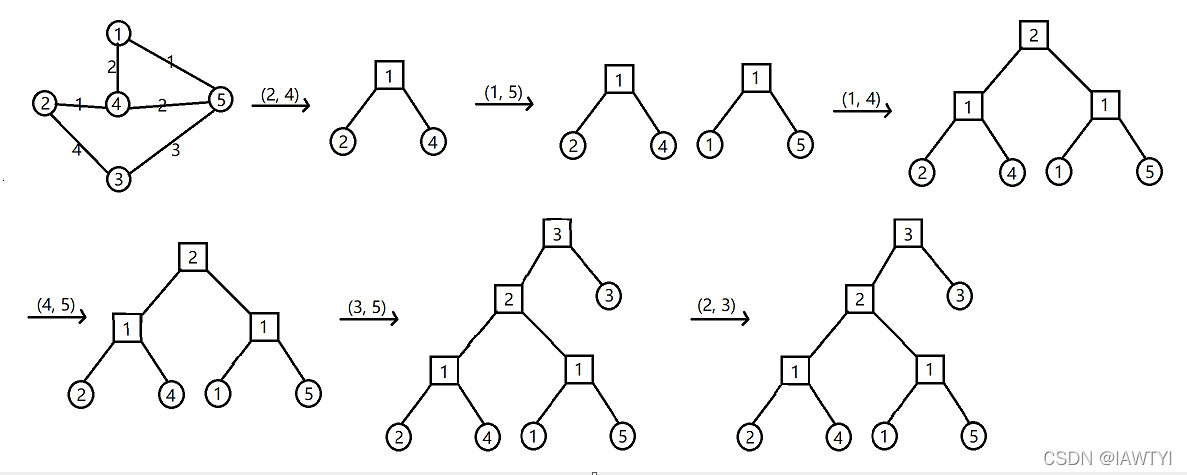
最小生成树(minimum spanning tree)是由n个顶点,n-1条边,将一个连通图连接起来,且使权值最小的结构。
最小生成树可以用Prim(普里姆)算法或kruskal(克鲁斯卡尔)算法求出。
要在n个城市之间铺设光缆,主要目标是要使这 n 个城市的任意两个之间都可以通信 ,但铺设光缆的费用很高,且各个城市之间铺设光缆的费用不同,因此另一个目标是要使铺设光缆的总费用最低。这就需要找到 带权的最小生成树 。
① 先建立一个只有一个结点的树,这个结点可以是原图中任 意的一个结点。
首先需要将各点之间的距离初始化为无限大,表示各点之间无法到达。
1 2 3 4 5 6 7 8 for (int i = 1 ; i <= n; i++) { for (int j = 1 ; j <= n; j++) { if (i == j) e[i][j] = 0 ; else e[i][j] = INF; } }
之后读入各边权值,由于有时各点之间会出现权值不同的起止位置相同的边,所以需要判断并保留权值最小的边。
1 2 3 4 5 6 7 8 for (int i = 1 ; i <= m; i++) { cin >> x >> y >> w; if (e[x][y] && e[x][y] < w) { continue ; } e[x][y] = w; e[y][x] = w; }
之后便是Prim算法的主体部分
首先是初始化dis数组
1 2 3 for (int i = 1 ; i <= n; i++) { dis[i] = e[1 ][i]; }
之后在循环中需要做两件事——找到距离最小的结点和更新结点。
寻找最小结点:
1 2 3 4 5 6 7 int mini = INF, j = -1 ;for (int i = 1 ; i <= n; i++) { if (!book[i] && dis[i] < mini) { mini = dis[i]; j = i; } }
更新结点:
1 2 3 4 5 for (int i = 1 ; i <= n; i++) { if (!book[i] && dis[i] > e[j][i]) { dis[i] = e[j][i]; } }
整体函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 bool Prim () for (int i = 1 ; i <= n; i++) { dis[i] = e[1 ][i]; } book[1 ] = 1 ; cnt++; while (cnt < n) { int mini = INF, j = -1 ; for (int i = 1 ; i <= n; i++) { if (!book[i] && dis[i] < mini) { mini = dis[i]; j = i; } } if (j == -1 ) { return false ; } book[j] = 1 ; cnt++; sum += dis[j]; for (int i = 1 ; i <= n; i++) { if (!book[i] && dis[i] > e[j][i]) { dis[i] = e[j][i]; } } } return true ; }
上面这种方法的时间复杂度是 O($N{^2}$)。如果借助“堆”,每次选边的时间复杂度是 $O(logM)$然后使用邻接表来存储图的话,整个算法的时间复杂度会降低到 O($M$$logM$)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 typedef pair<int , int > pii;priority_queue<pii, vector<pii>, greater<pii> > que; bool Prim () for (int i = 1 ; i <= n; i++) { dis[i] = INF; } dis[1 ] = 0 ; que.push (make_pair (0 , 1 )); while (!que.empty () && cnt < n) { int mini_dis = que.top ().first; int u = que.top ().second; que.pop (); if (!book[u]) { cnt++; sum += mini_dis; book[u] = 1 ; int k = g.head[u]; while (k != -1 ) { if (g.e[k].val < dis[g.e[k].to]) { dis[g.e[k].to] = g.e[k].val; que.push (make_pair (dis[g.e[k].to], g.e[k].to)); } k = g.e[k].link; } } } if (cnt != n) { return false ; } return true ; }
