
扩散模型:噪声日程与参数化
这篇回答的问题。 如何理解“噪声日程与参数化”背后的核心机制、适用边界和下一步阅读路径。
扩散训练看起来只是“给图加噪,再让模型预测噪声”。真正影响模型性格的,是两件更细的事:噪声日程决定训练样本会落在哪些难度区间,参数化决定模型用什么坐标回答这个去噪问题。它们会直接影响采样器、CFG、少步生成、视频一致性和世界模型里的动作敏感性。
可以把这页当成训练和推理之间的桥。训练页讲模型怎样学会局部方向;Score/SDE 页讲这些方向怎样变成概率流;Inference 页讲采样器怎样有限步积分。噪声日程与参数化负责回答:这些方向在不同噪声区间到底有多难学,模型输出的坐标又是否适合采样器使用。
噪声日程本质上是难度曲线
DDPM 的前向加噪可以写成:
这行式子把当前带噪样本 拆成两部分: 是还保留下来的干净信号, 是混进去的高斯噪声。 越接近 1,样本越清楚;越接近 0,样本越像纯噪声。
离散 DDPM 里通常先定义每一步加多少噪声:
这里 是第 步加入的噪声方差。它不是一个孤立超参,而是一整条序列 。把每一步保留信号的比例记作 ,从第 1 步累积到第 步的保留比例就是:
这条曲线决定图像从清晰变成噪声的速度。若前面掉得太快,模型很早就面对几乎无结构的样本;若后面太密,训练和采样会把大量预算花在相近的低噪声状态上。所谓 noise schedule,不只是“时间步怎么编号”,而是在分配模型练习哪些难度。
SNR 比时间步更接近训练压力
只看 容易误判难度,因为加噪强度线性变化,不代表信号可见度线性变化。更有用的量是信噪比:
它直接比较当前样本里干净信号和噪声的相对强弱。高 SNR 时,图像还清楚,模型更像在修边缘、颜色和局部纹理;中等 SNR 时,主体结构还隐约可见,模型要恢复形状、布局和语义关系;低 SNR 时,局部证据很弱,模型更多依赖数据分布和条件信号猜大结构。
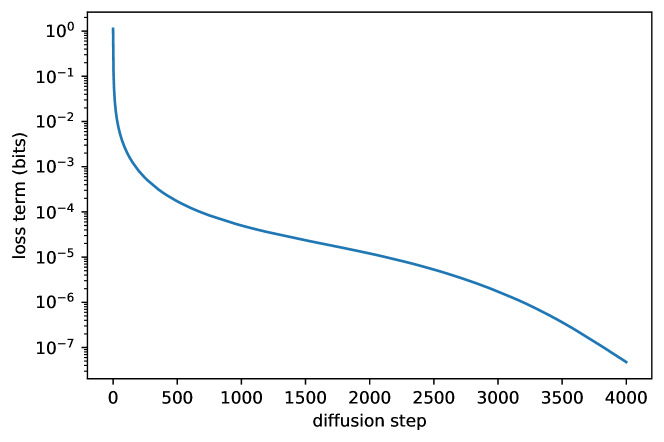
图源:Improved Denoising Diffusion Probabilistic Models,Figure 2。原图分析 CIFAR-10 训练中 variational lower bound 各 timestep 项的贡献。本站读法:不同时间步对训练目标的压力差异很大;schedule、loss weighting 和 timestep sampling 会决定模型容量花在低噪声细节、中噪声结构还是高噪声语义上。
Improved DDPM 推动 cosine schedule 的原因也在这里。它不是为了让曲线看起来漂亮,而是让信号衰减更平滑,避免某些 SNR 区间被过早或过晚挤压。现代训练还会继续调 loss weighting 或 timestep sampling,例如 Min-SNR weighting 这类方法,就是在处理不同噪声水平之间的优化冲突。
连续噪声尺度让采样器更容易接上
离散时间 适合讲 DDPM 的前向链,但工程采样常更关心“现在噪声标准差是多少”。EDM 一类写法直接使用连续噪声尺度:
就是噪声标准差。小 表示样本接近数据,模型主要修细节;大 表示样本接近高斯噪声,模型主要确定全局结构。这样写的好处是,采样器可以直接在 轴上安排步长,而不是被训练时的离散编号绑死。
这也解释了为什么训练 schedule 和 sampling schedule 不能混着说。训练时你决定模型在哪些噪声水平见过数据;推理时你决定从高噪声到低噪声经过哪些点。两者如果错配,模型可能在采样时被带到训练覆盖不足的区域。Common Diffusion Noise Schedules and Sample Steps are Flawed 讨论的 zero terminal SNR,就是这个错配的典型例子:如果训练日程末端没有真正走到纯噪声,采样却从纯噪声开始,训练和推理的起点语义就不一致。
参数化是在换坐标系
给定同一个 ,模型可以预测噪声 、干净样本 、score 或 velocity。它们常常能互相换算,但训练效果并不等价,因为损失尺度、梯度分布和少步误差会不同。
