
lab4_report
lab4_report
lab_thinkings
Thinking 4.1
question
思考并回答下面的问题:
• 内核在保存现场的时候是如何避免破坏通用寄存器的?
• 系统陷入内核调用后可以直接从当时的 $a0-$a3 参数寄存器中得到用户调用 msyscall留下的信息吗?
• 我们是怎么做到让 sys 开头的函数“认为”我们提供了和用户调用 msyscall 时同样的参数的?
• 内核处理系统调用的过程对 Trapframe 做了哪些更改?这种修改对应的用户态的变化是什么?
answer
- 内核使用宏函数
SAVE_ALL来保存现场,在该函数的代码实现里,只使用了k0和k1两个通用寄存器来进行操作,从而保证其他通用寄存器的值都不会被改变。 - 可以。因为内核在陷入内核、保存现场的过程中,寄存器a0−a3中的值都没有被破坏。
- 用户在调用
msyscall时,传入的参数会被保存在a0−a3寄存器和堆栈中。当陷入内核时,a0−a3寄存器不会被破坏,而且用户栈中的内容会被原封不动地被拷贝到内核栈(KERNEL_SP)中。因此,sys_*函数可以从寄存器和用户栈获得"用户调用msyscall时传入的参数值"。 - 在处理过程中,将
Trapframe中epc的值进行了一定处理,同时将sys_*函数的返回值存入Trapframe中的v0寄存器中。这种修改保证在进入用户态时,用户程序能够从正确的位置正确运行,同时也使得用户程序从v0寄存器中获得系统调用的返回值。
Thinking 4.2
question
思考 envid2env 函数: 为什么 envid2env 中需要判断 e->env_id != envid的情况?如果没有这步判断会发生什么情况?
answer
通过阅读该函数的代码,我们能知道,e是根据envid的后10位从envs数组中获得的。但是这样获得的e的envid不一定和envid相同,因为envid中还有ASID字段(11-16位),当envs中的某一个进程控制块被替换,新生成的envid的后10不变,但是ASID字段会改变。所以我们需要进一步判断e->env_id != envid是否成立。
如果不判断,则通过最终获得的e可能并不是我们想要的内存控制块,而如果对这个错误的内存控制块操作,则可能会导致内存控制出现混乱(例如获得一个仍在env_free_list中的PCB,然后运行它)。
Thinking 4.3
question
思考下面的问题,并对这个问题谈谈你的理解:请回顾 kern/env.c 文件中 mkenvid() 函数的实现,该函数不会返回 0,请结合系统调用和 IPC 部分的实现与envid2env() 函数的行为进行解释。
answer
回顾mkenvid的实现我们会发现,envid的第10位永远是1,即保证了生成的envid一定是非0的——
1 | u_int mkenvid(struct Env *e) { |
所以为什么将0作为一个保留值呢?我们能在envid2env函数中会找到答案——
1 | int envid2env(u_int envid, struct Env **penv, int checkperm) |
可以发现,当envid的值是0时,函数会返回指向当前进程控制块的指针(通过形参penv返回)。当某些系统调用函数需要访问当前进程的进程控制块时,可以直接通过向envid2env传0来会获得指向当前进程控制块的指针,然后通过指针对进程控制块进行访问。
因此,0作为envid的保留值是为了方便程序直接通过envid2env函数来访问当前进程的进程控制块。
Thinking 4.4
question
关于 fork 函数的两个返回值,下面说法正确的是:
A、fork 在父进程中被调用两次,产生两个返回值
B、fork 在两个进程中分别被调用一次,产生两个不同的返回值
C、fork 只在父进程中被调用了一次,在两个进程中各产生一个返回值
D、fork 只在子进程中被调用了一次,在两个进程中各产生一个返回值
answer
当子进程被调度时,恢复的上下文环境是在fork函数中(实际上是syscall_env_alloc函数之后),但是这并非是真正的调用了fork函数,只是复制了父进程的上下文而已。此外,执行完fork函数后,父进程返回的是子进程的envid,子进程返回的是0,因此父子进程的返回值是不同的。综上,答案为C。
Thinking 4.5
question
我们并不应该对所有的用户空间页都使用 duppage 进行映射。那么究竟哪些用户空间页应该映射,哪些不应该呢?请结合 kern/env.c 中 env_init 函数进行的页面映射、include/mmu.h 里的内存布局图以及本章的后续描述进行思考。
answer
UTOP和TLIM之间储存的是和内核相关的页表信息。在执行env_alloc()函数时,这一部分的映射关系直接从boot_pgdir拷贝到进程页表中,因此不需要进行映射。
UTOP和USTACKTOP之间是异常处理栈(user exception stack)和无效内存(invalid memory),前者是进行异常处理的地方, 后者一般也不会用到,所以父子进程不需要共享这部分的内存,也就不需要进行映射了。
所以,最终需要被映射的页面只有USTACKTOP之下的部分。
Thinking 4.6
question
在遍历地址空间存取页表项时你需要使用到 vpd 和 vpt 这两个指针,请参考 user/include/lib.h 中的相关定义,思考并回答这几个问题:
• vpt 和 vpd 的作用是什么?怎样使用它们?
