
lab6_report
lab6_report
lab_thinkings
Thinking 6.1
question
示例代码中,父进程操作管道的写端,子进程操作管道的读端。如果现在想让父进程作为“读者”,代码应当如何修改?
answer
只需要调换父子进程操作的内容即可——
1 | int main() { |
Thinking 6.2
question
上面这种不同步修改 pp_ref 而导致的进程竞争问题在 user/lib/fd.c 中的 dup 函数中也存在。请结合代码模仿上述情景,分析一下我们的 dup 函数中为什么会出现预想之外的情况?
answer
dup函数的作用时将oldfdnum所代表的文件描述符的指向的数据完全复制给newfdnum文件描述符,一共包含两个过程——
- 将
newfd所在的虚拟页映射到oldfd所在的物理页 - 将
newfd的数据所在的虚拟页映射到oldfd的数据所在的物理页
考虑如下代码段
1 | // 子进程 |
分析过程如下:
- fork结束后,子进程先进行。但是在
read之前发生了时钟中断,此时父进程开始进行进行。 - 父进程在
dup(p[0])中,已经完成了对p[0]的映射,这个时候发生了中断,还没有来得及完成对pipe的映射。 - 此时回到子进程,进入
read函数,结果发现ref(p[0]) == ref(pipe) == 2, 认为此时写进程关闭。
Thinking 6.3
question
阅读上述材料并思考:为什么系统调用一定是原子操作呢?如果你觉得不是所有的系统调用都是原子操作,请给出反例。希望能结合相关代码进行分析说明。
answer
在 syscall 对应的异常处理程序 handle_sys 中,我们使用了汇编宏 CLI 来禁用全局中断,因此系统调用时不会被中断,是原子操作。
1 | NESTED(handle_sys,TF_SIZE, sp) |
Thinking 6.4
question
仔细阅读上面这段话,并思考下列问题
按照上述说法控制 pipe_close 中 fd 和 pipe unmap 的顺序,是否可以解决上述场景的进程竞争问题?给出你的分析过程。
我们只分析了 close 时的情形,在 fd.c 中有一个 dup 函数,用于复制文件内容。试想,如果要复制的是一个管道,那么是否会出现与 close 类似的问题?请模仿上述材料写写你的理解。
answer
分析如下
- 可以解决。由于
ref(p[0])始终小于ref(pipe), 因此如果先解除p[0]的映射,则ref(p[0])更要小于ref(pipe),永远不会出现ref(p[0]) == ref(pipe)。 dup函数也会出现与close类似的问题,pipe的引用次数总比fd要高。当管道的dup进行到一半时, 若先映射fd,再映射pipe,就会使得fd的引用次数的+1先于pipe。这就导致在两个map的间隙,会出现pageref(pipe) == pageref(fd)的情况。这个问题也可以通过调换两个map的顺序来解决。
Thinking 6.5
question
思考以下三个问题。
认真回看 Lab5 文件系统相关代码,弄清打开文件的过程。
回顾 Lab1 与 Lab3,思考如何读取并加载 ELF 文件。
在 Lab1 中我们介绍了 data text bss 段及它们的含义,data 段存放初始化过的全局变量,bss 段存放未初始化的全局变量。关于 memsize 和 filesize ,我们在 Note1.3.4中也解释了它们的含义与特点。关于 Note 1.3.4,注意其中关于“bss 段并不在文件中占数据”表述的含义。回顾 Lab3 并思考:elf_load_seg() 和 load_icode_mapper()函数是如何确保加载 ELF 文件时,bss 段数据被正确加载进虚拟内存空间。bss 段在 ELF 中并不占空间,但 ELF 加载进内存后,bss 段的数据占据了空间,并且初始值都是 0。请回顾 elf_load_seg() 和 load_icode_mapper() 的实现,思考这一点是如何实现的?
