
具身智能:Sim2Real 与具身数据引擎
具身智能最终一定会撞上一堵墙:
仿真里一切顺利,真实世界里系统却开始抓空、打滑、误判、抖动、卡住。
这堵墙就是 sim2real gap。
而真正把这堵墙慢慢填平的,往往不是某个单独模型,而是一整套数据引擎。
Open X-Embodiment 的数据集总览图很适合解释为什么具身智能需要数据引擎:不同机器人本体、场景、技能和物体分布差异很大,真实系统不能指望单一仿真或单一实验室数据覆盖所有长尾。
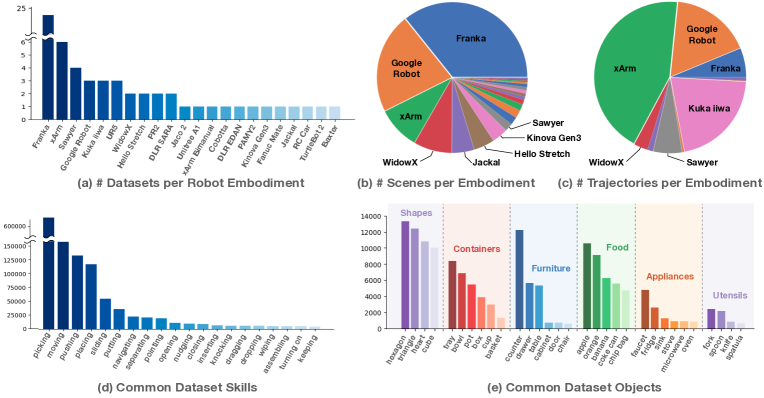
图源:Open X-Embodiment: Robotic Learning Datasets and RT-X Models,Figure 1。原论文图意:统计 Open X-Embodiment 中不同 robot embodiment、scene、trajectory、skill 和 object category 的分布,展示跨机器人数据的异质性。
图里的柱状图和饼图说明,机器人数据不是一个均匀大表:不同机械臂、场景、技能和物体类别的覆盖差异很大。Sim2Real 不是“仿真一次训好,然后直接上真机”,而是仿真、真机验证、失败样本回流、参数校准和再训练组成的闭环。域随机化解决“别对单一仿真过拟合”,System ID 解决“把关键物理参数调准”,数据引擎解决“真实失败如何变成下一轮能力”,三者不要互相替代。
具身数据引擎的价值不是收集更多随机轨迹,而是把真实失败变成下一轮训练材料。失败样本、恢复轨迹和参数校准往往比普通成功样本更值钱。
只看进球录像,学不到为什么会投偏。教练更关心偏左、偏短、出手慢这些失败模式。Sim2Real 数据引擎也是把真实失败分类、回放、修正,再放回训练。
0.1 从 π0.5 和 DreamZero 看数据引擎
不同论文路线对数据的要求不同。把它们放在一起看,会更容易理解“为什么具身智能不是只收更多轨迹”。
| 路线 | 最需要的数据 | 数据为什么这样组织 |
|---|---|---|
| π0.5 式 VLA | web 多模态数据、跨机器人数据、移动操作数据、高层子任务、人类 verbal instruction | 目标是让模型既懂开放世界语义,又能把语义拆成子任务和动作 chunk |
| DreamZero 式 WAM | 对齐的视频、动作、本体状态、多样非重复机器人轨迹 | 目标是联合学习未来视频和未来动作,让动作解释视觉变化 |
| LingBot-World 式模拟器 | 通用视频、交互轨迹、动作/相机控制、长序列续写数据 | 目标是把视频生成器训练成动作条件、可 rollout 的世界模拟器 |
| 仿真资产/轨迹 pipeline | 标准资产、物理参数、grasp pose、success checker、planner GT | 目标是低成本生成可控任务、专家轨迹和失败样本 |
所以 Sim2Real 数据引擎要先确定服务哪条路线。给 VLA 的数据要重视动作监督和任务语义;给 WAM 的数据要重视视频-action 对齐;给传统 planner baseline 的数据要重视几何、碰撞和判定脚本。混在一起收集,后面很难解释模型到底学到了什么。