• 从实现的角度谈一下为什么进程能够通过这种方式来存取自身的页表?
• 它们是如何体现自映射设计的?
• 进程能够通过这种方式来修改自己的页表项吗?
answer
vpt和vpd分别是指向用户页表和用户页目录的指针,可以用来对用户页表和页目录进行访问。在使用的时候,以vpt为例,先用*运算符获得页表基地址,然后从要访问的虚拟地址中获得页表项相对基地址的偏移,最后两个相加就得到指向页表项的指针,这样我们就可以通过这个指针来对页表项进行访问,vpd同理。- 在
entry.S中我们可以找到vpt和vpd的定义——可以发现,1
2
3
4
5
6
7.globl vpt
vpt:
.word UVPT
.globl vpd
vpd:
.word (UVPT+(UVPT>>12)*4)vpt和vpd分别指向了两个值——UVPT和(UVPT+(UVPT>>12)*4),这两个值分别是用户地址空间中页表的首地址和页目录的首地址。所以我们可以直接通过vpt和vpd访问到用户进程页表和页目录。 - 上面说到,
vpd的值是(UVPT+(UVPT>>12)*4),而这个地址正好在UVPT和UVPT+PDMAP之间,说明页目录被映射到了某一个页表的位置。我们知道,每一个页表都被页目录中的一个页表项所映射。因此"页目录被映射到某一个页表的位置"就意味着,在页目录中一定有一个页表项映射到了页目录本身,即实现了自映射。 - 不能,页表是内核态程序维护的,用户进程只能对页表项其进行访问,而不能对其进行修改。
Thinking 4.7
question
在 do_tlb_mod 函数中,你可能注意到了一个向异常处理栈复制 Trapframe运行现场的过程,请思考并回答这几个问题:
• 这里实现了一个支持类似于“异常重入”的机制,而在什么时候会出现这种“异常重入”?
• 内核为什么需要将异常的现场 Trapframe 复制到用户空间?
answer
- 当用户程序写入了一个
COW页,OS就会进入页写入异常的处理程序,最终调用用户态的pgfault函数进行处理。但是,如果在pgfault函数的处理过程中又写入了一个COW页,就会再次进入页写入异常处理程序,然后又调用pgfault函数……这就出现了”中断重入“的现象。
目前,pgfault函数的实现是不会出现中断重入的。因为在这个函数里,我们只对异常处理栈所在的页进行了读写(异常处理程序中的临时变量都保存在异常处理栈),而异常处理栈并非是父子进程共享的,不可能会有COW标志位。
支持”中断重入“可以使我们的程序有更好的可扩展性,使得用户程序可以根据需要注册自己的中断处理程序。如果内核不实现这个写入异常的重入的话,意味着用户处理函数甚至无法使用全局变量,这样就会有很大的局限性。 - 因为异常的处理是在用户态进行的,而用户态只能访问用户空间(低2G空间)内的数据,所以需要将现场保存在用户空间。
Thinking 4.8
Thinking 4.8
question
在用户态处理页写入异常,相比于在内核态处理有什么优势?
answer
尽量减少内核出现错误的可能,即使程序崩溃,也不会影响系统的稳定。同时微内核的模式下,用户态进行新页面的分配映射也更加灵活方便。
Thinking 4.9
question
请思考并回答以下几个问题:
• 为什么需要将 syscall_set_tlb_mod_entry 的调用放置在 syscall_exofork 之前?
