
ML-paper-QLora
QLora
**核心问题:**如何在不牺牲性能的情况下,减少大型语言模型(LLMs)微调过程中的内存使用。
核心方法(贡献):
- QLORA 方法:提出了一种高效的微调方法,通过冻结的 4 位量化预训练语言模型反向传播梯度到低秩适配器(LoRA)。
- 4-bit NormalFloat (NF4):引入了一种新的数据类型,理论上适用于正态分布权重的量化。
- 双重量化:通过量化量化常数来减少平均内存占用。
- 分页优化器:使用 NVIDIA 统一内存管理内存峰值。
实验效果:
- 模型性能:最佳模型家族“Guanaco”在 Vicuna 基准测试中超越了所有之前公开发布的模型,达到了 ChatGPT 性能的 99.3%。
- 内存效率:将 65B 参数模型的微调平均内存需求从>780GB 的 GPU 内存减少到<48GB,而没有降低运行时或预测性能。
- 训练时间:在单个 GPU 上,33B 参数模型的训练时间少于 12 小时,65B 参数模型的训练时间为 24 小时。
改进方向:
- 数据集质量:发现数据集质量比数据集大小更重要,例如 9k 样本数据集(OASST1)在聊天机器人性能上优于 450k 样本数据集(FLAN v2)。
- 基准测试:发现当前的聊天机器人基准测试不可靠,无法准确评估聊天机器人的性能水平。
- 模型评估:基于人类和 GPT-4 的评估显示,GPT-4 评估是人工评估的廉价且合理的替代方案,但也存在不确定性。
背景与相关工作
讨论了大型语言模型(LLMs)微调的重要性和成本,以及现有的量化方法在推理和训练中的局限性。
- 保持 16 位 LLM 质量的主要方法集中于管理离群特征,如 SmoothQuant 和 LLM.int8()
方法理论
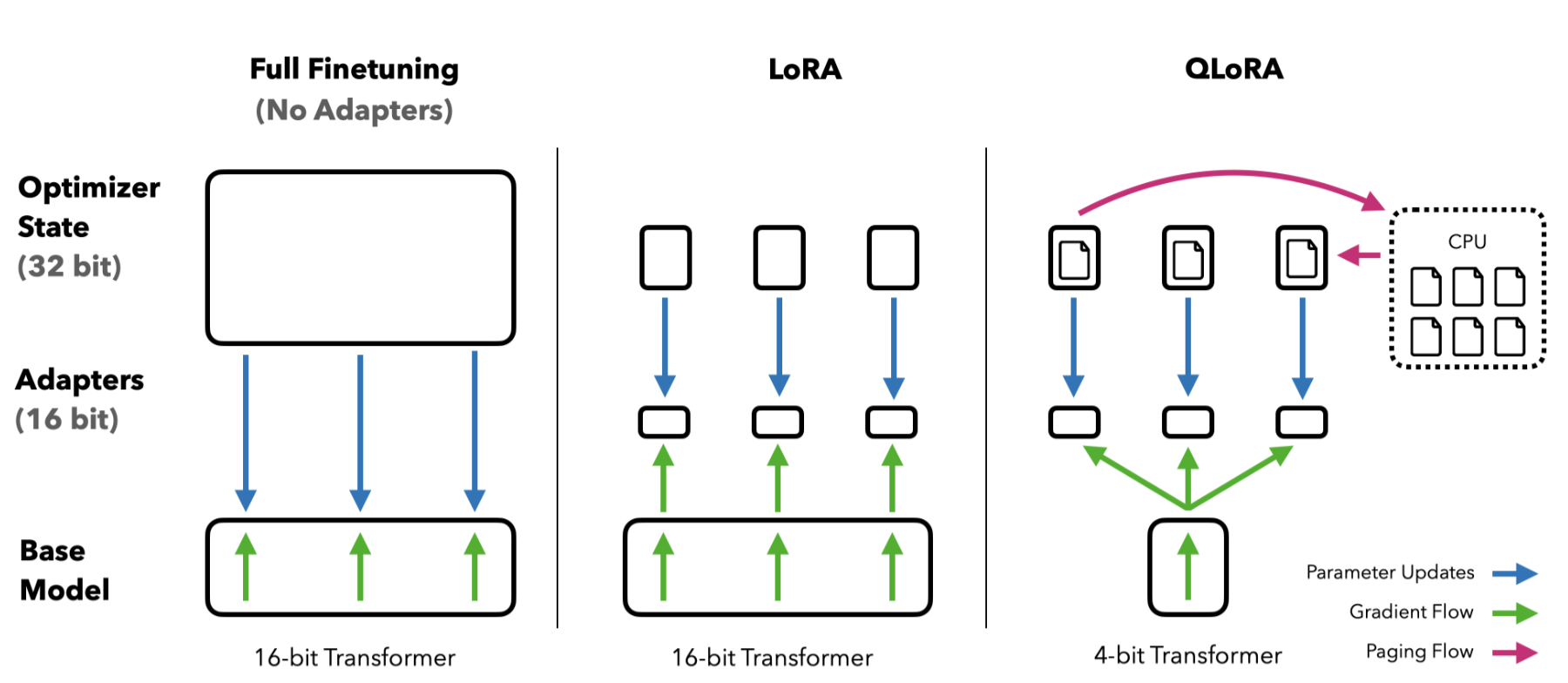
- LoRA 微调:介绍了低秩适配器(LoRA)微调方法,通过少量可训练参数减少内存需求。
- 量化技术:详细描述了 4-bit NormalFloat(NF4)量化和双重量化(DQ)的方法。
- 分页优化器:解释了如何使用 NVIDIA 统一内存来管理内存峰值。
4-bit NormalFloat Quantization
传统的量化方法,如将 32 位浮点数(FP32)量化到 8 位整数(Int8),在处理权重时可能会遇到问题,尤其是在存在异常值(outliers)时,量化桶(某些位组合)可能不会被充分利用。为了解决这个问题,提出了一种基于分位数量化(Quantile Quantization)的方法,这种方法在信息论上是最优的,确保每个量化桶中分配的输入张量值数量相等。
- 分位数量化通过估计输入张量的分位数来工作,通常使用经验累积分布函数(empirical cumulative distribution function)。这种方法的一个限制是分位数估计过程计算成本较高,因此通常使用快速分位数近似算法(如 SRAM 分位数)来估计。
