
compiler-theory-3
语义分析、生成中间代码
- 任务:对识别出的各种语法成分进行语义分析,并产生相应的中间代码。
1、上下文有关分析:即标识符的作用域 (Scope)
2、类型的一致性检查 (Type Checking)
3、语义处理:
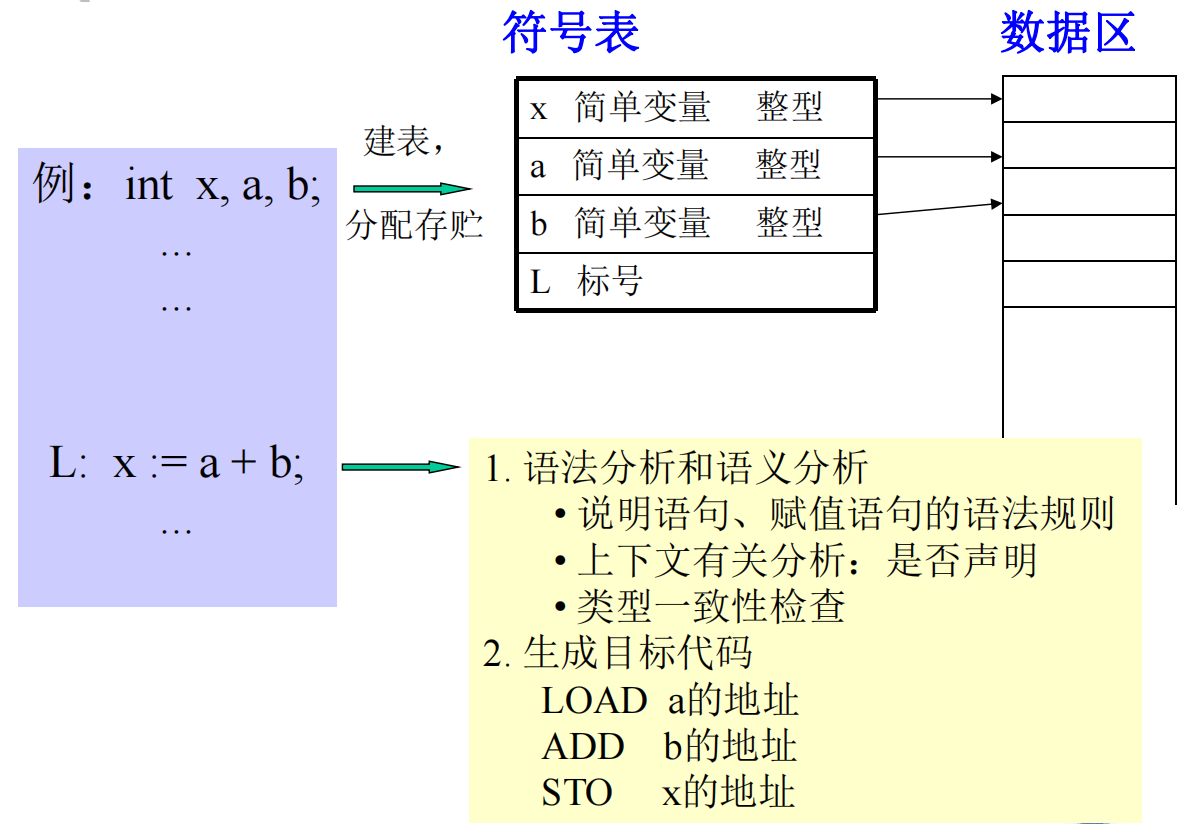
声明语句:其语义是声明变量的类型等,并不要求做其他的操作。编译程序的工作是填符号表,登录名字的特征信息,分配存储。
执行语句:语义是要做某种操作。语义处理的任务:按某种操作的目标结构生成代码。
用上下文无关文法只能描述语言的语法结构,而不能描述其语义。
符号表
-
符号表的定义:在编译过程中,编译程序用来记录源程序中各种名字的特性信息, 所以也称为名字特性表。
- 名字: 程序名、过程名、函数名、用户定义类型名、变量名、常量名、枚举值名、标号名等。
- 特性信息: 上述名字的种类、类型、维数、参数个数、数值及目标地址(存储单元地址)等。
-
建表和查表的必要性(符号表在编译过程中的作用):
- 源程序中变量要先声明,再引用。
- 用户通过声明语句,声明各种名字,并给出它们的类型、维数等信息
- 编译程序在处理这些声明语句时,将声 明中的名字及其信息登录到符号表中,同时给变量分配存储单元,并将储单元地址登录在符号表中。
- 当编译程序编译到引用所声明的变量时(赋值或引用其值),要进行语法语义正确性检查(类型是否符合要求)和生成相应的目标程序,这就需要查符号表以取得相关信息。
- 源程序中变量要先声明,再引用。
-
有关符号表的操作:填表和查表
-
填表:当分析到程序中的说明或定义语句时,将说明或定义的名字,以及与之有关的信息填入符号表中。
-
查表:(1) 填表前查表,检查在程序的同一作用域内名字是否重复定义;
(2) 检查名字的种类是否与说明一致;
(3) 对于强类型语言,要检查表达式中各变量的类型是否一致;
(4) 生成目标指令时,要取得所需要的地址。
-
-
符号表的结构与内容
-
符号表的基本结构:

-
“名字”域: 存放名字,一般为标识符的符号串,也可为指向标识符字符串的指针。
-
“特性”域: 可包括多个子域 , 分别表示标识符的有关信息,如:
- 名字(标识符)的种类:简单变量、函数、过程、数组、标号、参数等
- 类型:如整型、浮点型、字符型、指针等