• 如果放置在写时复制保护机制完成之后会有怎样的效果?
answer
- 其实
syscall_set_tlb_mod_entry并不一定要置在syscall_exofork之前, 只要放在“写时复制机制建立”之前即可。理由如下——
我们知道,在子进程真正运行之前,父进程会将需要与子进程共享的页面共享给子进程,并同时设置写时复制机制。在这个过程中,父进程数据段里的全局变量也就变成了子进程的全局变量,因此只要在此之前父进程的__pgfault_handler已经被赋值过,那么设置完写时复制机制之后,子进程中__pgfault_handler的值就同样被"赋值"了(和父进程保持一致)
因此,syscall_set_tlb_mod_entry必须在”写时复制机制“完成之前。syscall_set_tlb_mod_entry无论是放syscall_exofork之前还是之后,其实都没有问题。
但是如果非要问为什么”syscall_set_tlb_mod_entry的调用放置在syscall_exofork之前“,大概是因为,这样可以节省子进程的运行时间,因为子进程是在"syscall_exofork的执行刚刚从内核态返回用户态"的时候开始运行的。 - 通过上面的解释可以知道,如果将
syscall_set_tlb_mod_entry放置在写时复制保护机制完成之后,那么子进程中的全局变量__pgfault_handler就不会被赋值,那么页写入异常处理机制也就无法被建立起来。
