
具身智能:从零路线:先把闭环跑起来
具身智能最容易被讲成“把 VLM 接到机器人上”。这个说法只说中了入口,没有说中系统。真实机器人要在带噪声、会变化、会损坏东西的世界里行动:它看到环境,估计状态,选择动作,执行后再看世界有没有按预期变化。如果没有,系统要能减速、重试、换策略或求助。
所以入门时不要先追模型名。先把一条闭环链路想清楚:
1 | 传感器 -> 状态表示 -> 任务理解 -> 策略/规划 -> 控制器 -> 执行动作 -> 新观测 |
VLM 主要解决“看见了什么、指令是什么意思”;VLA 进一步把视觉和语言接到动作;世界模型试图预测“这样做之后会发生什么”。但真正决定系统能不能落地的,往往是动作接口、坐标系、控制频率、数据口径、失败恢复和安全边界。
从抓杯子开始
假设任务是“把桌上的杯子拿起来”。模型不是直接从文字跳到成功状态,它至少要经历几层转换:相机看到桌面;感知模块估计杯子位置、姿态和可抓区域;策略决定夹爪从哪边接近;控制器把末端位姿或关节命令送给机器人;夹爪闭合后,系统还要判断杯子是否真的被抓稳。
这里每一层都有独立的失败方式。相机外参错了,目标点会落到桌面外;深度有噪声,夹爪可能撞到杯沿;策略没理解杯柄,抓点会不稳定;控制器延迟太大,实际轨迹会偏离计划;杯子滑落后,如果系统还按原轨迹执行,就会把一次小失误变成任务失败。
这就是闭环的意义。闭环不是“机器人会动”,而是系统能持续回答三个问题:当前状态是否可信;上一步动作是否产生了预期后果;下一步应该继续、修正、回退还是停止。具身智能的难点,正是这些问题会在真实时间和真实物理约束下同时出现。
VLA 只解决中间一段
RT-1 把图像、语言指令和历史动作放进 Transformer policy 里,输出离散化动作 token。它的价值在于证明大规模真实机器人数据可以训练一个跨任务的闭环控制模型,但它仍然依赖具体机器人数据、动作离散化和控制接口。
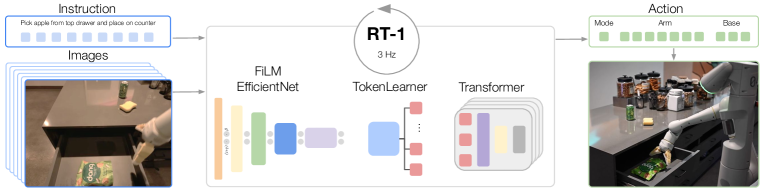
图源:RT-1: Robotics Transformer for Real-World Control at Scale,Figure 1。这里用它说明:机器人 Transformer policy 的输入不是单纯文本,而是图像、指令、历史动作和可执行动作空间的结合。
RT-2 把 web-scale VLM 的知识迁移到机器人动作上,让模型可以把视觉语言推理转成 action token。它让“语义泛化”变得更强,例如理解从机器人数据里很少出现的物体或任务描述。但它没有消除机器人数据瓶颈:模型仍要学会本机动作空间、控制频率、末端执行器限制和失败恢复。
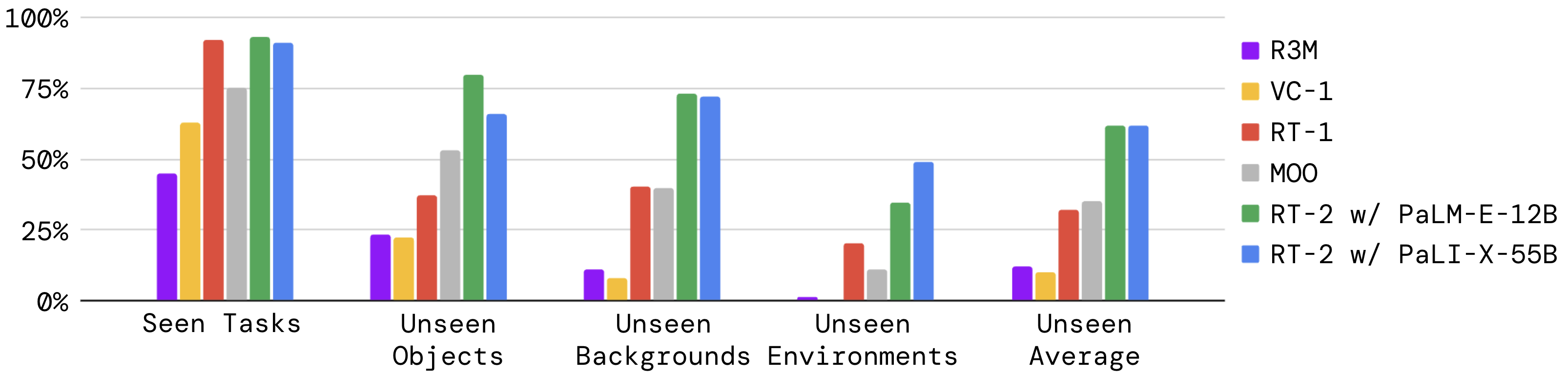
图源:RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control,Figure 1。这里用它说明:VLA 的关键不是“聊天模型更聪明”,而是把视觉语言预训练接到可约束的动作 token。