- 性质:变量形参、值形参等
- 值: 常量名所代表的数值
- 地址:变量所分配单元的首址或地址位移
- 大小:所占的字节数
- 作用域的嵌套层次:
- 对于数组: 维数、上下界值、计算下标变量地址所用的信息(数组信息向量)以及数组元素类型等。
- 对于记录(结构、联合):域的个数,每个域的域名、地址位移、类型等。
- 对于过程或函数:形参个数、所在层次、函数返回值类型、局部变量所占空间大小等。
- 对于指针:所指对象类型等。
-
-
符号表的组织方式
- 统一符号表:不论什么名字都填入统一格式的符号表中
- 符号表表项应按信息量最大的名字设计,填表、查表比较方便, 结构简单, 但是浪费大量空间。
- 对于不同种类的名字分别建立各种符号表
- 节省空间, 但是填表和查表不方便。
- 折中办法:大部分共同信息组成统一格式的符号表,特殊信息另设附表,两者用指针连接。
- 统一符号表:不论什么名字都填入统一格式的符号表中


非分程序的符号表
- 非分程序结构语言: 每个可独立进行编译的程序单元是一个不包含有子模块的单一模块,如FORTRAN语言。

-
标识符的作用域及基本处理办法
-
作用域:
- 全局:子程序名,函数名和公共区名。
- 局部: 程序单元中定义的变量。
-
符号表的组织:
graph TD A(全局符号表)-->B(局部符号表)
-
基本处理办法:
<1> 子程序、函数名和公共区名填入全局符号表。
<2> 在子程序(函数)声明部分读到标识符,造局部符号表。
查本程序单元局部符号表有无同名?有则重复声明,报错,无则造表。
<3> 在语句部分读到标识符,查表
查本程序单元局部符号表,有无同名?有,即已声明。无则查全局变量表,然后重复全局符号表流程。
-
程序单元结束: 释放该程序单元的局部符号表。
-
程序编译完成: 释放全部符号表。
-
-
符号表的组织方式
- 无序符号表: 按扫描顺序建表,查表要逐项查找
- 查表操作的平均长度为${n+1}/2$
- 有序符号表:符号表按变量名进行字典式排序
- 线性查表: n+1 / 2
- 折半查表: $\log_2^n-1$
- 散列符号表(Hash表):符号表地址 = Hash(标识符)
- 无序符号表: 按扫描顺序建表,查表要逐项查找
-
处理作用域嵌套
- 作用域:标识符局部于所定义的模块(最小模块)
- 基本处理办法:建查符号表均要遵循标识符的作用域规定进行。
