
CUDA_note_1
CUDA定义与介绍
介绍CUDA
CUDA is a compiler and toolkit for programming NVIDIA GPUs
CUDA(Compute Unified Device Architecture) 统一计算设备架构是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,基于CUDA编程可以利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。近年来,GPU最成功的一个应用就是深度学习领域,基于GPU的并行计算已经成为训练深度学习模型的标配。
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)。
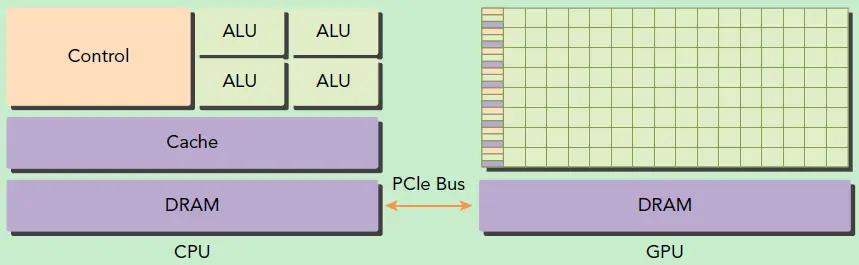
可以看到GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。
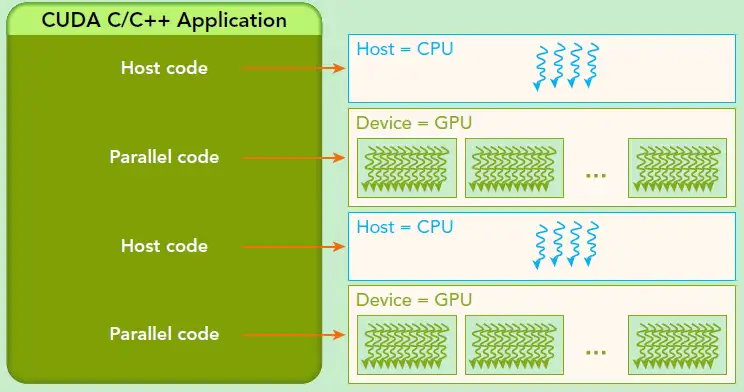
CUDA是NVIDIA公司所开发的GPU编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序。CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言,这里我们选择CUDA C/C++接口对CUDA编程进行讲解。

统一计算设备架构的软件堆栈
CUDA 软件堆栈由几层组成,一个硬件驱动程序,一个应用程序编程接口(API)和它的Runtime, 还有二个高级的通用数学库,CUFFT 和CUBLAS。硬件被设计成支持轻量级的驱动和Runtime 层面,因而提高性能。
“聚集”和“发散”内存操作
CUDA API 更像是C 语言的扩展,以便最小化学习的时间。CUDA 提供一般DRAM 内存寻址方式:“发散” 和“聚集”内存操作,从而提供最大的编程灵活性。从编程的观点来看,它可以在DRAM的任何区域进行读写数据的操作,就像在CPU 上一样。
共享内存使数据更接近ALU
CUDA 允许并行数据缓冲或者在On-chip 内存共享,可以进行快速的常规读写存取,在线程之间共享数据。应用程序可以最小化数据到DRAM 的overfetch 和round-trips ,从而减少对DRAM 内存带宽的依赖。
GPU硬件基础
GPU硬件结构
GPU实际上是一个SM的阵列,每个SM包含N个计算核,现在我们的常用GPU中这个数量一般为 128或192。一个GPU设备中包含一个或多个SM,这是处理器具有可扩展性的关键因素。如果向设备中增加更多的SM,GPU就可以在同一时刻处理更多的任务,或者对于同一任务,如果有足够的并行性的话,GPU可以更快完成它。
SM(Streaming Multi-Processor),又称流式多处理器——NVIDIA Fermi架构GPU中处理Shader指令的硬件单元。一个SM中会包含多个计算核心、Control Flow Unit、L/S Unit、Register、Shared Memory等硬件单元。