tips:kruskal只需要维护连通性,可以不需要真正建立图T,还可以用并查集来维护。
Kruskal 算法是能够在O(mlogm) 的时间内得到一个最小生成树的算,它主要是基于贪心的思想。
① 将边按照边权从小到大排序,并建立一个没有边的图T。
Kruskal算法实现分为两个步骤,首先是按照边的权值大小进行排序,之后就是使用并查集进行结点的合并。(具体细节可以见下方模板题)
1 2 3 4 bool cmp (Node c, Node d) return c.weight < d.weight; } sort (p, p + e, cmp);
并查集部分可以见之前的博客,这里只提供部分代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int get_f (int v) if (f[v] == v) { return v; } else { f[v] = get_f (f[v]); return f[v]; } } int merge (int v, int u) int t1, t2; t1 = get_f (v); t2 = get_f (u); if (t1 != t2) { f[t2] = t1; return 1 ; } return 0 ; } for (int i = 0 ; i < e; i++) { if (merge (p[i].x, p[i].y)) { sum += p[i].weight; } }
之前在Kruskal开头提到我们用Kruskal求最小生成树时并不真的需要建树,只要用并查集维护就可以,但这并不代表生成的那棵树就是没有用到,所以就诞生了Kruskal重构树的一些用法。
Kruskal重构树就是在用Kruskal算法计算最小生成树时,构造出一棵树。当题目需要用到最小生成树时,常常利用重构树将其转化为树上问题。克鲁斯卡尔重构树可以用来解决一类诸如“查询从某个点出发经过边权不超过val的边所能到达的节点”的问题。
克鲁斯卡尔重构树的思想就是在建最小生成树的时候不是直接连边,而是新建一个节点,并把这个节点的值设为边权,然后令两个连通块的代表点分别作为它的左右儿子。然后令这个新节点成为整个连通块的代表点
具体实现步骤如下:
1.将边权从小到大排个序(和Kruskal算法一样)。
1.Kruskal重构树是二叉树
网上找的,我也没写过,不过这也确实是个比较小众的知识点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 int n, m;int k, T, S, D;struct edge { int a, b, w; bool operator <(const edge& ee)const { return w < ee.w; } }ed[M]; vector<int > e[N]; int d[N];int p[N];int a[N];int down[N];int fa[N][18 ];int find (int x) return p[x] == x ? p[x] : p[x] = find (p[x]); } int kruskal () sort (ed + 1 , ed + 1 + m); fer (i, 1 , 2 *n)p[i] = i; int cnt = n; fer (i, 1 , m) { int a = find (ed[i].a), b = find (ed[i].b); if (a^b){ d[++cnt]=ed[i].w; p[a]=p[b]=cnt; e[cnt].push_back (a); e[cnt].push_back (b); } } return cnt; }
解决最小生成树的问题一般有两种方式:prim 和 Kruskal 。
从上面介绍的两个最短生成树算法可以看出,如果所有的边权都不相等,那么最小生成树是唯一的。Kruskal算法是一步步地将森林中的树进行合并,而Prim算法则是通过每次增加一条边来建立一棵树。Kruskal算法更适用于稀疏图,没有使用堆优化的 Prim算法适用于密图,使用了堆优化的 Prim算法则更适用于稀疏图。
给一个带权的图,把图的所有生成树按照权值从小到大排序,第二小的称为次小生成树,这里的次小生成树其实有两种,分为非严格次小生成树与严格次小生成树,非严格次小生成树与原来的最小生成树边权可能是相等的,而严格次小生成树是边权之和严格大于最小生成树。
方法1:先求解最小生成树然后再删除最小生成树的边求解,删除完了之后再做一遍最小生成树,时间复杂度为O(mlogm + nm)。
方法2:先求解最小生成树然后依次枚举非树边,然后将该边加入到树中,同时从树中去掉一条边,使得最终的图形仍然是一棵树。