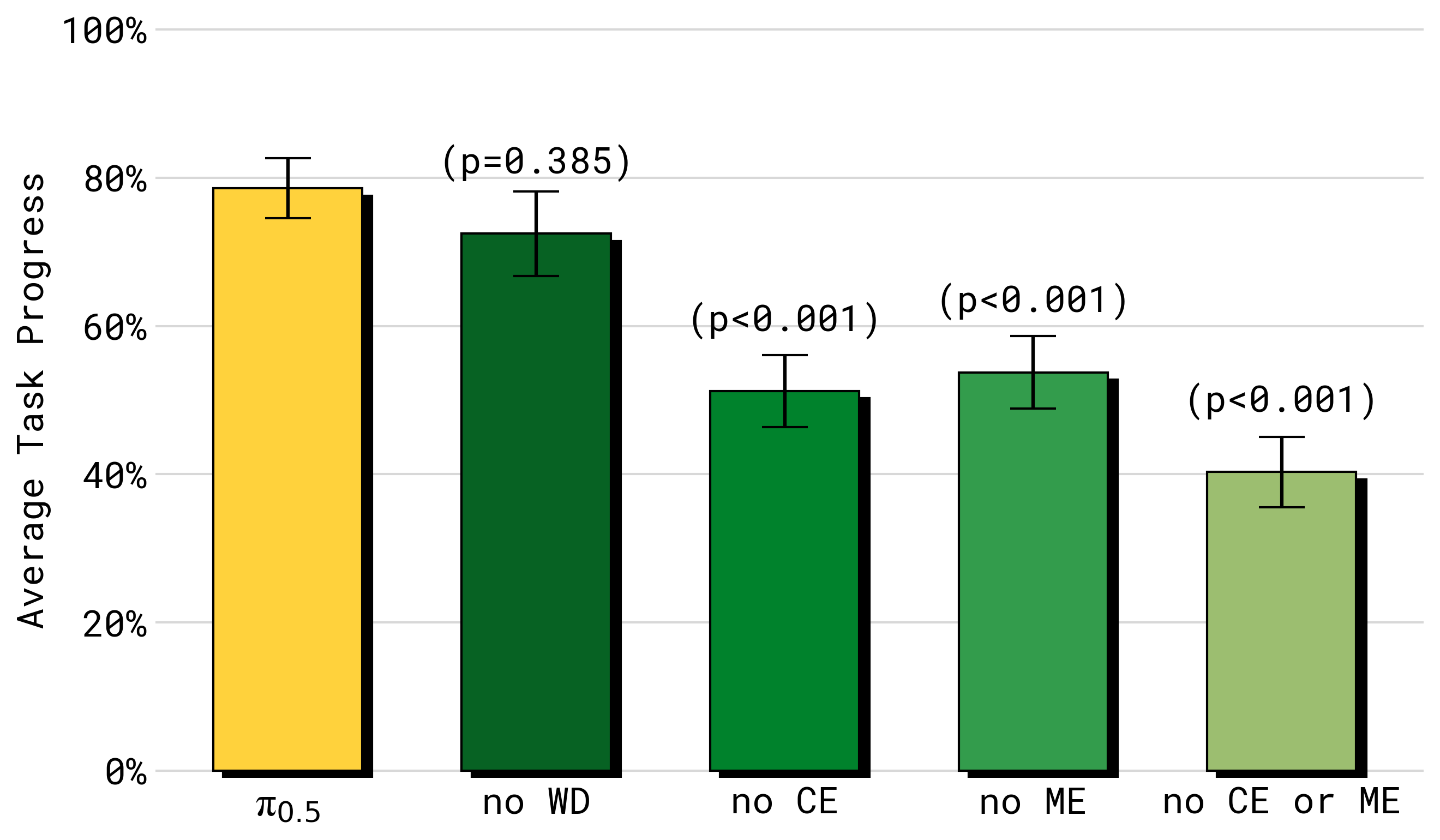
图源:π0.5,Figure 10。原论文图意:比较去掉 web data、cross-embodiment data、multi-environment data 等不同数据源后,in-distribution 和 OOD 任务表现如何变化。
这张 ablation 图说明,数据 recipe 会决定模型在哪些场景泛化。Web data 更像补开放世界语义,cross-embodiment / multi-environment robot data 更像补动作和场景泛化。做 Sim2Real 回流时,也要问每一类失败样本补的是语义、视觉、动作、动力学还是评测盲区。
1. Sim2Real gap 到底是什么
设仿真环境分布为 ,真实环境分布为 。
理想情况是训练和部署分布一致,但现实里往往:
差异来源很多:仿真光源通常太干净,真实环境会有阴影、反光和色温变化;玻璃、金属、塑料等材质会出现仿真没覆盖的高光;焦距、畸变、相机位置或标定误差会改变视觉观测;摩擦、刚度、质量、重心和接触模型不准,则会让同一动作在真实世界里产生完全不同的结果。
这意味着:
即使策略在仿真分布上最优,到了真实分布也可能明显退化。
2. 域随机化:先承认你不可能把仿真调到完全真实
Domain Randomization 的核心不是“把仿真变真”,而是“让策略对仿真的不准确性不敏感”。
在仿真中随机化环境参数 :
常见随机化包括光照强弱、材质纹理、相机噪声、摩擦系数、物体尺寸和质量、背景干扰。它们的共同目标不是让画面更花,而是避免策略把单一仿真条件当成隐含规律。
于是训练目标变成在一个参数分布上做鲁棒优化:
直觉上,策略不是只适应“一间完美实验室”,而是适应一批略有差异的世界。
3. 一个直观例子:抓红色积木
如果仿真里永远是白色桌面、固定顶灯、纯正积木颜色和无噪声相机,模型就容易把这些干净条件当成隐含前提。
那么策略会很容易学会一种“脆弱的成功”。
一到真实世界里,下午阳光偏黄、桌面有反光、相机有运动模糊,它就开始失效。
做域随机化后,仿真会主动加入偏暖色灯光、桌面纹理变化、镜头模糊和轻微位姿扰动,逼策略学习更稳健的视觉和抓取线索,而不是记住一间完美实验室。
这样它学到的就更可能是真正稳健的视觉特征。
4. 域随机化并不只针对视觉
很多团队一提 sim2real 就只想到画面风格,但机器人里同样重要的是动力学随机化:
这里:
- :质量,影响搬运、加速度和抓取稳定性。
- :摩擦系数,影响滑动、推拉和夹持是否可靠。
- :接触或阻尼参数,影响碰撞、柔顺性和振动衰减。
如果这些参数在仿真里过于固定,策略会对一套理想动力学过拟合。
真实部署时,只要物体重一点、滑一点,就可能失败。
5. System Identification:另一条路线是把仿真调准
与其随机到足够广,也可以尽量估计真实系统参数,让仿真更接近现实。
这类方法本质是在求:
其中 是轨迹, 是某种轨迹差异度量。
现实中常常不是“只做域随机化”或“只做 system ID”,而是先用真实轨迹校准质量、摩擦、相机等中心参数,再围绕这些中心值随机化,承认真实世界仍会有长尾变化。
6. 仅靠仿真不够,必须有数据引擎
现代机器人系统往往不是一次性训练,而是“部署、收集失败、重新标注筛选、回灌训练、再部署验证”的闭环。数据引擎真正管理的,就是这个循环。
