
ML-paper-RAG
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
**核心问题:**如何提高大型预训练语言模型在知识密集型自然语言处理(NLP)任务中的性能,特别是在需要外部知识的情况下。
RAG 模型通过结合预训练的参数记忆和非参数记忆,显著提高了知识密集型 NLP 任务的性能。该方法在开放域问答和知识密集型生成任务中均取得了优异的结果。
核心方法(贡献):
- 检索增强生成(RAG):提出了一种结合预训练参数记忆(如序列到序列模型)和非参数记忆(如 Wikipedia 的密集向量索引)的方法。
- 双组件模型:模型包括一个检索器(基于 DPR 的检索组件)和一个生成器(基于 BART 的序列到序列模型)。
- 端到端训练:通过将检索到的文档作为潜在变量,并使用 top-K 近似来边缘化这些潜在变量,实现检索器和生成器的联合训练。
实验效果:
- 在多个开放域问答任务中取得了最先进的结果,包括 Natural Questions、WebQuestions 和 CuratedTrec。
- 在知识密集型生成任务中,RAG 模型生成的语言更具体、多样化且事实性更强。
改进方向:
- 检索组件的预训练:探索是否可以对检索组件进行更有效的预训练,以提高检索的准确性。
- 检索和生成的联合优化:研究如何更有效地结合检索和生成过程,以进一步提高模型性能。
- 知识更新:研究如何动态更新模型的非参数记忆,以适应不断变化的世界知识,而且如何保证数据库是没有偏见的也是潜在的重要问题。
背景与相关工作
- 讨论了预训练语言模型在知识存储和操作方面的局限性。
- 介绍了混合模型的概念,结合参数记忆和非参数记忆来解决这些问题。
- 预训练模型不能轻易地扩大或修改自己的记忆,不能直截了当地洞察他们的预测,并可能产生’幻觉’。
我们建立了 RAG 模型,其中参数记忆是预训练的 seq2seq 转换器,非参数记忆是维基百科的稠密向量索引,通过预训练的神经检索器访问
Single-Task Retrieval
检索对单一任务的提升:研究表明,将检索机制应用于特定的 NLP 任务(如开放域问答、事实检查等)可以显著提高性能。这种方法通过检索相关信息来增强模型的决策能力。我们的工作统一了先前在将检索整合到单个任务中的成功,表明基于单个检索的架构能够在多个任务中实现强大的性能。
General-Purpose Architectures for NLP
通用 NLP 架构:研究展示了通过微调单个预训练语言模型(如 BERT、GPT-2)可以在多种分类和生成任务上实现强大的性能。这些模型通过学习语言的通用表示来处理不同的 NLP 任务。我们的工作旨在通过学习一个检索模块来增加预训练的、生成性的语言模型,以单一的、统一的架构来扩展可能的任务空间。
Learned Retrieval
学习检索:在信息检索领域,使用预训练的神经语言模型来学习检索文档的方法已经取得了进展。这些方法通过优化检索模块来辅助特定的下游任务,如问答系统。
Memory-based Architectures
基于记忆的架构:将大型外部记忆(如文档索引)作为神经网络的注意力目标,类似于记忆网络。这种架构使得模型能够访问和利用大量的外部知识,从而提高其在知识密集型任务中的表现。我们的方法确实有一些不同之处,包括较少强调对检索项的轻微编辑,而是强调从几块检索内容中聚合内容,以及学习潜在检索,并检索证据文档而不是相关的训练对。