栈式符号表
-
运行时的存储组织及管理
- 目标程序运行时所需存储空间的组织与管理以及源程序中变量存储空间的分配。
-
静态存储分配和动态存储分配
-
静态存储分配:在编译阶段由编译程序实现对存储空间的管理和为源程序中的变量分配存储的方法。
- 条件:如果在编译时能够确定源程序中变量在运行时的数据空间大小,且运行时不改变,那么就可以采用静态存储分配方法。
但是并不是所有数据空间大小都能在编译过程中确定
-
分配策略
由于每个变量所需空间的大小在编译时已知,因此可以用简单的方法给变量分配目标地址。
-
开辟一数据区。(首地址在加载时定)
-
按编译顺序给每个模块分配存储空间。
-
在模块内部按顺序给模块的变量分配存储,一般用相对地址,所占数据区的大小由变量类型决定。
-
目标地址填入变量的符号表中。
-
-
动态存储分配:在目标程序运行阶段由目标程序实现对存储空间的组织与管理,和为源程序中的变量分配存储的方法。
-
特 点
-
在目标程序运行时进行变量的存储分配。
-
编译时要生成进行动态分配的目标指令。
-
编译时不能具体确定程序所需数据空间,实际上的分配要在目标程序运行时进行
-
-
分配策略: 整个数据区为一个堆栈,
(1) 当进入一个过程时,在栈顶为其分配一个数据区。
(2) 退出时,撤消过程数据区。
-
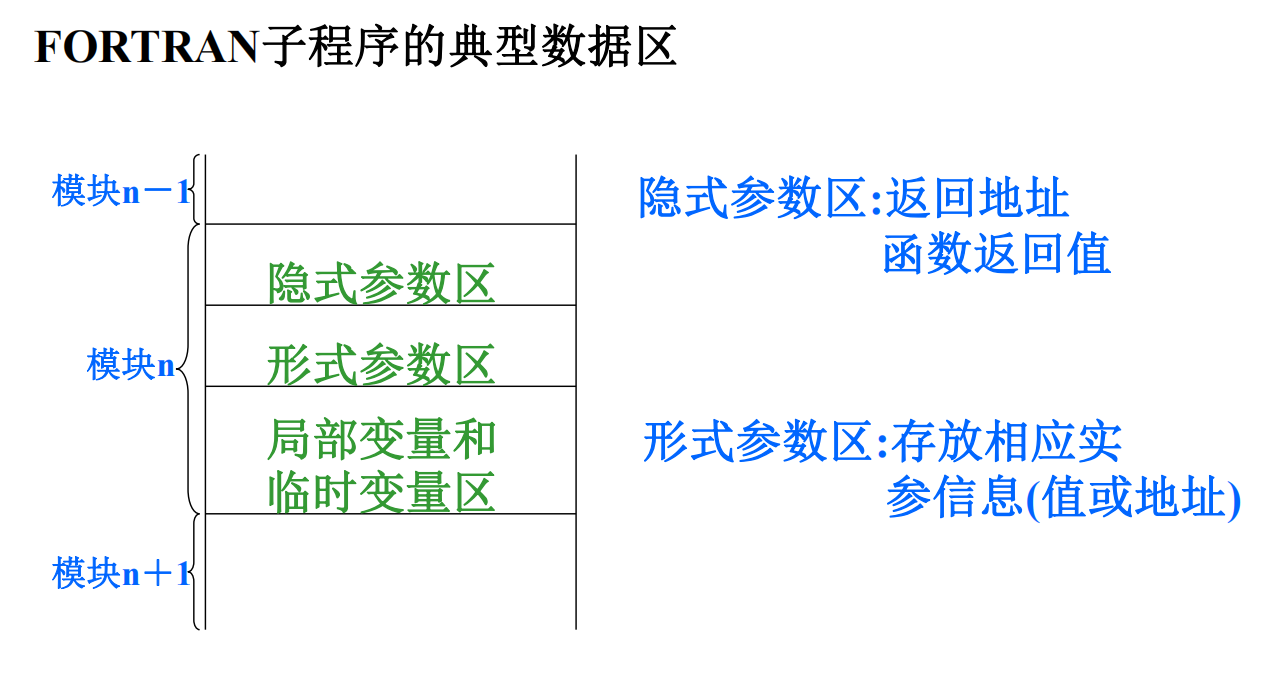
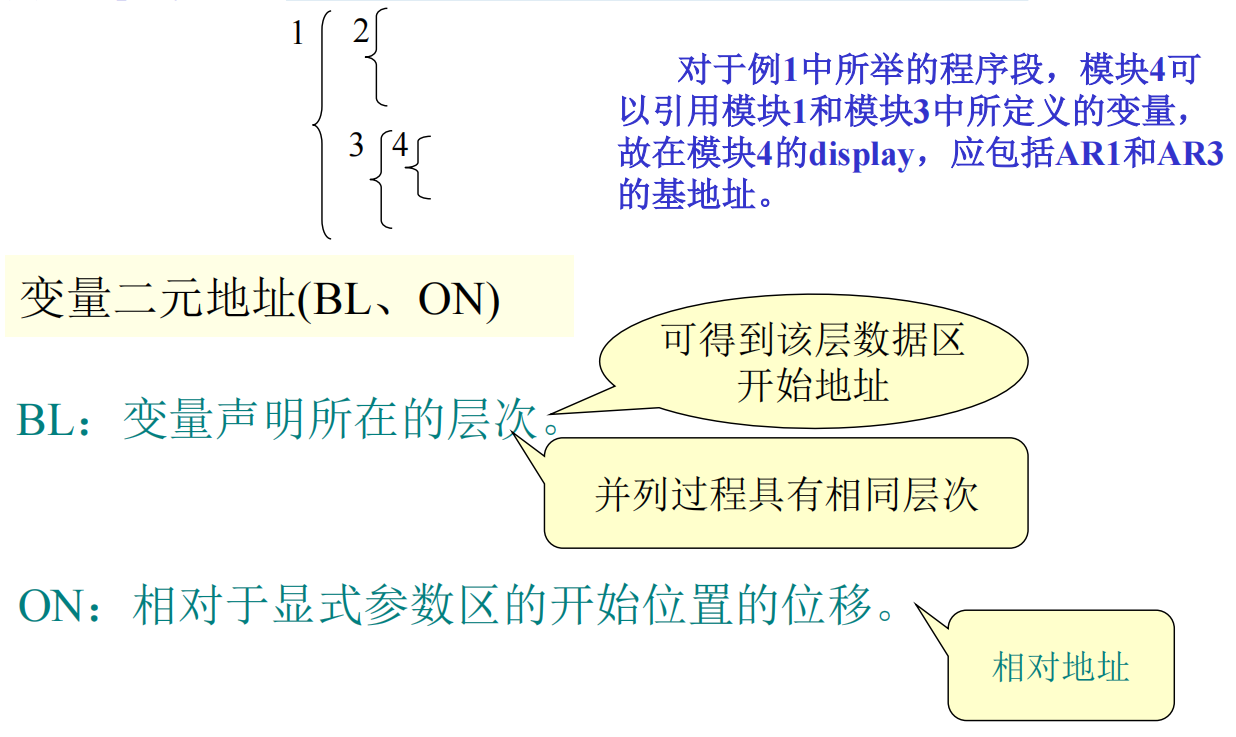
活动记录
- 局部数据区:存放模块中定义的各个局部变量。
- 参数区: 存放隐式参数和显式参数。
- display区:存放各外层模块活动记录的基地址。
-
-
运行时的存储组织及管理
运行时的存储组织及管理:目标程序运行时所需存储空间的组织与管理以及源程序中变量存储空间的分配。
静态存储分配
-
静态存储分配
- 定义:在编译阶段由编译程序实现对存储空间的管理和为源程序中的变量分配存储的方法。
- 条件:如果在编译时能够确定源程序中变量在运行时的数据空间大小,且运行时不改变,那么就可以采用静态存储分配方法。
但是并不是所有数据空间大小都能在编译过程中确定
-
分配策略
-
由于每个变量所需空间的大小在编译时已知,因此可以用简单的方法给变量分配目标地址。
-
开辟一数据区。(首地址在加载时定)
-
按编译顺序给每个模块分配存储空间。
-