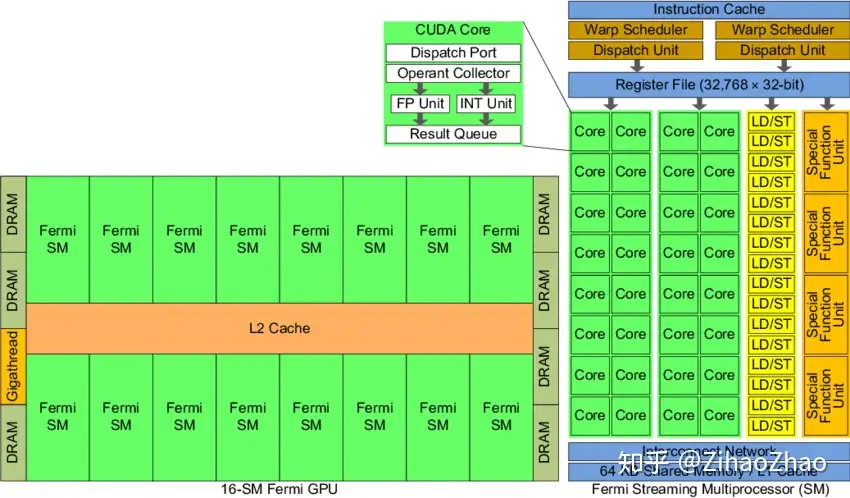
左边是GPU的整体结构,其主要是由大量的SM(Streaming-Multiprocessor)和DRAM存储等构成的。右图是对单个SM进行放大,可以看到SM由大量计算核(有时也称SP或CUDA核)、 LDU(Load-Store Units)、SFU(Special-Function Units)、寄存器、共享内存等构成。这种结构正是GPU具有高并行度计算能力的基础。通过一定的层级结构组织大量计算核,并给各级都配有相应的内存系统,GPU获得了出色的计算能力。
其中流式多处理器(SM)是GPU架构的核心。GPU中的每一个SM都能支持数百个线程并发执行,每个GPU通常有多个SM,所以在一个GPU上并发执行数千个线程是有可能的。当启动一个内核网络时,它的线程块会被分布在可用的SM上来执行。当线程块一旦被调度到一个SM上,其中的线程只会在那个指定的SM上并发执行。多个线程块可能会被分配到同一个SM上,而且是根据SM资源的可用性进行调度的。
软硬件组织结构对比
在SM中,共享内存和寄存器是非常重要的资源。共享内存被分配在SM上的常驻线程块中,寄存器在线程中被分配。线程块中的线程通过这些资源可以进行相互的合作和通信。尽管线程块里的所有线程都可以逻辑地并行运行,但并不是所有线程都可以同时在物理层面执行。因此线程块里的不同线程可能会以不同速度前进。我们可以使用CUDA语句在需要的时候进行线程的同步。
尽管线程块里的线程束可以任意顺序调度,但活跃的线程束数量还是会由SM的资源所限制。当线程数由于任何理由闲置的时候(比如等待从设备内存中读取数值)这时SM可以从同一SM上的常驻 线程块中调度其他可用的线程束。在并发的线程束间切换并没有额外开销,因为硬件资源已经被分配到了SM上的所有线程和线程块中。这种策略有效地帮助GPU隐藏了访存的延时,因为随时有大量线程束可供调度,理想状态下计算核将一直处于忙碌状态,从而可以获得很高的吞吐量。
SM是GPU架构的核心,而寄存器和共享内存是SM中的稀缺资源。CUDA将这些资源分配到SM中的所有常驻线程里。因此,这些有限的资源限制了在SM上活跃的线程束数量,而活跃的线程束数量对应于SM上的并行量。
参考资料
[1]. CUDA编程入门极简教程 - 知乎 (zhihu.com)
[2]. 人工智能编程 | 谭升的博客 (face2ai.com)
[3]. CUDA C++ Programming Guide
- Title: CUDA_note_1
- Author: Charles
- Created at : 2023-07-17 20:07:41
- Updated at : 2026-05-11 20:11:11
- Link: https://charles2530.github.io/2023/07/17/cuda-note-1/
- License: This work is licensed under CC BY-NC-SA 4.0.