Retrieve-and-Edit approaches
检索-编辑方法:这些方法通过检索与输入相关的训练输入-输出对,然后编辑这些对以生成最终输出。它们在机器翻译和语义解析等领域取得了成功,强调了从检索到的内容中进行轻量级编辑的重要性。
方法理论
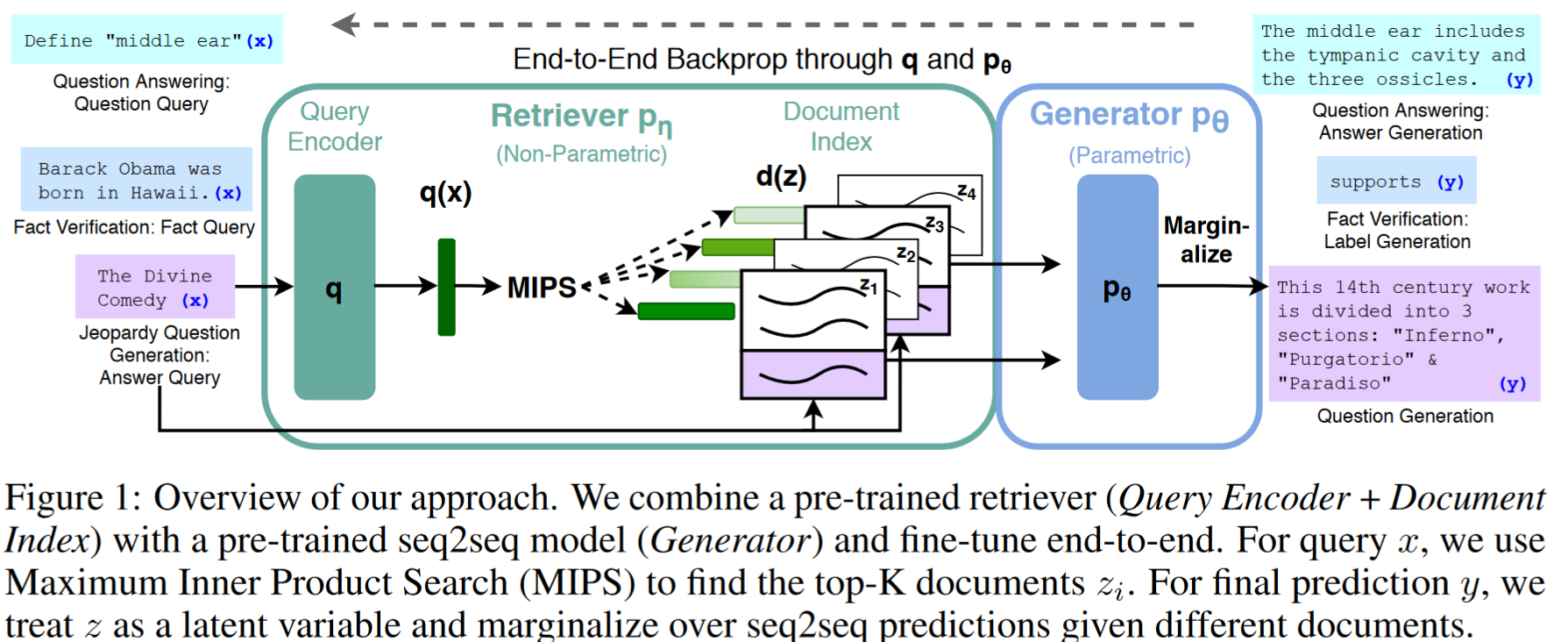
- RAG 模型:详细介绍了 RAG 模型的结构,包括检索器和生成器的组件。
- 训练过程:描述了如何通过边缘化检索到的文档来训练 RAG 模型。
- 解码策略:介绍了 RAG-Sequence 和 RAG-Token 模型的不同解码策略。
Models
我们探索 RAG 模型,该模型使用输入序列 x 检索文本文档 z,并在生成目标序列 y 时将其作为额外的上下文。
通过将目标类看作长度为 1 的目标序列,RAG 可以用于序列分类任务,此时 RAG-Sequence 和 RAG-Token 是等价的。
-
检索器(Retriever):
-
基于 Dense Passage Retriever(DPR)的双编码器架构。
Dense Passage Retriever(DPR)是一种基于深度双向编码器的检索方法,用于开放域问答任务。它通过计算查询和文档的密集表示之间的相似度来进行文档检索,通常使用点积或最大内积搜索技术,以快速准确地找到包含答案的文档。
-
使用 BERT-base 模型对文档进行编码,生成密集的文档表示。
-
通过最大内积搜索(MIPS)检索与输入查询最相关的文档。
-
-
生成器(Generator):
- 使用预训练的序列到序列(seq2seq)模型,如 BART-large。
- 负责基于输入序列和检索到的文档生成目标序列。
-
RAG 模型:
- 结合了检索器和生成器,通过端到端训练实现检索增强的生成。
- 包括两种形式的 RAG 模型:RAG-Sequence 和 RAG-Token。
-
RAG-Sequence 模型:
- 使用单一检索文档来生成整个序列。
- 通过 top-K 近似来边缘化检索到的文档,以获得序列生成的概率分布。
-
RAG-Token 模型:
- 可以为每个目标标记检索不同的文档,并相应地边缘化。
- 允许生成器在生成答案时选择多个文档中的内容。
实验工作
- 数据集:使用了多个开放域问答数据集,如 Natural Questions、TriviaQA、WebQuestions 和 CuratedTrec。
- 实验设置:详细描述了实验的设置,包括模型的参数、训练过程和评估方法。
- 结果分析:展示了 RAG 模型在不同任务上的性能,并与其他方法进行了比较。
- Title: ML-paper-RAG
- Author: Charles
- Created at : 2024-07-29 10:53:35
- Updated at : 2026-05-11 20:11:22
- Link: https://charles2530.github.io/2024/07/29/ml-paper-rag/
- License: This work is licensed under CC BY-NC-SA 4.0.