OpenVLA 这类开源 VLA 把路线进一步推向可复现和可微调:使用开放模型、Open X-Embodiment 机器人数据、低秩微调和量化部署,让更多团队能训练和适配 VLA。它对入门者的启发是:VLA 已经不只是概念,但复现能力仍取决于数据格式、动作解码、评测任务和硬件闭环。
数据接口比数据规模更早卡住
机器人数据贵,是因为真实采集慢、会损耗设备,还需要人工重置环境。机器人数据也窄:同一个实验室、同一种夹爪、同一个相机角度的数据,换桌面高度、光照或物体材质就可能失效。更麻烦的是接口不统一:不同机器人使用末端位姿、关节角、速度控制、夹爪开合或离散 action token;不同数据集的时间戳、相机标定和成功标准也不一样。
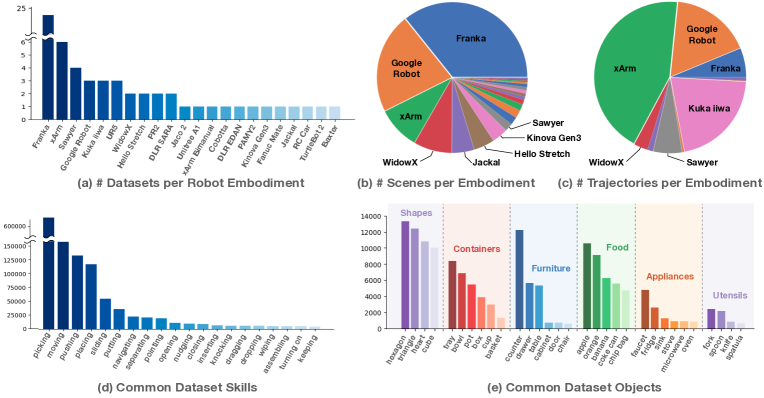
图源:Open X-Embodiment,Figure 1。这里用它说明:跨机器人数据的价值不只在规模,也在统一观测、动作、任务和评测格式。
读机器人数据集时,先看四件事。第一,观测来自单相机、多相机、深度、触觉还是 proprioception;第二,动作是末端位姿、关节空间、离散 token 还是 action chunk;第三,任务成功由脚本、人工、传感器还是视觉模型判定;第四,失败和 near-failure 有没有被保留下来。只看“多少条轨迹”会误导人,因为接口混乱的大数据会把控制噪声一起学进去。
动作表示决定策略上限
动作不是一个后处理细节。动作表示会决定模型能不能表达精细操作、能不能稳定闭环、能不能跨机器人迁移。
ACT 把一段未来动作作为 chunk 输出,适合低成本双臂模仿学习里的高频控制问题。它减轻了逐步预测的抖动,但 chunk 太长会削弱实时修正能力。Diffusion Policy 把动作序列看成条件扩散生成,适合多峰动作分布和高维动作空间;代价是推理和闭环控制要处理多步去噪、receding horizon 和时序一致性。
VLA 里的 action token、ACT 的 action chunk、Diffusion Policy 的动作轨迹扩散,解决的是同一个大问题的不同切面:如何把“我想做什么”变成机器人能执行、能纠错、能安全停止的动作接口。入门时把这个接口弄清楚,比背更多模型名更有用。
仿真要当成实验场,不要当成现实替身
仿真能便宜地产生数据、覆盖危险场景、复现实验和做失败回放。RoboTwin 这类 benchmark 说明,数字孪生和仿真任务可以让双臂操作评测更系统,也能生成真实采集难以覆盖的情形。
但 Sim2Real 的核心不是“仿真越逼真越好”,而是哪些差异会伤害当前任务。视觉任务更怕纹理、光照、反光和运动模糊;抓取任务更怕接触、摩擦、软物体和夹爪建模;导航任务更怕定位误差、动态障碍和地图变化。仿真数据进入训练前,要先问它会不会把错误的物理规律、错误的传感器噪声或过于干净的任务流程写进策略。
评测要按失败恢复来组织
具身评测不能只看一次成功率。一个系统 80% 成功但失败时会撞倒物体,和另一个系统 70% 成功但能可靠停下、重试、请求人工接管,部署含义完全不同。