下面给出一些对于上述问题的提示,以便大家更好地把握加载内核进程和加载用户进程的区别与联系,类比完成 spawn 函数。
关于第一个问题,在 Lab3 中我们创建进程,并且通过 ENV_CREATE(…) 在内核态加载了初始进程,而我们的 spawn 函数则是通过和文件系统交互,取得文件描述块,进而找到 ELF 在“硬盘”中的位置,进而读取。
关于第二个问题,各位已经在 Lab3 中填写了 load_icode 函数,实现了 ELF 可执行文件中读取数据并加载到内存空间,其中通过调用 elf_load_seg 函数来加载各个程序段。在 Lab3 中我们要填写 load_icode_mapper 回调函数,在内核态下加载 ELF 数据到内存空间;相应地,在 Lab6 中 spawn 函数也需要在用户态下使用系统调用为 ELF 数据分配空间。
answer
对于bss段中和text&data段共同占据一个页面的部分,就使用memset将这一部分置零;对于bss段其它部分,仅使用syscall_mem_malloc分配页面而不映射到任何内容。
Thinking 6.6
question
通过阅读代码空白段的注释我们知道,将文件复制给标准输入或输出,需要我们将其 dup 到 0 或 1 号文件描述符 (fd)。那么问题来了:在哪步,0 和 1 被“安排”为标准输入和标准输出?请分析代码执行流程,给出答案。
