里的重点是 KV cache 管理。自回归 decode 每一步都要读取历史 K/V;请求长度不同、生成长度不同、batch 动态变化时,KV 内存很容易碎片化。PagedAttention 把 KV cache 分块管理,支撑 continuous batching。也就是说,temperature/top-p 影响生成行为,KV cache layout 影响生成成本。
解码参数怎么选
| 目标 | 常见选择 | 注意 |
|---|---|---|
| 分类、抽取、JSON | 低 temperature,较低 top-p,严格 schema | 仍要外部校验 |
| 事实问答 / RAG | 低到中 temperature,引用约束 | 证据质量比采样更重要 |
| 创意写作 | 中高 temperature,较高 top-p | 需要长度和安全约束 |
| 数学代码 | 低温度或多样采样 + verifier | 单次 greedy 不一定最好 |
| RL rollout | 按任务调温度、top-p、n samples | 多样性和 token 成本一起算 |
Temperature 和 top-p 不能补上模型缺失的知识,也不能修复错误检索、坏 prompt 或训练数据漏洞。它们只改变从已有分布中选择 token 的方式。
和后续专题的关系
- Prompt、CoT 与 RAG 入门:prompt 决定看什么,解码决定怎么生成。
- 推理服务系统:请求生命周期、队列、batch 和服务指标。
- 缓存、路由与投机解码:speculative decoding 如何加速生成。
- MTP 与投机解码:训练目标如何服务解码加速。
- PG / PPO / GRPO:RL rollout 如何依赖采样分布和 reward。
本页结论
解码是生成模型从概率到输出的最后一公里。先分清 logits、softmax、temperature、top-k/top-p、beam、autoregressive prefix 和 KV cache,再讨论 prompt、RLHF、投机解码或 serving 性能,很多问题会清楚很多。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:Prompt、CoT 与 RAG 入门。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:生成与解码基础
- Author: Charles
- Created at : 2026-05-06 09:00:00
- Updated at : 2026-05-06 09:00:00
- Link: https://charles2530.github.io/2026/05/06/ai-files-foundations-generation-and-decoding-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.