在模块内部按顺序给模块的变量分配存储,一般用相对地址,所占数据区的大小由变量类型决定。
-
目标地址填入变量的符号表中。
-
-
-
模块(FORTRAN子程序)的完整数据区
- 变量
- 返回地址
- 形式参数
- 临时变量
动态存储分配
-
动态存储分配
- 定义: 在目标程序运行阶段由目标程序实现对存储空间的组织与管理,和为源程序中的变量分配存储的方法。
- 特点:
- 在目标程序运行时进行变量的存储分配。
- 编译时要生成进行动态分配的目标指令。
-
分配策略
整个数据区为一个堆栈,
(1) 当进入一个过程时,在栈顶为其分配一个数据区。
(2) 退出时,撤消过程数据区。
-
活动记录
-
一个典型的活动记录可以分为三部分:
-
局部数据区: 存放模块中定义的各个局部变量。
-
参数区: 存放隐式参数和显式参数。
-
display区: 存放各外层模块活动记录的基地址。
-
-


源程序的中间形式
- 一般编译程序都生成中间代码,然后再生成目标代码,主要优点是可移植(与具体目标程序无关),且易于目标代码优化。
波兰表示
由波兰逻辑学家 J.Lukasiewicz 提出
-
前缀表示(波兰表示):<操作符><操作数序列>
-
后缀表示(逆波兰表示):<操作数序列><操作符>
N元表示
在该表示中,每条指令由n个域组成,通常第一个域表示操作符,其余为操作数。
- 常用的n元表示是: 三元式 四元式
使用三元式不便于代码优化,因为优化要删除一些三元式,或对某些三元式的位置要进行变更,由于三元式的结果(表示为编号),可以是某个三元式的操作数,随着三元式位置的变更也将作相应的修改,很费事。
- 间接三元式:为了便于在三元式上作优化处理,可使用间接三元式
抽象语法树
-
抽象语法树: 用树型图的方式表示中间代码操作数出现在叶节点上,操作符出现在中间结点
-
DAG图: Directed Acyclic Graphs 有向无环图语法树的一种归约表达方式
错误处理
概述
-
必备功能之一
-
正确的源程序:通过编译生成目标代码
-
错误的源程序:通过编译发现并指出错误
-
-
错误处理能力
-
(1) 诊察错误的能力
-
(2) 报错及时准确
-
(3) 一次编译找出错误的多少
-
(4) 错误的改正能力
-
(5) 遏止重复的错误信息的能力
-
错误分类
从编译角度,将错误分为两类:语法错误和语义错误
-