lab_difficulties
掌握系统调用的概念及流程
系统调用的概念
在用户态下,用户进程不能访问系统的内核空间,也就是说它一般不能存取内核使用的内存数据,也不能调用内核函数,这一点是由体系结构保证的。然而,用户进程在特定的场景下往往需要执行一些只能由内核完成的操作,如操作硬件、动态分配内存,以及与其他进程进行通信等。允许在内核态执行用户程序提供的代码显然是不安全的,因此操作系统设计了一系列内核空间中的函数,当用户进程需要进行这些操作时,会引发特定的异常以陷入内核态,由内核调用对应的函数,从而安全地为用户进程提供受限的系统级操作,我们把这种机制称为系统调用。
系统调用的流程
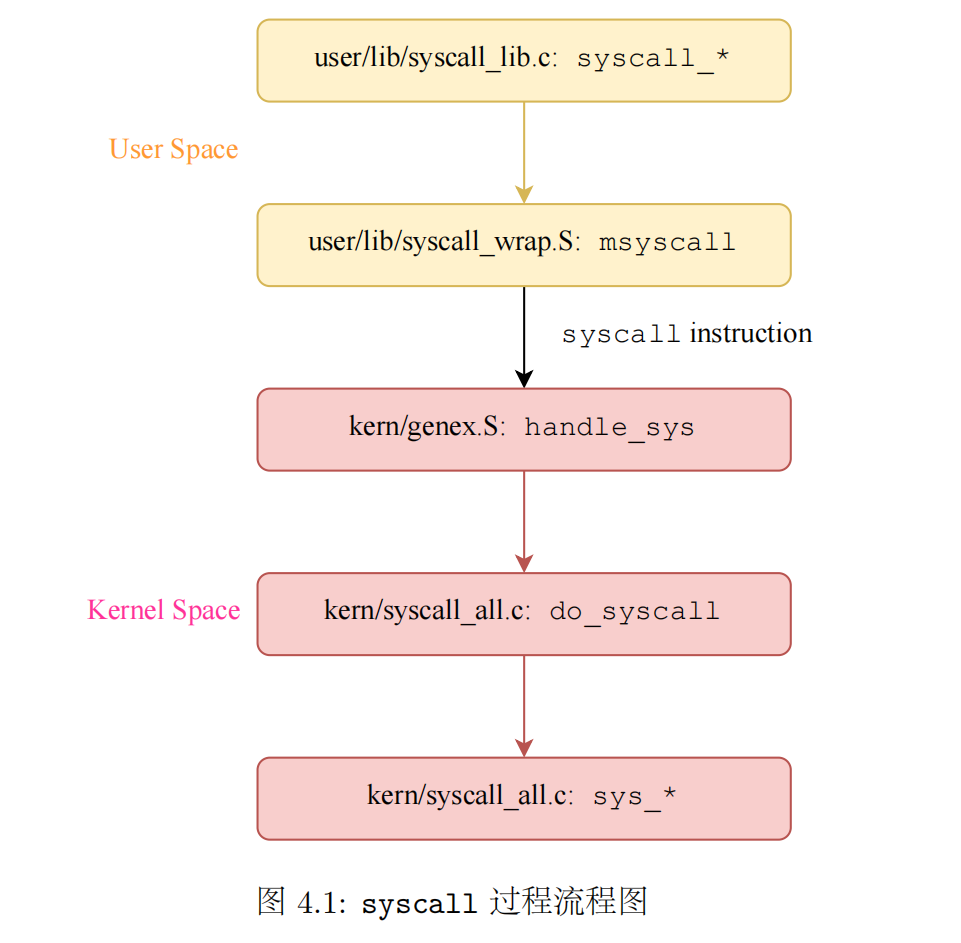
实现进程间通信机制
进程间通信机制 (IPC) 是微内核最重要的机制之一。
IPC 的目的是使两个进程之间可以通信
IPC 需要通过系统调用来实现
IPC 还与进程的数据、页面等信息有关
在进程控制块中我们看到了我们想要的内容:
| 参数 | 含义 |
|---|---|
| env_ipc_value | 进程传递的具体数值 |
| env_ipc_from | 发送方的进程 ID |
| env_ipc_recving | 1:等待接受数据中;0:不可接受数据 |
| env_ipc_dstva | 接收到的页面需要与自身的哪个虚拟页面完成映射 |
| env_ipc_perm | 传递的页面的权限位设置 |