- NormalFloat(NF)数据类型基于分位数量化,但针对正态分布数据进行了优化。由于预训练的神经网络权重通常具有以零为中心的正态分布,通过调整标准差 σ,可以将所有权重转换为一个固定的分布,使其完全适合数据类型的范围。首先估计理论正态分布 N(0, 1)的 2k+1 个分位数,以获得适用于正态分布的 k 位分位数量化数据类型。然后将这些分位数值归一化到[-1, 1]范围内,并通过对输入权重张量进行绝对最大值重缩放来进行量化。
- 对称 k 位量化方法没有零的精确表示,这对于量化填充和其他零值元素而不产生误差很重要。为了确保数据类型的每个量化桶中预期的值数量相等,创建了一个非对称数据类型,估计两个范围的分位数 qi:2k-1 用于负部分,2k-1+1 用于正部分,然后统一这些 qi 集合并移除两个集合中出现的零。
Double Quantization
在量化过程中,量化常数本身也需要存储,这会占用额外的内存。为了进一步减少内存占用,提出了双重量化技术。
- 双重量化涉及对第一级量化的量化常数进行再次量化。具体来说,第一级量化常数(cFP32)被视为输入,进行第二级量化。第二级量化使用 8 位浮点数(cFP8),并采用 256 的块大小进行量化。
- 量化常数 cFP32 在第一级量化中被量化为 8 位浮点数 cFP8。这一步骤通过量化常数的量化常数 cFP32_1 来实现。为了使量化常数 cFP32_2 的值围绕零中心化,提高量化的效率,通常会从 cFP32 中减去其均值,然后再进行量化。
Paged Optimizers
Paged Optimizers 利用 NVIDIA 的统一内存(Unified Memory)特性,通过在 CPU 和 GPU 之间自动进行页面到页面的传输,来避免内存峰值问题。
这种方法类似于 CPU RAM 和磁盘之间的常规内存分页,允许在 GPU 内存不足时,将部分数据自动转移到 CPU 内存中。
- 在训练过程中,如果 GPU 内存不足,Paged Optimizers 会自动将优化器状态(如梯度信息)从 GPU 转移到 CPU 内存中。当需要进行优化器更新时,这些状态会再次从 CPU 内存分页回 GPU 内存中。
QLORA
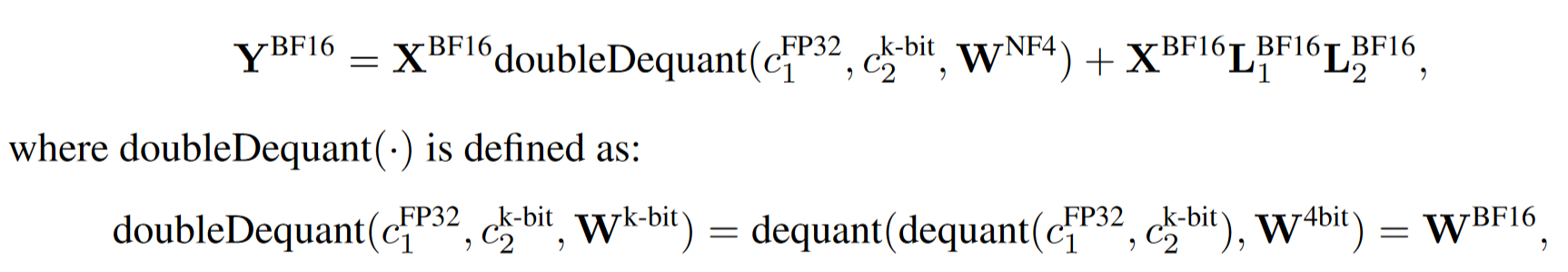
实验工作
- 数据集:使用了多个指令调整数据集,包括 OASST1、HH-RLHF、FLAN v2 等。
- 训练设置:详细描述了不同模型架构和规模的训练设置,包括学习率、批量大小和训练步骤。
- 评估:通过 MMLU 基准测试和 Vicuna 基准测试评估模型性能,并进行了人类和 GPT-4 的评估。
- Title: ML-paper-QLora
- Author: Charles
- Created at : 2024-07-26 08:27:17
- Updated at : 2026-05-11 20:11:22
- Link: https://charles2530.github.io/2024/07/26/ml-paper-qlora/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments