
基础知识:预训练目标与表示学习
预训练目标回答的是:在没有最终任务标签或只有弱标签时,模型到底被要求学什么。理解这些目标,读 LLM、VLM、扩散、世界模型和 VLA 时就不会把所有 loss 都混成“让模型变好”。
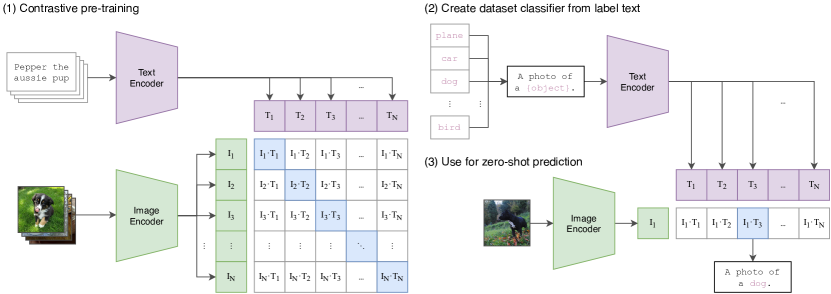
图源:Learning Transferable Visual Models From Natural Language Supervision,Figure 1。原论文图意:CLIP 先用大量 image-text pairs 做对比预训练,再把文本类别转成 prompts,通过图文 embedding 相似度完成 zero-shot prediction。
CLIP 图里最重要的是 image encoder 和 text encoder 输出到同一个 embedding 空间。训练目标不是让模型生成图片,也不是让模型输出机器人动作,而是让匹配图文靠近、不匹配图文远离。这样的表示适合检索、分类和 VLM 初始化,但它本身不包含动作后果、reward 或闭环安全。
预训练目标规定了“什么算预测对”。Next-token 让模型学序列延续,masked modeling 让模型补上下文缺口,对比学习让匹配样本靠近,重建让信息能被还原,去噪让模型学数据分布方向,行为克隆让策略模仿专家动作。
读论文时看到 MLE、InfoNCE、masked prediction、denoising、score matching、behavior cloning 却不知道它们差在哪,或者模型在预训练指标上很好但下游决策不稳,回看本页。目标函数会告诉你模型被训练成了什么,也会暴露它没有被训练什么。
一张目标函数地图
| 目标 | 输入 | 预测什么 | 常见用途 | 不直接保证 |
|---|---|---|---|---|
| Next-token prediction | 前缀 token | 下一个 token | LLM、多模态 token 模型 | 事实正确、动作安全 |
| Masked modeling | 被遮挡的输入 | mask 处 token 或 latent | BERT、MAE、V-JEPA | 自回归生成能力 |
| Contrastive learning | 正负样本对 | 匹配关系 / embedding 相似度 | CLIP、检索、对齐 | 生成细节或因果动态 |
| Reconstruction | 压缩表示 | 原始输入或局部内容 | Autoencoder、VAE、视觉 tokenizer | 表示一定可规划 |
| Denoising / score | 带噪样本 | 噪声、score 或干净样本 | 扩散、score models | 少步生成或实时控制 |
| Behavior cloning | 观测和任务 | 专家动作 | VLA、机器人策略 | 失败恢复和探索 |
目标函数不是越多越好。关键是它是否和最终使用接口一致:要生成文本,就需要生成目标;要做检索,就需要表示对齐;要做决策,就需要动作、reward、风险或闭环反馈。
Next-token prediction
自回归语言模型最经典的目标是:
它让模型在给定历史前缀时预测下一个 token。这个目标简单、可扩展、能吃海量文本,也能把图像 token、视频 token 或动作 token 统一成序列建模。
但 next-token 只告诉模型“在数据里下一个 token 常是什么”。它不自动知道回答是否真实、动作是否安全、工具调用是否真的成功。后训练、RAG、verifier、RL 和评测系统都是在补这些接口。
Masked modeling 和 latent prediction
Masked modeling 把输入的一部分遮住,让模型从上下文预测缺失部分:
如果预测的是像素或 token,模型会更重视可重建细节;如果预测的是 target encoder 的 latent,模型更可能学抽象结构。
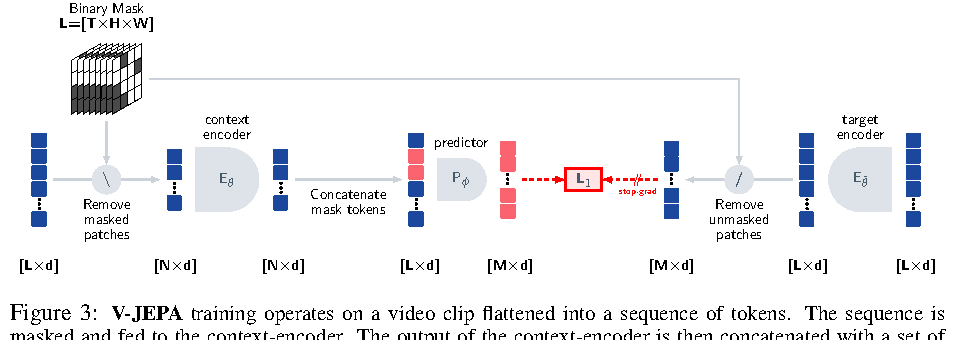
图源:V-JEPA: Latent Video Prediction for Visual Representation Learning,Figure 3。原论文图意:context encoder 只处理 masked video 中可见 token,predictor 结合 context output 和 mask tokens 去预测 target encoder 对完整视频产生的 masked token representations。