语法错误:源程序在语法上不合乎文法
-
语义错误主要包括:程序不符合语义规则或超越具体计算机系统的限制
-
语义规则:
-
标识符引用要符合作用域规定
-
标识符先说明后引用
-
参与运算的操作数类型一致
-
过程调用时实参与形参要一致
-
下标变量下标不能越界
-
-
超越系统限制:
-
数据溢出错误
-
符号表、静态存储分配数据区溢出
-
动态存储分配数据区溢出
-
错误的诊察和报告
- 错误诊察:
1. 违反语法和语义规则以及超过编译系统限制的错误。
编译程序: 语法和语义分析时(语义分析要借助符号表)
2. 下标越界,计算结果溢出以及动态存储数据区溢出。
目标程序: 目标程序运行时(编译程序要生成相应的目标程序作检查和进行处理
- 错误报告:
1. 出错位置:即源程序中出现错误的位置
一旦诊察出错误,当时的计数器内容就是出错位置
2. 出错性质:
可直接显示文字信息
可给出错误编码
3. 报告错误的两种方式:
(1) 分析完以后再报告:编译程序可设一个保存错误信息的数据区(可用记录型数组),将语法语义分析所诊察到的错误送数据区保存,待源程序分析完以后,显示或打印错误信息。
(2) 边分析边报告:可以在分析一行源程序时若发现有错,立即输出该行源程序,并在其下输出错误信息。
错误处理技术
发现错误后,在报告错误的同时还要对错误进行处理,以方便编译能进行下去。目前有两种处理办法:
1. 错误改正: 指编译诊察出错误以后,根据文法进行错误改正。
2. 错误局部化处理: 指当编译程序发现错误后,尽可能把错误的影响限制在一个局部的范围,避免错误扩散和影响程序其他部分的分析。
-
一般原则
当诊察到错误以后,就暂停对后面符号的分析, 跳过错误所在的语法成分然后继续往下分析。
-
词法分析:发现不合法字符,显示错误,并跳过该标识符(单词)继续往下分析。
-
语法语义分析:跳过所在的语法成分(短语或语句),一般是跳到语句右界符,然后从新语句继续往下分析。
-
-
错误局部化处理的实现(递归下降分析法)
cx: 全局变量,存放错误信息。
-
出错程序先打印或显示出错位置以及出错信息,然后跳出一段源程序, 直到跳到语句的右界符(如:end)或正在分析的语法成分的合法后继符号为止, 然后再往下分析。
-
用递归下降分析时,如果发现错误,便将有关错误信息(字符串或者编号)送CX,然后转出错误处理程序;
-
3.目标程序运行时错误检测与处理.
