
扩散模型:扩散方法怎么选:先判断你在改哪一层成本
扩散方法对照最容易写成方法名大表:DDPM、DDIM、Euler、Heun、DPM-Solver++、Consistency、LCM、DMD、Rectified Flow 都排在一起,最后用“步数更少”做结论。这个读法很危险,因为这些方法改的不是同一个部件。
更实用的问法是:你能不能重训;想省的是在线网络评估次数、离线训练成本、显存,还是调参时间;最不能接受的是纹理变糊、条件控制变弱、多样性下降,还是端到端延迟不达标。方法名只有放进这些约束里,才会变成工程判断。
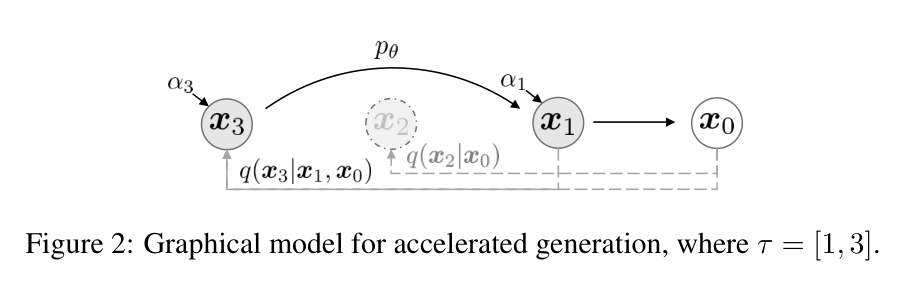
图源:DDIM。原图表达同一个训练好的扩散模型可以用更稀疏的反向路径加速采样;本站读法是把“换采样器”和“重训/蒸馏学生”先分开,避免把所有少步方法混成一类。它不能证明任意模型都能极少步高质量生成,只说明不重训路线的第一层收益来自采样路径。
先定边界
如果不能重训,选择范围基本落在采样路径和数值求解器:DDIM、Euler、Heun、DPM-Solver、DPM-Solver++。它们不让模型获得新的生成能力,只是在同一个去噪网络上换一条更适合离散积分的路。
如果可以重训或蒸馏,选择范围才进入 Progressive Distillation、Consistency Models、LCM、DMD、DMD2、Phased DMD、Flow Matching、Rectified Flow / Rectified Diffusion。它们把线上步数省下来,但把成本转移到教师模型、蒸馏数据、训练稳定性和评估覆盖上。
所以第一刀不是“新旧”,而是“推理侧替换”还是“训练侧重做”。这一步分清后,很多比较会自然变简单。
| 路线 | 是否需要重训 | 主要节省 | 主要风险 | 适合先试的场景 |
|---|---|---|---|---|
| DDIM / Euler / Heun / DPM-Solver++ | 通常不需要 | 在线步数和调试周期 | 极少步下细节变软,CFG 放大后不稳定 | 已有高质量模型,需要马上降延迟 |
| Progressive Distillation / Consistency / LCM | 需要教师或蒸馏训练 | 线上网络评估次数 | 学生把教师的纠错过程压扁,局部纹理和多样性下降 | 交互式预览、4 到 8 步生成 |
| DMD / DMD2 / Phased DMD | 需要更重训练 | 整条采样轨迹 | 分布匹配不稳,容易出现安全但单调的输出 | 一步或两步高质量生成研究 |
| Flow Matching / Rectified Flow | 通常是新底座训练 | 路径弯曲带来的积分成本 | 路径、时间采样、条件注入都要重新设计 | 新训练 latent flow、视频或多模态生成底座 |
不重训时,先把采样器榨干
DDIM 的价值是说明同一个训练好的扩散模型不只有 DDPM 那条随机反向链。它可以换成更确定、更稀疏的采样路径,因此在不重训的前提下减少步数。代价也在这里:路径更稀疏后,模型每一步要承担更大的修正量,极少步时常见问题是大结构还能看,局部纹理、边缘和材质层次变软。
Euler 和 Heun 把问题进一步放到 ODE 积分里看。Euler 每步只按当前方向走一步,便宜、直接、好调;Heun 会先走一小步,再用预测后的方向做校正,通常在同等步数下更稳,但每个采样步需要更多计算。它们适合做快速基线,因为切换成本低,失败也容易定位。
DPM-Solver 和 DPM-Solver++ 的优势,是利用扩散 ODE 的结构做更专门的高阶求解。尤其在 classifier-free guidance 已经成为图像生成标配之后,DPM-Solver++ 的实际意义不只是“少步”,而是 guided sampling 下更稳。评估这一路线时,必须同时报告步数、CFG scale、时间表、分辨率、batch size、P50/P95 延迟和失败样本;只报一个 FID 或单张图没有太多工程价值。
这一层路线的底线很清楚:它能让现有模型跑得更快,但不能弥补模型没学会的东西。prompt 不跟、手部结构差、训练数据偏,这些问题不会因为换 solver 就自动消失。
4 到 8 步时,看学生有没有继承教师的纠错能力
Progressive Distillation 的思路是把教师的两步合成学生的一步,再逐轮把采样步数减半。它没有要求学生一开始就学会从纯噪声直达干净图像,而是沿着教师轨迹逐段压缩,所以在少步范围内通常比直接一步更稳。
Consistency Models 和 Latent Consistency Models 更强调跨时间点的一致映射:不同噪声时间的样本,经过模型后应该落到同一个干净结果附近。这个思路很适合交互式生成,因为一到几步就能给出可用结果;但它也会暴露一个老问题:教师在多步采样里不断修正的细节,学生必须压进很少的前向里,局部纹理、多样性和强条件控制容易先掉。
这一路线适合产品里的草图预览、低延迟候选图、快速迭代,而不一定适合作为最终质量的唯一出口。更稳的做法往往是把少步学生当成前端速度层,把高步教师或更强采样器保留为精修层。
1 到 2 步时,问题已经不是普通求解器问题
一步生成不是把 DPM-Solver 的步数继续往下调。多步扩散把复杂生成过程拆成许多局部修正;一步学生必须在一次前向里同时处理构图、语义、材质、文字、细小边缘和条件约束。它面对的是整体分布匹配问题。