图中 context encoder 只看未遮挡视频块,predictor 去预测 target encoder 给出的被遮挡区域表示。这个目标减少了逐像素重建的冗余,更关注运动和语义结构。它能支撑视频表示学习,但原始 V-JEPA 不直接包含 action、reward、done 或 closed-loop policy。
Contrastive learning
对比学习把正样本拉近,把负样本推远。InfoNCE 常见写法是:
这里 是 query 表示, 是匹配的正样本, 是负样本, 是 temperature。这个目标让 embedding 空间具备检索和对齐能力,但它的质量依赖负样本、数据覆盖和语义粒度。
Reconstruction、denoising 和 score
Reconstruction 让模型从压缩表示还原输入:
它适合训练 autoencoder、VAE、视觉 tokenizer 或视频压缩模块。风险是模型可能保留了重建细节,却没有保留决策相关状态。
Denoising / score matching 则把生成建模改写成“从噪声恢复数据”:

图源:Denoising Diffusion Probabilistic Models,Figure 2。原论文图意:前向过程 逐步加噪,反向生成过程 逐步去噪,从噪声链条恢复数据样本。
DDPM 图里的 负责把真实数据逐步加噪, 负责学习反向去噪。训练时常让模型预测噪声、velocity 或 score;采样时则沿着学到的方向从噪声走回数据。这和 next-token 不同:它不是一次选下一个 token,而是在连续或离散噪声层级中反复更新样本。
Behavior cloning
行为克隆把策略学习写成监督学习:给定观测和任务,让模型模仿专家动作。
这里 是历史观测, 是语言或任务条件, 是专家动作。连续动作也常用 MSE/L1 或 action diffusion 目标。
BC 的优点是稳定、简单、能利用示范数据;缺点是它主要学数据里出现过的动作。部署时一旦偏离专家轨迹,模型可能不知道怎么恢复。这也是为什么 VLA 和世界模型后面会接数据引擎、闭环评测、offline RL、PPO/GRPO 或 MPC。
怎么判断目标和任务是否匹配
| 最终目标 | 预训练目标是否够用 | 还需要什么 |
|---|---|---|
| 写作、问答、代码 | next-token 是核心底座 | RAG、SFT、RL、verifier |
| 图文检索 | contrastive 很合适 | hard negative、领域数据 |
| 图像/视频生成 | denoising 或 autoregressive token | 采样器、条件控制、评测 |
| 世界模型 | latent prediction / dynamics | action、reward、risk、rollout eval |
| VLA 控制 | BC 是基础入口 | 失败恢复、闭环、动作安全层 |
预训练目标只覆盖它定义过的信号。CLIP 相似度高不代表能控制机器人;V-JEPA 表征好不代表能预测动作后果;BC loss 低不代表偏离轨迹后会恢复;扩散 FID 好也不代表条件执行和安全边界都可靠。
和后续专题的关系
- 优化与训练入门:loss、gradient 和训练循环的共同机制。
- 概率与潜变量模型:生成分布、latent 和采样的基础。
- VLM 架构与训练:CLIP、BLIP-2、V-JEPA 等目标如何进入 VLM。
- 扩散模型路线图:denoising 和 score matching 的完整展开。
- VLA 数据与策略学习:behavior cloning、动作 token 和策略学习。
本页结论
预训练目标决定模型最先学会的接口:续写、补全、对齐、重建、去噪或模仿动作。读论文时先问“它的 loss 让模型预测什么”,再问“这个预测目标是否足够支撑最终任务”。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:优化与训练入门。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:预训练目标与表示学习
- Author: Charles
- Created at : 2026-05-08 09:00:00
- Updated at : 2026-05-08 09:00:00
- Link: https://charles2530.github.io/2026/05/08/ai-files-foundations-pretraining-objectives-and-representation-learning/
- License: This work is licensed under CC BY-NC-SA 4.0.