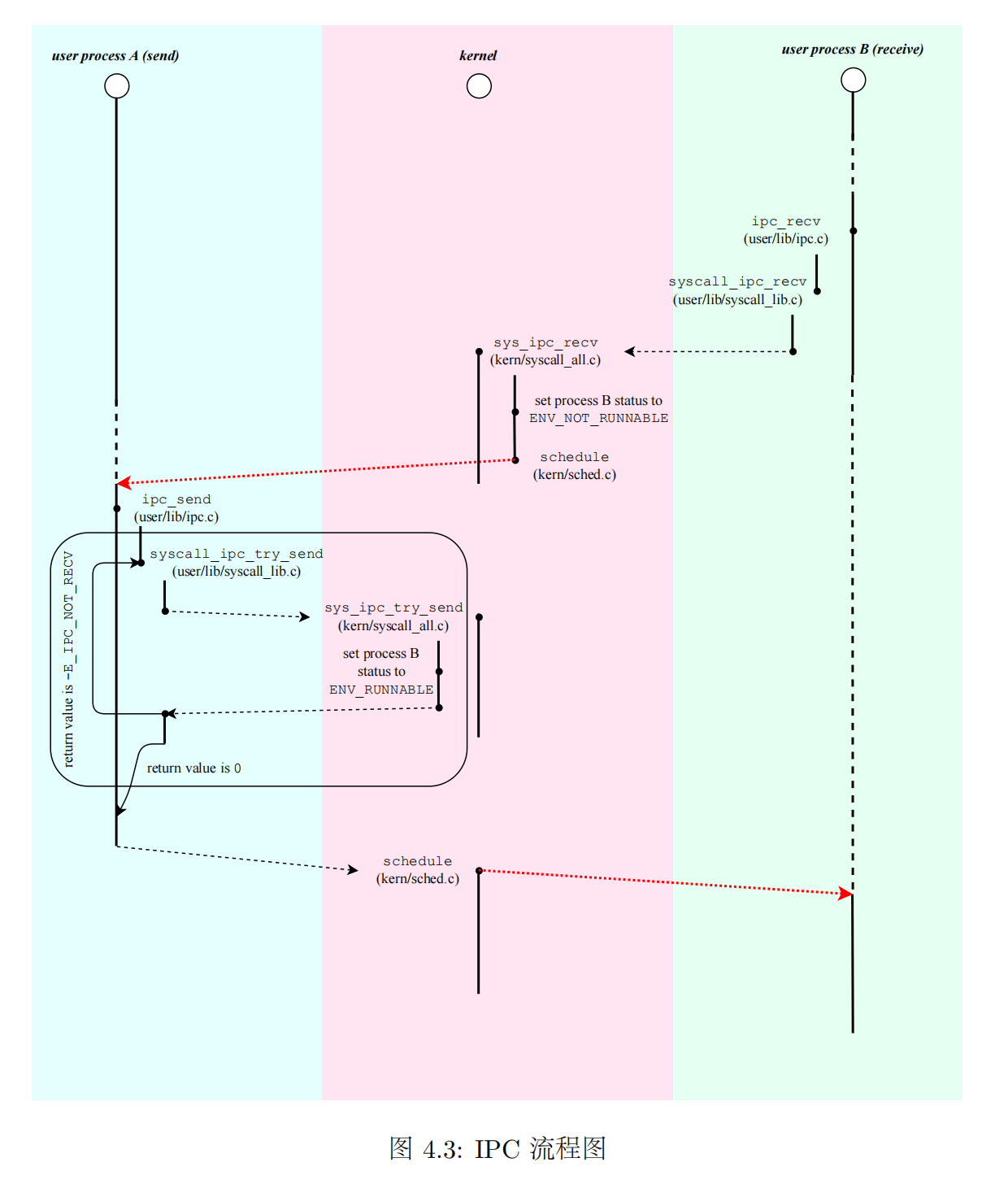
实现 fork 函数
在操作系统中,一个进程在调用 fork() 函数后,将从此分叉成为两个进程运行,其中新产生的进程称为原进程的子进程。在调用 fork 后,子进程会继承父进程地址空间中的代码段和数据段等内容。
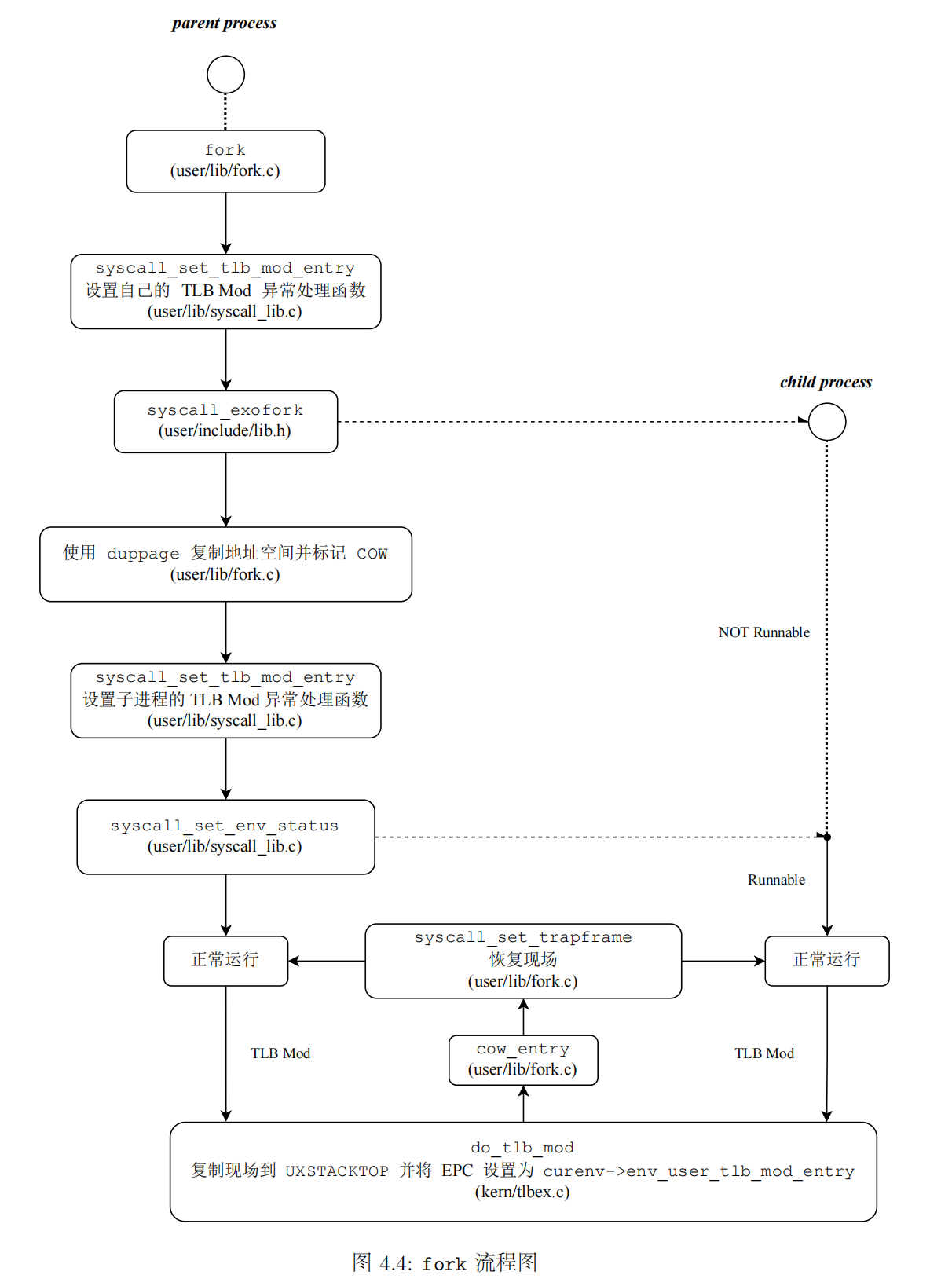
为了父子进程能够共用尽可能多的物理内存,我们希望引入一种写时复制(Copy-on-write,COW)机制。在 fork 时,我们只需将地址空间中的所有可写页标记为写时复制页面,使得在父进程或子进程对写时复制页面进行写入时,能够产生一种异常。操作系统在异常处理时,为当前进程试图写入的虚拟地址分配新的物理页面,并复制原页面的内容,最后再返回用户程序,对新分配的物理页面进行写入。这种机制使得我们可以最大限度的节省物理内存,减少了不必要的复制。
掌握页写入异常的处理流程
前文中我们提到了写时复制(COW)特性,这种特性也是依赖于异常处理的。当用户程序写入一个在 TLB 中被标记为不可写入(无 PTE_D)的页面时,MIPS 会陷入页写入异常(TLB Mod),我们在异常向量组中为其注册了一个处理函数 handle_mod,这一函数会跳转到 kern/tlbex.c中的 do_tlb_mod 函数中,这个函数正是处理页写入异常的内核函数。对于需要写时复制(COW)的页面,我们只需取消其 PTE_D 标记,即可在它们被写入时触发 do_tlb_mod 中的处理逻辑。