DMD 系列的关键就在这里:学生不只模仿教师某个中间点,而是试图让一步或少步输出的分布接近教师或真实数据分布。DMD2 改进了训练稳定性和可扩展性;Phased DMD 进一步把学习难度分阶段处理,让模型先抓结构,再逐步压细节。它们的收益很诱人,但也更容易被漂亮样例误导。一步模型最需要看的不是最好看的十张图,而是失败尾部:重复脸、假纹理、文字边缘、细小物体、复杂 prompt、多主体关系、seed 多样性。
这一路线的验收要比普通采样器更严。除了图像质量和语义对齐,还要专门看 diversity、precision/recall、局部裁剪、强 CFG、长 prompt、负面词、LoRA 或 ControlNet 兼容性。若只在短 prompt、精选 seed、无控制条件上展示,结论不能外推到真实系统。
新训练底座时,Flow 和 Rectified 路线是在重画路径
Flow Matching 把生成看成从噪声分布到数据分布的一条连续路径,并让模型直接学习路径上的速度场。它的吸引力在于训练目标和 ODE 采样方向更贴近,少步采样、蒸馏和视频 latent 生成都更容易围绕这套方向场组织。
Rectified Flow 和 Rectified Diffusion 的核心不是简单宣称“直线最好”,而是问一条从噪声到数据的路径能不能被训练得更容易积分。路径越弯,粗步长越容易偏离;路径更可积,少步生成才更自然。这个视角解释了为什么很多新底座会把速度预测、flow 目标、rectified 路径和 DiT / latent 表示放在一起考虑。
但它不是旧扩散模型的万能替代品。新的路径目标会影响时间采样、损失权重、条件注入、CFG 行为和蒸馏接口。对视频尤其如此:减少采样步数只是总成本的一部分,时空 token、注意力缓存、条件编码器和解码器同样可能成为瓶颈。
按约束选,而不是按名气选
已有 Stable Diffusion 或同类模型,目标是把线上延迟从几秒压到一秒左右,先试 DPM-Solver++、Euler、Heun 和更合适的时间表。这个阶段的收益最快,也最容易保持 LoRA、ControlNet、adapter 和 prompt 工作流的兼容。
目标是实时预览、草图探索、slider 拖动时即时反馈,优先考虑 LCM、Consistency 或少步蒸馏模型。它们不一定是最终质量答案,但很适合把交互速度做起来。
目标是一步高质量生成,且能承担训练预算和失败分析,才进入 DMD2、Phased DMD、Rectified Diffusion 这类路线。这里不要期待一个 solver 参数解决问题,需要配套的训练、判别信号、教师、正则和评估集。
目标是从头训练视频、多模态或 latent flow 底座,Flow Matching / Rectified 路线更值得认真评估。它们改的是生成路径和速度场,不是只换最后的采样器;因此要把模型结构、数据、条件控制和部署成本放在同一张表里算。
验收看失败桶
方法对照最后要落在失败桶,而不是落在论文名。至少保留六类样本:普通短 prompt、长 prompt、多主体关系、细小文字和纹理、强条件控制、seed 多样性。视频还要额外看运动一致性、遮挡恢复、镜头切换和长时漂移。
性能也要按系统口径记录:网络评估次数、单次前向耗时、VAE / decoder 成本、条件网络成本、显存峰值、P50/P95 延迟、吞吐和失败重试率。少了这些指标,“10 步”和“1 步”只是论文里的数字,不一定是产品里的速度。
这也是本页的判断标准:DDIM、DPM-Solver++ 是推理侧加速;Consistency / LCM 是少步学生;DMD 系列是分布匹配蒸馏;Flow / Rectified 是路径和速度场重写。先确认自己在改哪一层,再谈哪一个方法更合适。
外部精读
- DDPM: Denoising Diffusion Probabilistic Models:理解原始多步去噪教师的训练和采样基线。
- DDIM: Denoising Diffusion Implicit Models:理解不重训换采样路径为什么可行。
- DPM-Solver 与 DPM-Solver++:理解高阶 diffusion ODE 求解器和 guided sampling 稳定性。
- Progressive Distillation、Consistency Models 与 Latent Consistency Models:理解少步学生如何替代长轨迹教师。
- DMD、DMD2 与 Phased DMD:理解一步/少步分布匹配路线的训练难点。
- Flow Matching、Rectified Flow 与 Rectified Diffusion:理解路径和速度场重写为什么会影响少步采样。
相关阅读与下一步
- 外部材料:Lil’Log:What are Diffusion Models?。
- 外部材料:DDPM 论文。
- 外部材料:Score SDE 论文。
- 站内下一步:扩散模型专题。
- 站内下一步:扩散方法对比表。
- 站内下一步:Score Matching、SDE 与 Probability Flow。
- Title: 扩散模型:扩散方法怎么选:先判断你在改哪一层成本
- Author: Charles
- Created at : 2025-05-01 09:00:00
- Updated at : 2025-05-01 09:00:00
- Link: https://charles2530.github.io/2025/05/01/ai-files-diffusion-comparison-table/
- License: This work is licensed under CC BY-NC-SA 4.0.