
具身智能:具身规划、控制与安全:高层动作为什么还要过安全层
具身智能最容易被误解成“给机器人一个更聪明的大脑”。现实里,机器人失败常常不是因为它不会理解指令,而是因为它没有及时刹住、没有在几毫米误差内插进孔、没有在遮挡或接触变化时重新规划。
这页只回答一个问题:为什么 VLA/WAM 输出动作后,仍然需要 planner、controller 和 safety filter。
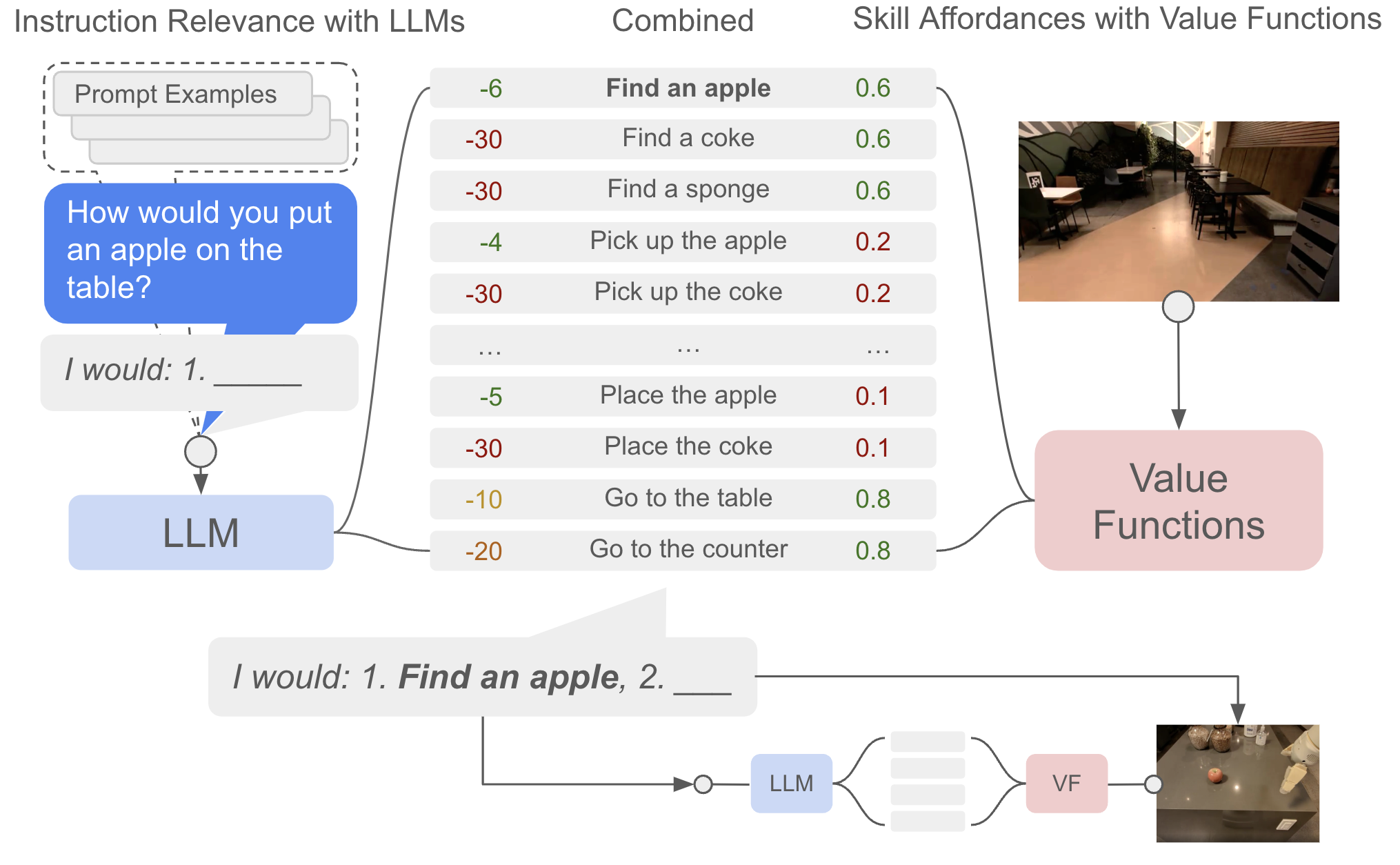
图源:Do As I Can, Not As I Say,Figure 3。原图展示语言模型分数和 affordance 分数如何组合。本站读法:高层语义判断“该做什么”,低层 affordance / value 判断“现在能不能做”。
三层分工
一个典型具身系统常拆成三层。任务层决定做什么,例如先找杯子、再抓取、最后放到水槽;规划层决定怎么走,把目标变成路径、阶段和候选动作;控制层决定每个时刻如何施力和执行,保证真实硬件稳定跟踪。
可以抽象成:
其中 是高层目标, 是未来 步参考路径或状态序列, 是真正下发给执行器的控制输入。大模型更适合处理 和子任务,控制器负责把 稳定变成 。
这说明具身智能不是经典控制被大模型替代,而是高层智能和低层控制明确分工。
MPC:每次只执行第一步
MPC, Model Predictive Control, 的直觉是先优化未来一小段,但每次只执行第一步,然后重新观测、重新规划。
目标函数可以写成:
这里 是系统状态,可能包括机器人位姿、速度、关节角或物体位置; 是控制输入,可能是速度命令、关节力矩或末端位姿增量; 是每一步代价,用来衡量偏离目标、碰撞风险、能耗或不平滑; 是终端代价,用来衡量规划窗口末端是否接近目标。
动力学约束写成:
这表示下一状态由当前状态和控制输入决定。MPC 会在这个约束下求一段最优控制:
但执行时通常只执行 ,然后拿到新观测再规划。这样系统能应对人突然走过来、物体位置变了、夹爪接触后物体滑动、仿真和真实摩擦不一致等情况。
控制:让真实状态跟上参考轨迹
规划层给出参考轨迹 ,控制器要让真实状态 跟上它。跟踪误差是:
最简单的线性反馈可以写成:
其中 是反馈增益。误差越大,控制输入越强地把系统拉回参考轨迹。真实机器人里会用 PID、MPC、阻抗控制、力控、全身控制等更复杂方法,但核心都是闭环反馈:不要只相信原计划,要用传感器不断校正。
接触任务尤其需要这层。插插头、拉抽屉、抓玻璃杯、拧瓶盖都不是纯几何路径问题。最后几毫米里,接触力、摩擦、顺应性和微小姿态误差会决定成败。
安全集合和安全投影
安全不是附加功能,而是第一约束。可以定义一个安全集合:
这里 是系统状态, 是安全函数。比如 可以表示离人手的最小距离减去安全阈值;当 时,状态在安全区域内。
如果模型给出候选动作 ,执行前可以投影到安全动作集合:
其中 表示投影, 是当前状态下允许执行的动作集合。直觉是:模型可以提建议,但真正发给执行器的动作必须满足工作空间、速度、力、碰撞和急停等硬约束。
控制障碍函数 CBF 更进一步,希望控制输入让系统持续留在安全集合内:
它的目标不是“事后发现危险”,而是在每个控制周期约束动作,使系统不要离开安全区域。人手伸进机械臂工作区时,系统不应该先完成高层任务,而应立即减速、后退或急停,确认安全后再重新规划。
VLA/WAM 输出后还缺什么
| 模型输出 | 还需要补什么 | 原因 |
|---|---|---|
| VLA action chunk | 坐标变换、碰撞检查、低层伺服、急停 | action chunk 不保证每个控制周期都安全 |
| WAM video-action chunk | 真实观测刷新、风险检测、安全过滤 | 错误未来会带着动作一起错 |
| World model ranking | planner / controller 投影 | 排名高的候选动作仍可能不可达 |
| 传统 planner 轨迹 | 执行器跟踪、接触反馈、失败恢复 | 几何可行不等于真实可执行 |
更稳的系统架构是:
1 | LLM / VLM / VLA planner |
模型越强,越需要把它能控制的边界写清楚。否则一个看似聪明的高层动作,可能在真实硬件上变成危险命令。
三个现实场景
送餐机器人拿到“去 3 号桌”的目标后,仍要处理行人、湿滑地面、急停距离和汤是否会洒。家庭机器人拿玻璃杯时,必须控制开门力度、夹爪力和放置速度。仓储机械臂高速分拣时,吞吐压力会压缩安全裕量,系统必须在速度、稳定性和碰撞风险之间动态折中。
这些例子里,高层计划可能完全正确,低层执行仍可能失败。规划告诉系统未来该往哪走,控制保证它真能走上去,安全决定它在异常情况下不把事情搞坏。
外部精读
- SayCan:理解语言目标和可执行性为什么要组合。
- Control Barrier Functions: Theory and Applications:理解 CBF 如何把安全约束接入控制。
- cuRobo:理解运动规划、IK、碰撞检查和轨迹优化在机器人栈里的位置。
- π0.5:理解现代 VLA 的动作 chunk 为什么仍需要控制层。
- DreamZero:理解 WAM 输出动作后为什么仍需要真实观测刷新和安全过滤。
相关阅读与下一步
- 外部材料:RT-2 官方博客。
- 外部材料:Open X-Embodiment 论文。
- 外部材料:RoboTwin 项目。
- 站内下一步:具身智能专题。
- 站内下一步:具身智能从零路线。
- 站内下一步:Sim2Real 与具身数据引擎。
- Title: 具身智能:具身规划、控制与安全:高层动作为什么还要过安全层
- Author: Charles
- Created at : 2025-06-02 09:00:00
- Updated at : 2025-06-02 09:00:00
- Link: https://charles2530.github.io/2025/06/02/ai-files-embodied-ai-planning-control-and-safety/
- License: This work is licensed under CC BY-NC-SA 4.0.