最经典的是 -prediction:
训练时真实噪声 是我们自己采样的,所以监督信号直接、稳定。它的局限是,不同 SNR 区间里噪声预测误差对最终样本的影响并不均衡;强 guidance 或少步采样会把这些误差放大。
-prediction 直接让模型猜干净样本:
它对采样器很友好,因为很多更新规则都需要 。但在高噪声区, 几乎看不出原图,直接预测 会承受更大的不确定性。它不是“更直观所以一定更好”,而是把难度换到了另一个坐标里。
score prediction 则估计当前噪声分布的概率坡度:
score 告诉采样器往哪里走,当前样本的概率密度会上升。常见 DDPM 噪声预测可以按噪声尺度转换成 score,负号表示“预测噪声方向”和“去数据高概率区域方向”相反。这部分更详细地接到 Score Matching 到 SDE。
velocity 为什么常被拿出来讲
很多现代模型使用 -prediction。先把带噪状态写成:
这里 和 可以看成单位圆上的两个坐标:低噪声时 大、 小;高噪声时反过来。velocity 定义为:
这不是多发明一个神秘目标,而是把 旋转成 。如果把 ,那么:
沿着角度 求导,就得到:
所以 可以理解成混合路径上的切向方向: 表示当前混到了哪里, 表示沿噪声路径继续移动时,干净信号和噪声怎样交换。模型预测 后,可以换回:
低噪声时, 更接近噪声预测;高噪声时, 更接近负的数据预测。它在不同 SNR 区间之间平滑切换,所以 Progressive Distillation、Imagen 系列实践、Stable Diffusion 后续配置和很多视频 / flow 风格模型都会关注 -prediction。要注意:它不是保证质量的单独按钮,仍然要和 loss weighting、noise schedule、sampler 和 guidance 一起看。
采样器最终要拿到可更新的方向
不管模型输出 、、score 还是 ,采样时都要落到同一个执行问题:给定当前 ,怎样得到更低噪声水平的 。
以确定性 DDIM 直觉为例:
这行式子不是把模型输出直接当最终图,而是把模型估计出的数据部分和噪声部分,按下一个噪声水平重新组合。若 离 很近,就是细步修正;若 跳得很远,就是少步采样,模型坐标和 sampler 误差都会被放大。
这就是“等价又不等价”的地方。数学上,很多预测目标可以互相换算;优化上,它们改变了每个噪声区间的损失尺度;推理上,它们又会影响 solver 在少 NFE、强 CFG、ControlNet 或视频长时生成里的稳定性。参数化不是符号偏好,而是训练几何和采样几何的连接件。
日程、参数化和采样器不能分开调
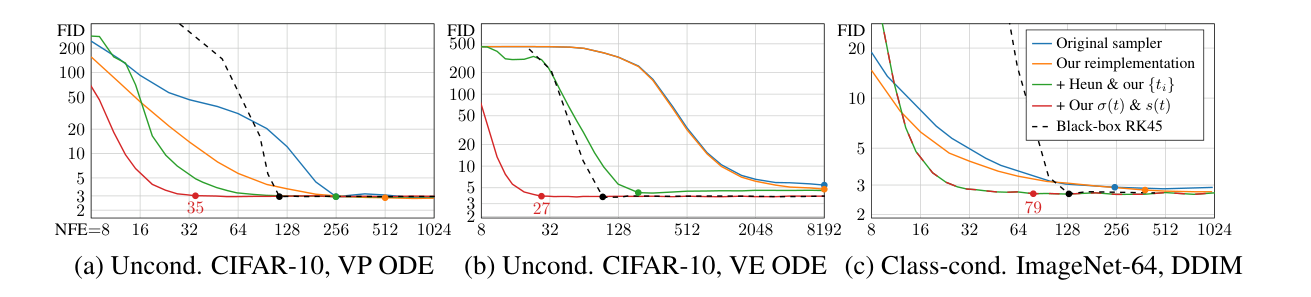
图源:Elucidating the Design Space of Diffusion-Based Generative Models,Figure 2。原图在多个预训练模型上比较确定性采样设计,横轴是 NFE,纵轴是 FID。本站读法:采样质量不是由模型权重或 sampler 名字单独决定;噪声尺度、preconditioning、时间离散、solver 和 NFE 共同决定少步表现。
EDM 的价值是把“训练目标”和“采样技巧”重新放回同一个设计空间。噪声尺度决定模型见过哪些状态,preconditioning 决定不同 下输入输出如何缩放,loss weighting 决定哪些噪声区间主导训练,sampler 决定推理时怎样走过这些区间。任何一项单独拿出来,都很容易过度简化。
真实训练和调参时,至少要一起记录这些信息:训练 noise schedule、timestep 或 采样分布、loss weighting、prediction type、是否 v-prediction、采样 schedule、solver、NFE、CFG scale、thresholding、分辨率和条件类型。少一个,复现实验时就可能把“模型更好”误判成“日程或采样器设置更顺手”。