answer
在init.c的umain函数中将0和1分别被设置为了标准输入和标准输出。相关代码如下
1 | //将0关闭,随后使用opencons函数打开的文件描述符编号就被设置为零为0 |
Thinking 6.7
question
在 shell 中执行的命令分为内置命令和外部命令。在执行内置命令时 shell 不需要 fork 一个子 shell,如 Linux 系统中的 cd 命令。在执行外部命令时 shell 需要 fork一个子 shell,然后子 shell 去执行这条命令。
据此判断,在 MOS 中我们用到的 shell 命令是内置命令还是外部命令?请思考为什么Linux 的 cd 命令是内部命令而不是外部命令?
answer
分析如下
- shell命令是外部命令,因为在执行shell命令时,当前进程通过
fork产生一个子进程,也就是子shell,然后这个子shell来运行该命令所对应的可执行文件。 - linux中的内部命令实际上是shell程序的一部分,其中包含的是一些比较简单的linux系统命令,这些命令由shell程序识别并在shell程序内部完成运行,通常在linux系统加载运行时shell就被加载并驻留在系统内存中。因为
cd指令非常简单,将其作为内部命令写在bash源码里面的,可以避免每次执行都需要fork并加载程序,提高执行效率。
Thinking 6.8
question
在你的 shell 中输入命令 ls.b | cat.b > motd。
请问你可以在你的 shell 中观察到几次 spawn ?分别对应哪个进程?
请问你可以在你的 shell 中观察到几次进程销毁?分别对应哪个进程?
answer
通过增加调试信息可以看出
- shell中进行了2次
spawn,这两次生成的子进程分别用于执行ls.b和cat.b - shell中进行了2次进程销毁,这2个进程分别是shell执行
ls.b和cat.b时通过spawn生成的子进程。
lab_difficulties
管道的相关操作
管道是一种典型的进程间单向通信的方式。管道分有名管道和匿名管道两种,匿名管道只能在具有公共祖先的进程之间使用,且通常使用在父子进程之间。
父子进程之间通信的基本用法:父进程在 pipe 函数之后,调用fork 来产生一个子进程,之后在父子进程中各自执行不同的操作:关掉自己不会用到的管道端,然后进行相应的读写操作。
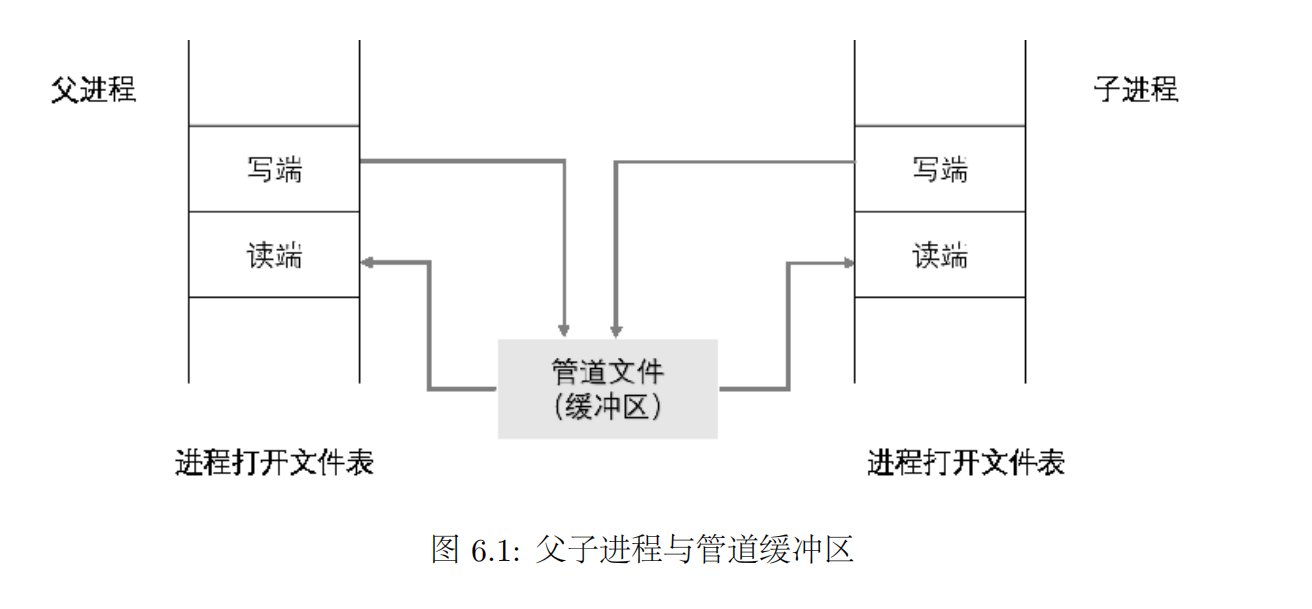
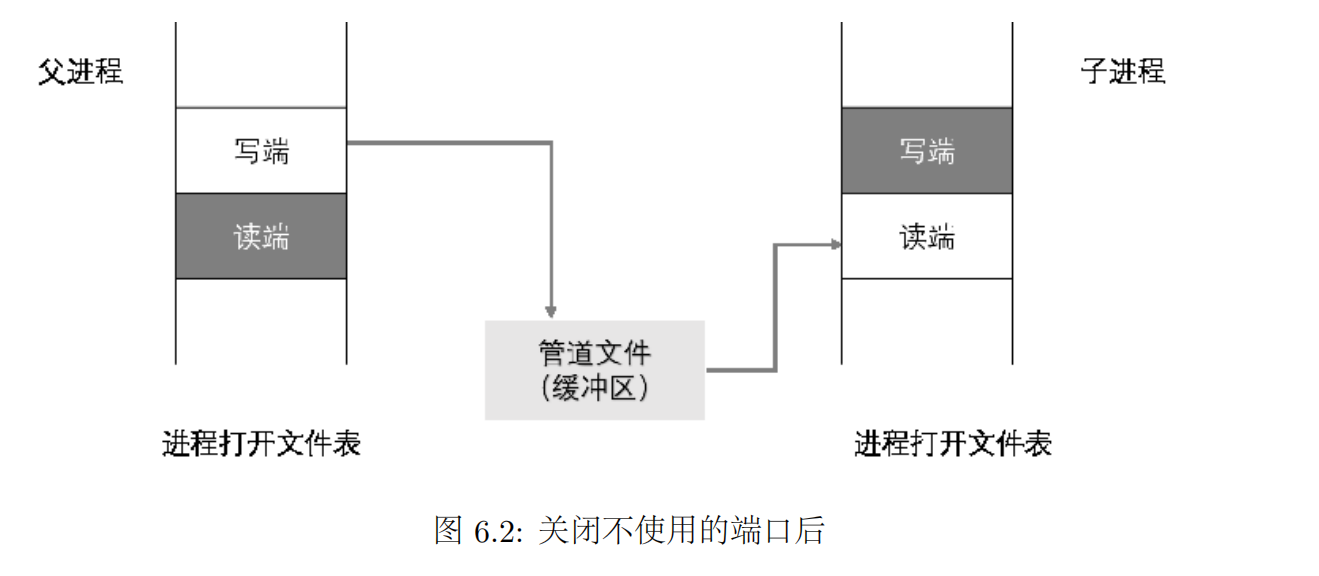
shell的相关操作
在计算机科学中,shell 是指“为使用者提供操作界面”的软件(命令解析器)。它接收用户命令,然后调用相应的应用程序。