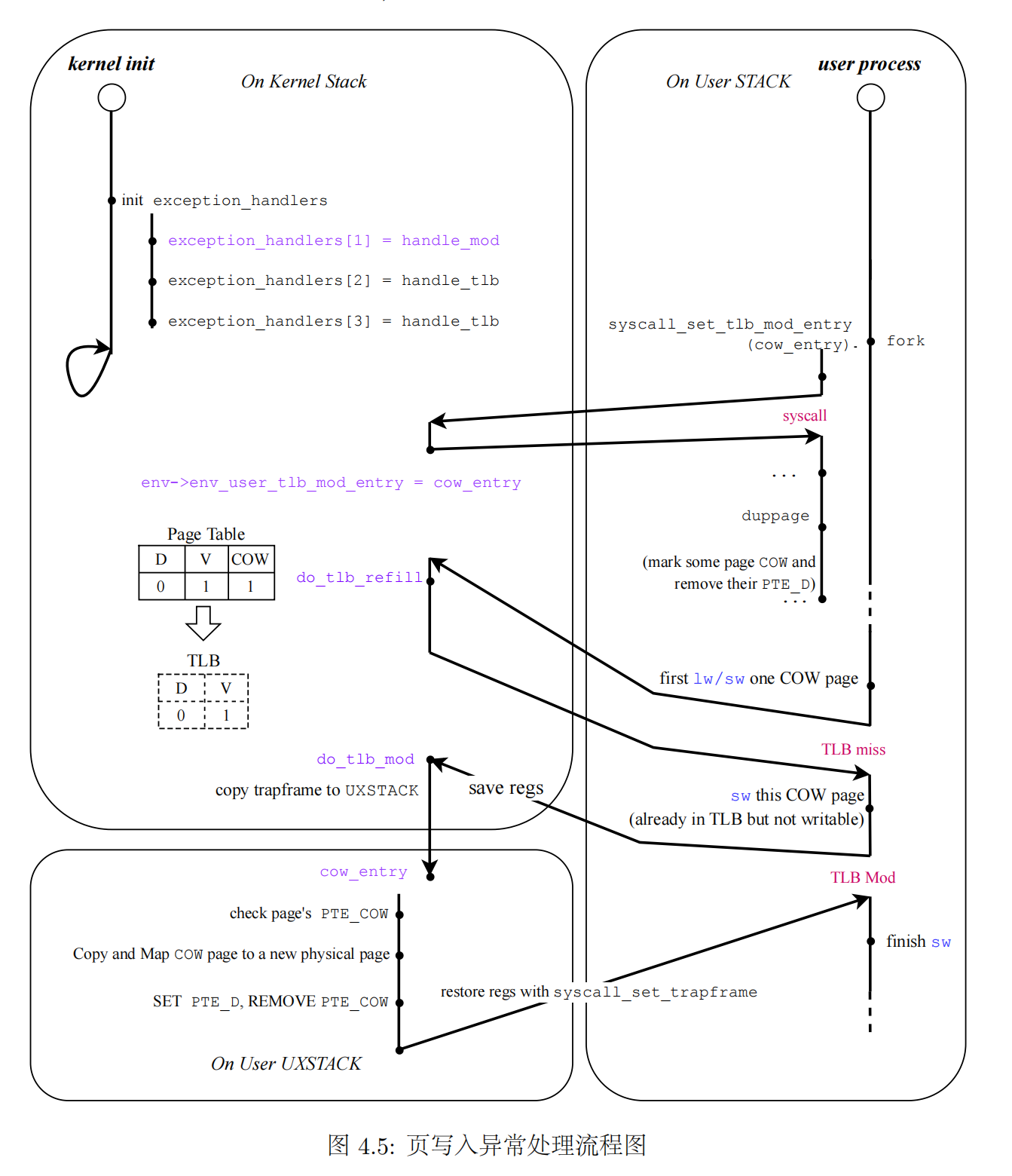
lab_summary
本lab相关函数速查:
| 函数 | 作用 |
|---|---|
| do_syscall | 系统调用函数 |
| sys_mem_alloc | 用户程序可以通过这个系统调用给该程序所允许的虚拟内存空间显式地分配实际的物理内存 |
| envid2env | 通过一个进程的 id 获取该进程控制块 |
| sys_mem_map | 将源进程地址空间中的相应内存映射到目标进程的相应地址空间的相应虚拟内存中去 |
| sys_mem_unmap | 解除某个进程地址空间虚拟内存和物理内存之间的映射关系 |
| sys_yield | 实现用户进程对 CPU 的放弃,从而调度其他的进程 |
| sys_ipc_recv(u_int dstva) | 接受消息 |
| sys_ipc_try_send(u_int envid, u_int value, u_int srcva, u_int perm) | 发送消息 |
| do_tlb_mod | 将当前现场保存在异常处理栈中,并设置 a0 和 EPC 寄存器的值,使得从异常恢复后能够以异常处理栈中保存的现场(Trapframe)为参数,跳转到env_user_tlb_mod_entry 域存储的用户异常处理函数的地址 |
| duppage | 父进程将地址空间中需要与子进程共享的页面映射给子进程 |
| fork() | 产生新进程 |
| syscall_exofork | 新进程的创建作为当前进程的子进程 |
| cow_entry | 写时复制处理的函数 |
| sys_set_tlb_mod_entry | 设置自己的 TLB Mod 异常处理函数 |
总结:
个人感觉这次实验的难度确实比Lab3高了很多,debug过程更是痛苦万分,主要有两方面原因——一方面,fork函数本身就不太好理解,需要同时考虑父子进程的行为逻辑;另一方面,本次填写的十几个函数彼此密切相关,无论哪一个出现了问题都会导致评测出锅,所以定位bug简直就是大海捞针。这次也渐渐显露出了OS隔几个lab出bug的非人类操作,我这次就成功找到了一个lab2的bug,虽然debug很痛苦,但是在这个过程中我又将代码重读了很多遍,对代码理解也更加深刻了。
- Title: lab4_report
- Author: Charles
- Created at : 2023-04-12 13:02:47
- Updated at : 2023-11-05 21:36:18
- Link: https://charles2530.github.io/2023/04/12/lab4-report/
- License: This work is licensed under CC BY-NC-SA 4.0.