更有用的评测口径是把任务拆成阶段:找物、定位、接近、接触、抓稳、移动、放置、恢复。每个阶段都记录失败类型、恢复次数、碰撞、超时、人工介入和任务成本。长时任务还要看状态记忆是否漂移,因为前面一个小错误可能在十几步后才暴露。
SayCan 的启发是,语言模型给出的“该做什么”必须被 affordance 或 value 信号约束:语义上合理的动作,不代表当前机器人在当前场景能做。世界模型的启发也类似:未来预测只有在能区分不同动作后果、能暴露风险、能改善 closed-loop success 时,才真正帮助机器人控制。
学习顺序
入门可以按五层走。第一层学传感器、坐标系、深度、相机外参和控制频率,因为这些决定状态是否可信。第二层学动作接口:末端位姿、关节空间、夹爪、action token、action chunk 和轨迹分布。第三层读 RT-1、RT-2、OpenVLA,理解 VLA 如何把视觉语言接到动作。第四层读 Open X-Embodiment、ALOHA / ACT、Diffusion Policy 和 RoboTwin,把数据、仿真、评测连起来。第五层再读 SayCan、Dreamer、action-conditioned video model 和具身世界模型,思考规划、风险和恢复。
读到任何新模型时,都用同一组问题检查:它输入哪些传感器;输出什么动作;控制频率是多少;是否闭环;失败样本怎么记录;是否跨机器人;是否真实执行;仿真和真实之间如何校验;安全层能否在模型失控时接管。能回答这些问题,才算真的读懂具身智能论文。
外部精读
- RT-1:理解大规模真实机器人数据如何训练 Transformer policy。
- RT-2:理解 web-scale VLM 知识如何迁移到 robot action token。
- Open X-Embodiment:理解跨机器人数据和 RT-X 模型的接口问题。
- OpenVLA:理解开源 VLA、微调和量化部署的现实边界。
- ALOHA / ACT:理解 action chunk 和双臂模仿学习。
- Diffusion Policy:理解用扩散模型表示动作轨迹分布。
- SayCan:理解语言规划为什么要被 affordance 约束。
- RoboTwin:理解仿真 benchmark 和双臂任务评测。
相关阅读与下一步
- 外部材料:RT-2 官方博客。
- 外部材料:Open X-Embodiment 论文。
- 外部材料:RoboTwin 项目。
- 站内下一步:具身智能专题。
- 站内下一步:具身智能从零路线。
- 站内下一步:Sim2Real 与具身数据引擎。
- Title: 具身智能:从零路线:先把闭环跑起来
- Author: Charles
- Created at : 2025-05-21 09:00:00
- Updated at : 2025-05-21 09:00:00
- Link: https://charles2530.github.io/2025/05/21/ai-files-embodied-ai-beginner-learning-path/
- License: This work is licensed under CC BY-NC-SA 4.0.