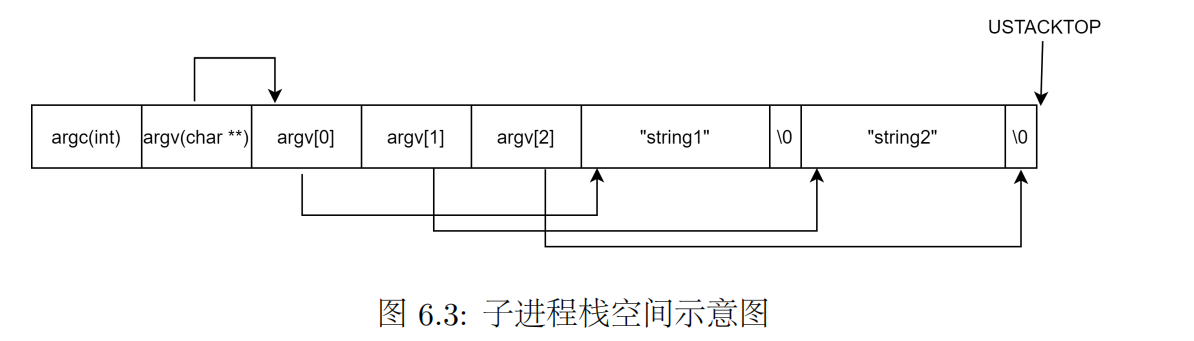
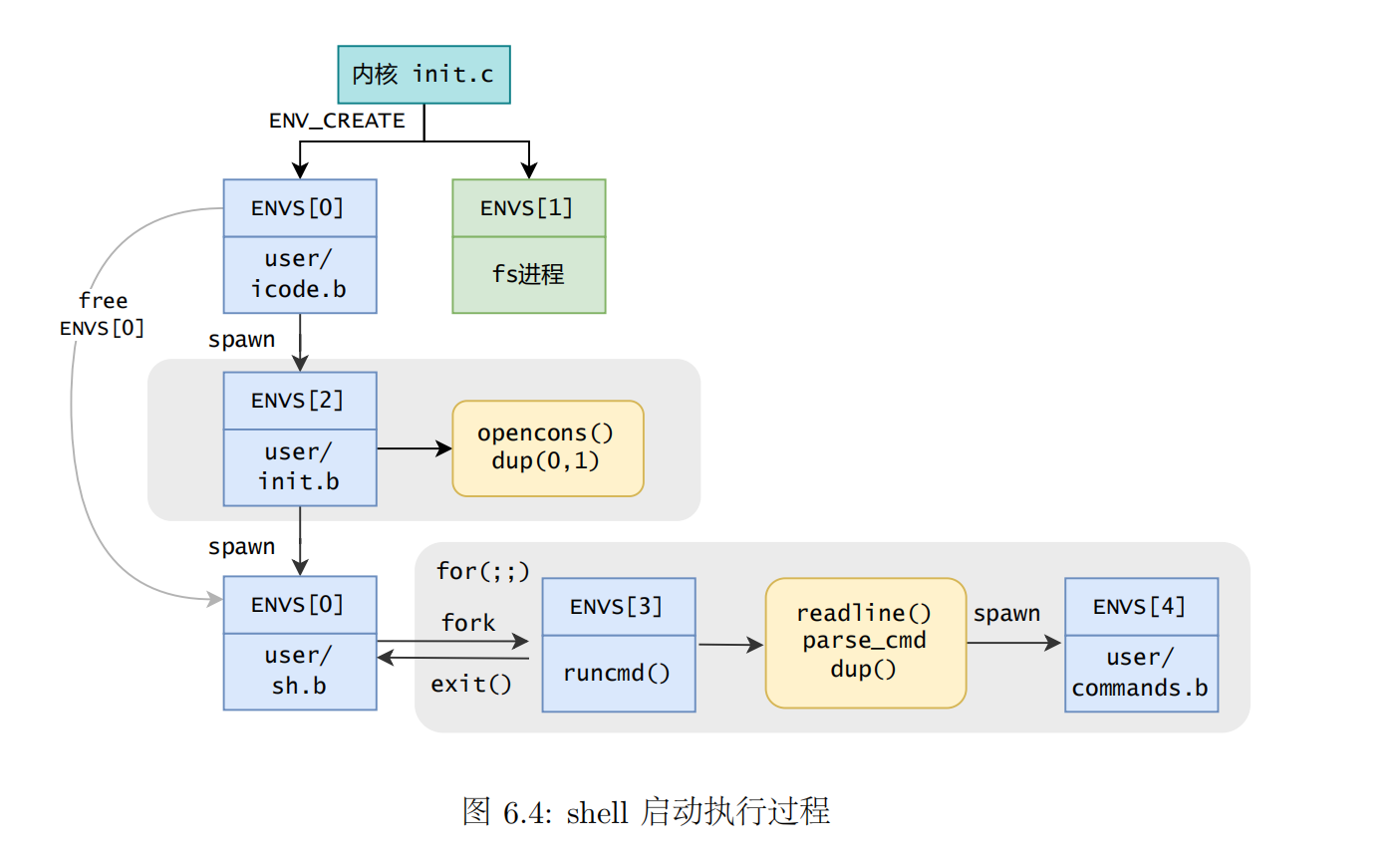
lab_summary
本lab相关函数速查
| 函数 | 作用 |
|---|---|
| pipe(int fd[2]) | 成功创建管道返回 0,参数中的 fd用来保存读写端的文件描述符,fd[0] 对应读端,fd[1] 对应写端 |
| pageref | 得到页的引用次数 |
| _pipe_is_closed | 用于管道另一端关闭的判断一定返回正确的结果 |
| pipe_read | 是从 fd 对应的管道数据缓冲区中,读取至多 n 字节到 vbuf 对应的虚拟地址中,并返回本次读到的字节数 |
| pipe_write | 从 vbuf 对应的虚拟地址,向 fd 对应的管道数据缓冲区中写入 n 字节,并返回本次写入的字节数 |
| pipe_close | 关闭管道的一端 |
| spawn | 帮助我们调用文件系统中的可执行文件并执行(这个函数与 fork 函数类似,其最终效果都是产生一个子进程,不过与 fork 函数不同的是,spawn 函数产生的子进程不再执行与父进程相同的程序,而是装载新的 ELF 文件,执行新的程序。) |