可以发现次小生成树一定是这些方案中,所以一定可以求解出次小生成树,去掉一条边与加上一条边对权值的影响,sum + W新 - W树,因为要使结果更小而当前枚举的W新是固定的,所以要使W树最大,所以对于当前非树边(a,b,w)而言应该要去掉的是a->b中最大的一条边(因为加入非树边之后构成了一个换所以需要去除掉一条边此时还是一棵树),当W新 - W树 = 0的时候可以求解次小生成树,当W新 - W树 > 0时求解的是严格的次小生成树,这一点其实很灵活,而且这样求解肯定可以求解出次小生成树。
参考资料:最小生成树总结
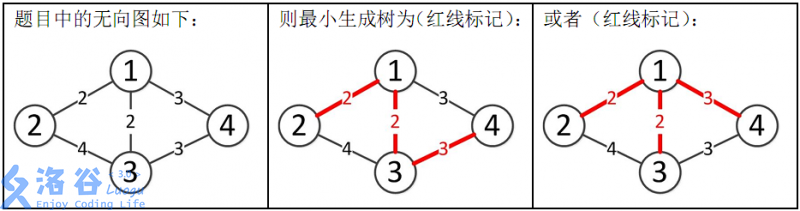
如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出 orz。
第一行包含两个整数 $N,M$,表示该图共有 $N$ 个结点和 $M$ 条无向边。
接下来 $M$ 行每行包含三个整数 $X_i,Y_i,Z_i$,表示有一条长度为 $Z_i$ 的无向边连接结点 $X_i,Y_i$。
如果该图连通,则输出一个整数表示最小生成树的各边的长度之和。如果该图不连通则输出 orz。
1 2 3 4 5 6 4 5 1 2 2 1 3 2 1 4 3 2 3 4 3 4 3
数据规模:
对于 $20%$ 的数据,$N\le 5$,$M\le 20$。
对于 $40%$ 的数据,$N\le 50$,$M\le 2500$。
对于 $70%$ 的数据,$N\le 500$,$M\le 10^4$。
对于 $100%$ 的数据:$1\le N\le 5000$,$1\le M\le 2\times 10^5$,$1\le Z_i \le 10^4$。
样例解释:
所以最小生成树的总边权为 $2+2+3=7$。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> using namespace std;#define M 200007 #define N 5007 #define INF 0x3f3f3f3f #define ll long long #define db double int n, e, top = 0 , sum = 0 ;int f[N];typedef struct node { int x, y; int weight; } Node; Node p[M]; bool cmp (Node c, Node d) return c.weight < d.weight; } int get_f (int v) if (f[v] == v) { return v; } else { f[v] = get_f (f[v]); return f[v]; } } int merge (int v, int u) int t1, t2; t1 = get_f (v); t2 = get_f (u); if (t1 != t2) { f[t2] = t1; return 1 ; } return 0 ; } int main () cin >> n >> e; for (int i = 0 ; i < e; i++) { scanf ("%d%d%d" , &p[i].x, &p[i].y, &p[i].weight); } sort (p, p + e, cmp); for (int i = 0 ; i < n; i++) f[i] = i; for (int i = 0 ; i < e; i++) { if (merge (p[i].x, p[i].y)) { top++; sum += p[i].weight; } } if (top != n - 1 ) { cout << "orz" << endl; } else cout << sum << endl; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <bits/stdc++.h> using namespace std;#define M 100007 #define N 5007 #define INF 0x3f3f3f3f #define ll long long #define db double int dis[N], book[N], e[N][N];int n, m, cnt, sum;bool Prim () for (int i = 1 ; i <= n; i++) { dis[i] = e[1 ][i]; } book[1 ] = 1 ; cnt++; while (cnt < n) { int mini = INF, j = -1 ; for (int i = 1 ; i <= n; i++) { if (!book[i] && dis[i] < mini) { mini = dis[i]; j = i; } } if (j == -1 ) { return false ; } book[j] = 1 ; cnt++; sum += dis[j]; for (int i = 1 ; i <= n; i++) { if (!book[i] && dis[i] > e[j][i]) { dis[i] = e[j][i]; } } } return true ; } int main () ios::sync_with_stdio (false ); cout.tie (NULL ); cin >> n >> m; for (int i = 1 ; i <= n; i++) { for (int j = 1 ; j <= n; j++) { if (i == j) e[i][j] = 0 ; else e[i][j] = INF; } } int x, y, w; for (int i = 1 ; i <= m; i++) { cin >> x >> y >> w; if (e[x][y] && e[x][y] < w) { continue ; } e[x][y] = w; e[y][x] = w; } if (Prim ()) { cout << sum; } else { cout << "orz" ; } return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 #include <bits/stdc++.h> using namespace std;#define M 200007 #define N 5007 #define INF 0x3f3f3f3f #define ll long long #define db double int dis[N], book[N];int n, m, cnt, sum;typedef struct edge { int from, to, link; int val; } Edge; typedef struct node { int id; } Node; typedef struct graph { int head[N]; int node_num = 0 ; Node p[N]; int edge_num = 0 ; Edge e[M << 1 ]; } Graph; Graph g; void add_edge (int from, int to, int val) g.e[++g.edge_num].to = to; g.e[g.edge_num].from = from; g.e[g.edge_num].val = val; g.e[g.edge_num].link = g.head[from]; g.head[from] = g.edge_num; } typedef pair<int , int > pii;priority_queue<pii, vector<pii>, greater<pii> > que; bool Prim () for (int i = 1 ; i <= n; i++) { dis[i] = INF; } dis[1 ] = 0 ; que.push (make_pair (0 , 1 )); while (!que.empty () && cnt < n) { int mini_dis = que.top ().first; int u = que.top ().second; que.pop (); if (!book[u]) { cnt++; sum += mini_dis; book[u] = 1 ; int k = g.head[u]; while (k != -1 ) { if (g.e[k].val < dis[g.e[k].to]) { dis[g.e[k].to] = g.e[k].val; que.push (make_pair (dis[g.e[k].to], g.e[k].to)); } k = g.e[k].link; } } } if (cnt != n) { return false ; } return true ; } int main () ios::sync_with_stdio (false ); cout.tie (NULL ); cin >> n >> m; int x, y, w; memset (g.head, -1 , sizeof (g.head)); for (int i = 1 ; i <= m; i++) { cin >> x >> y >> w; add_edge (x, y, w); add_edge (y, x, w); } if (Prim ()) { cout << sum; } else { cout << "orz" ; } return 0 ; }