怎么读不同场景里的日程选择
图像生成里,高噪声区负责大结构和语义,低噪声区负责纹理、边缘和文字。若模型常常“画得精细但主体错”,要检查高噪声区训练、caption/condition、timestep sampling 和 guidance;若构图对但细节脏,要检查低噪声区、VAE、loss weighting 和采样尾段。
视频生成里,噪声日程还会影响运动。高噪声区太弱,主体和镜头路线可能从一开始就不稳;低噪声区不够,纹理和身份会闪烁;少步采样跨度过大,运动可能变慢或断裂。Wan2.2 这类高低噪声专家路线,背后也在利用不同噪声区间承担不同职责这一事实。
动作扩散和世界模型里,日程选择还关系到多峰动作和反事实未来。过度强调平均 MSE 可能把多个可行动作平均成不可执行轨迹;高噪声区如果没有学到动作条件对未来的影响,采样再稳定也只是生成“看起来合理但不听动作”的 rollout。
收束判断
噪声日程控制训练题目的难度分布,参数化控制模型回答题目的坐标,采样器控制这些回答怎样变成实际轨迹。三者合在一起,才决定扩散模型在少步、强条件、视频和世界模型场景里是否稳定。
读论文或复现实验时,先问四件事:训练覆盖了哪些 SNR 区间;模型预测的是 、、score 还是 ;loss weighting 是否让某些噪声区间过强或过弱;推理 schedule 是否和训练 schedule 匹配。问清这四件事,noise schedule 就不再是配置文件里一串数字,而是模型学习难度和推理稳定性的核心接口。
外部精读
- DDPM:理解前向加噪、、噪声预测和反向链。
- Improved DDPM:理解 cosine schedule、learned variance、VLB 分项和训练/采样改进。
- Progressive Distillation:理解少步采样压力下的新参数化和 progressive distillation。
- EDM:理解噪声尺度、preconditioning、loss weighting、sampler 和 NFE 的整体设计空间。
- Min-SNR Weighting:理解按 SNR 调整 loss weighting 来缓解不同时间步优化冲突。
- Common Diffusion Noise Schedules and Sample Steps are Flawed:理解 zero terminal SNR、v-prediction 和 sampler 起点错配问题。
- Diffusers Scheduler Overview:核对工程库里的 scheduler / prediction type / timestep spacing 语义。
- The Annotated Diffusion Model:用代码和公式把 forward process、schedule、loss 和采样过程对上。
相关阅读与下一步
- 外部材料:Lil’Log:What are Diffusion Models?。
- 外部材料:DDPM 论文。
- 外部材料:Score SDE 论文。
- 站内下一步:扩散模型专题。
- 站内下一步:扩散方法对比表。
- 站内下一步:Score Matching、SDE 与 Probability Flow。
- Title: 扩散模型:噪声日程与参数化
- Author: Charles
- Created at : 2025-05-11 09:00:00
- Updated at : 2025-05-11 09:00:00
- Link: https://charles2530.github.io/2025/05/11/ai-files-diffusion-noise-schedules-and-parameterization/
- License: This work is licensed under CC BY-NC-SA 4.0.