| readline | 从标准输入(控制台),读入一行用户读入的命令,保存在 char* buf 中 |
| gettoken | 接收 readline 读入的命令字符串作为传入参数 char* s。这个两个函数的作用是将命令字符串分割,提取命令中基本单元——特殊符号或单词,并过滤空白字符 |
| parsecmd | 解析用户输入的命令 |
| init_stack | 初始化子进程的栈空间,达到向子进程的主函数传递参数的目的 |
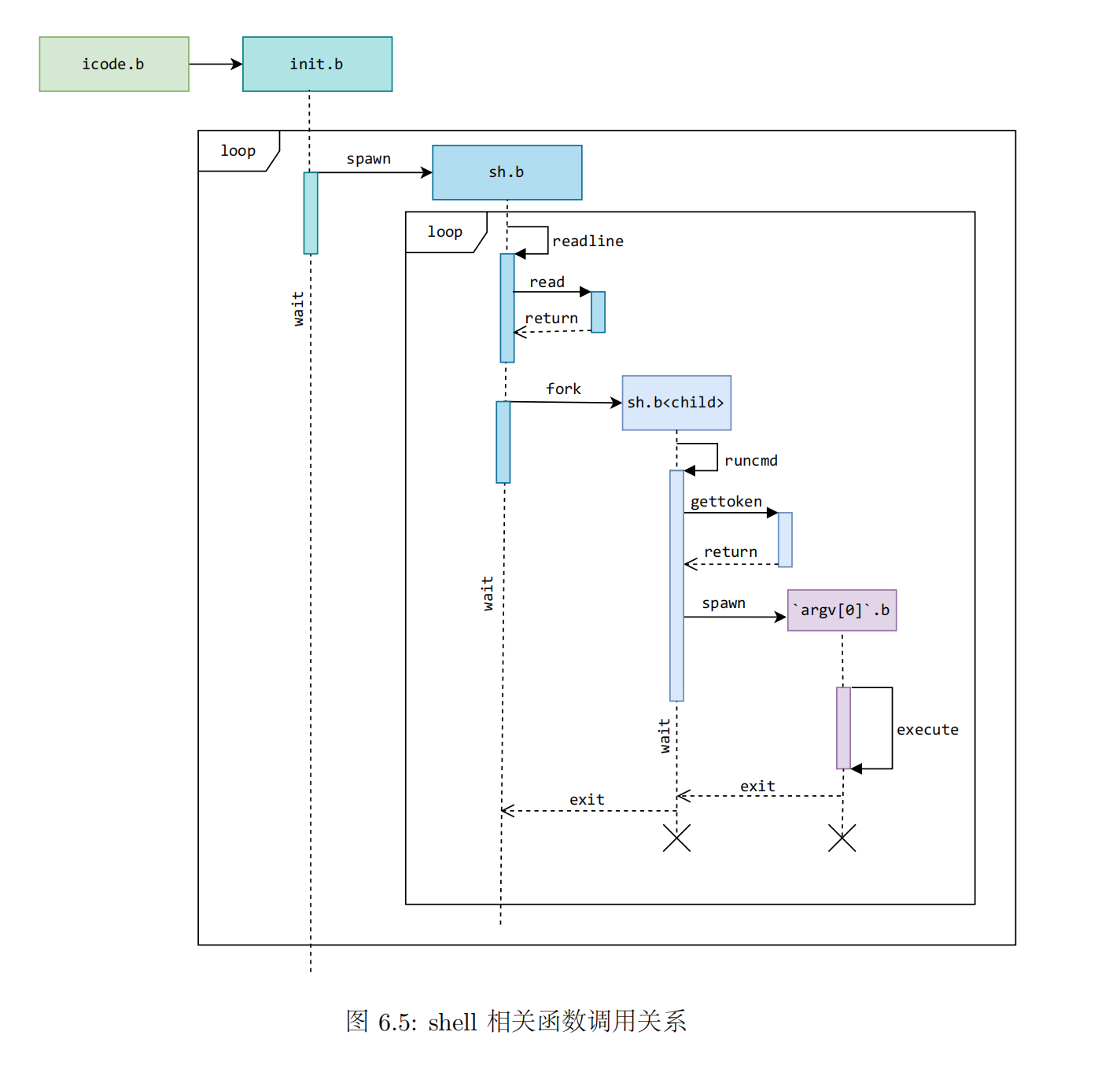
总结:
Lab6要求我们完成pipe机制和实现一个简单的shell,实验任务比较简单。OS实验课总算是告一段落了,通过自己动手实现一个简单的操作系统,不仅让我们收获了很多成就感,同时也让我们对理论课知识有了更深刻的理解。
- Title: lab6_report
- Author: Charles
- Created at : 2023-05-18 20:38:54
- Updated at : 2026-05-11 20:11:18
- Link: https://charles2530.github.io/2023/05/18/lab6-report/
- License: This work is licensed under CC BY-NC-SA 4.0.