下标变量下标值越界
计算结果溢出
动态存储分配数据区溢出
- 在编译时生成检测该类错误的代码。
对于这类错误,要正确的报告出错误位置很难,因为目标程序与源程序之间难以建立位置上的对应关系。
- 一般处理办法:
当目标程序运行检测到这类错误时,就调用异常处理程序,打印错误信息和运行现场(寄存器和存储器中的值)等, 然后停止程序运行。
语法制导翻译技术
翻译文法和语法制导翻译
-
输入文法:未插入动作符号时的文法。
由输入文法可以通过推导产生输入序列。
-
翻译文法:插入动作符号的文法。
由翻译文法可以通过推导产生活动序列。
-
翻译文法是上下文无关文法,其终结符号集由输入符号和动作符号组成。由翻译文法所产生的终结符号串称为活动序列。
-
符号串翻译文法: 若插入文法中的动作符号对应的语义子程序是输出动作符号标记@后的字符串的文法。
-
语法制导翻译(Syntax Directed Translation):按翻译文法进行的翻译。给定一输入符号串,根据翻译文法获得翻译该符号串的动作序列,并执行该序列所规定的动作的过程。
属性翻译文法
在翻译文法的基础上,可以进一步定义属性文法,翻译文法中的符号,包括终结符、非终结符和动作符号均可带有属性,这样能更好的描述和实现编译过程。
-
综合属性: 用自下而上的$\to$表示属性计算是自底向上的,称为综合属性。体现自底向上,自右向左的求值特性
- (1)产生式右部非终结符号的综合属性值,取其下部产生式左部同名非终结符号的综合属性值。
- (2)产生式左部非终结符号的综合属性值,用该产生式左部符号的继承属性或某个右部符号的属性进行计算。
- (3)动作符号的综合属性用该符号的继承属性或某个右部符号的属性进行计算。
-
继承属性:体现自顶向下,自左向右的求值特性。
-
(1) 产生式左部非终结符号的继承属性值,取前面产生式右部该符号已有的继承属性值。
-
(2)产生式右部符号的继承属性值,用该产生式左部符号的继承属性或出现在该符号左部的符号的属性值进行计算。
-
-
L- 属性翻译文法( L-ATG )
- 这是属性翻译文法中较简单的一种。其输入文法要求是LL(1)文法,可用自顶向下分析构造分析器。在分析过程中可进行属性求值。
自顶向下语法制导翻译
- 翻译文法的自顶向下翻译**——**递归下降翻译器
按翻译要求,在文法中插入语义动作符号,在分析过程中调用相应的语义处理程序,完成翻译任务。
- 属性文法自顶向下翻译的实现——递归下降翻译器
对于每个非终结符号都编写一个翻译子程序(过程)。根据该 非终结符号具有的属性数目,设置相应的参数。
继承属性:声明为赋值形参
综合属性:声明为变量形参
语义分析和代码生成
声明的处理
- 编译程序的任务:
- 编译程序处理声明语句要完成的主要任务为:
- 分离出每一个被声明的实体,并把它们的名字填入符号表中
- 把被声明实体的有关特性信息尽可能多地填入符号表中
- 对于已声明的实体,在处理对该实体的引用时要做的事情:
- 检查对所声明的实体引用(种类,类型等)是否正确
- 根据实体的特征信息,例如类型,所分配的目标代码地址(可能为数据区单元地址,或目标程序入口地址)生成相应的目标代码
- 编译程序处理声明语句要完成的主要任务为:
- 数组变量的声明
- 静态数组:数组的大小在编译时是已知的,建立数组模板(又称为数组信息向量)以便以后的程序中引用该数组元素时,可按照该模板提供的信息,计算数组元素(下标变量)的存储地址。
- 动态数组: 大小只有在运行时才能最后确定。在编译时仅为该模板分配一个空间,而模板本身的内容将在运行时才能填入。
表达式的处理
分析表达式的主要目的是生成计算该表达式值的代码。通常的做法是把表达式中的操作数装载(LOAD)到操作数栈(或运行栈)栈顶单元或某个寄存器中,然后执行表达式所指定的操作,而操作的结果保留在栈顶或寄存器中。
操作数栈即操作栈,它可以和前述的运行栈(动态存储分配)合而为一,也可单独设栈。
处理逻辑表达式(关系表达式)的方法与处理算术表达式的方式基本相同。
- Title: compiler-theory-3
- Author: Charles
- Created at : 2023-07-19 19:59:00
- Updated at : 2024-06-04 19:20:53
- Link: https://charles2530.github.io/2023/07/19/compiler-theory-3/
- License: This work is licensed under CC BY-NC-SA 4.0.