可以把它抽象为:
其中 是本轮部署中收集到的高价值新样本,通常包括抓空、碰撞、卡住等失败样本,接近失败但尚未失败的边界样本,训练集中覆盖少的稀有场景,以及人工接管或遥操作修正轨迹。
7. 为什么失败样本比成功样本更值钱
如果系统只看成功演示,它会不断强化“在容易场景里成功”的能力。
但真实部署中的瓶颈往往正是那些失败和近失败场景。
例子:分拣流水线
起初机器人总在透明塑料包装上抓空。
如果你只继续收更多普通纸盒成功案例,模型提升有限。
真正有用的是把这些失败样本回流,并有意识地补透明包装、高反光表面、局部遮挡、塌陷或变形包装这类难例。下一轮策略通常才会明显改进。
下一轮策略通常才会明显改进。
8. 数据引擎里最难的是“选什么回流”
不是所有线上样本都值得回流。
若全量回流,数据很快被海量平庸样本淹没。
更有效的是做主动筛选,优先回流低置信动作、任务失败、人工接管、碰撞边缘和 OOD 视觉场景。它们比普通成功片段更能指出下一轮训练该补哪里。
可把样本价值粗略记作:
然后优先标注高 样本。
9. Sim2Real 不只是训练问题,也是评测问题
如果评测集只来自实验室条件,系统会产生“已经很好”的错觉。
真正有价值的评测应覆盖光照变化、物体材质变化、相机偏差、背景杂乱、人类干扰和接触异常。这样才能测试系统是否只适应干净实验室,还是能处理真实部署里的长尾。
一个直观例子:家庭机器人收纳
实验室里物品摆放规整、柜门开合角固定、地面无遮挡;真实家庭里却可能玩具散落、透明盒子反光、柜门半开、桌角有阴影。
如果评测不包含这些变化,你得到的上线置信度基本是虚的。
10. 四种常见数据来源
| 数据来源 | 价值 | 主要风险 |
|---|---|---|
| 仿真数据 | 成本低、可大规模生成、可自动标注状态和成功信号 | 视觉、动力学和接触模型总会有分布偏差 |
| 遥操作示范 | 轨迹质量高,语言目标、阶段动作和成功标准更容易对齐 | 采集、清洗和同步多传感器数据很贵,长尾覆盖有限 |
| 自动运行日志 | 最贴近真实部署,碰撞、接管、卡住和低置信动作会自然暴露 | 噪声大,全量回流会淹没高价值长尾 |
| 人工纠正与接管数据 | 直接反映原策略错在哪里,以及人类如何恢复 | 需要同步原始观测、人工动作、失败原因和恢复结果 |
11. 三个真实场景
11.1 家庭服务机器人
难点不在“拿杯子”这句话,而在玻璃、陶瓷、塑料的反光和受力完全不同,桌面杂乱会影响路径规划,光照随机变化会干扰视觉识别,人还可能随时插手或改变任务。
这种场景极依赖数据引擎,而不是只依赖一套离线静态数据集。
11.2 仓储拣选
货物种类变化快,包装反光、遮挡、堆叠关系都在变。
仿真可覆盖基础几何,但真正稳定上线,需要持续从真实流水线回流错误案例。
11.3 机械装配
这里 sim2real 的难点更多来自接触动力学。
视觉随机化帮助有限,反而需要更准的力学参数、更高质量真实接触数据和更细粒度失败标签,才能区分卡住、未对准、力过大和姿态错误。
12. 常见失败模式
12.1 仿真指标很好,真实几乎不可用
通常说明随机化范围不够、动力学模型过度理想化,或相机、光照、材质和背景与真实环境差异过大。
12.2 数据回流很多,但能力不涨
常见原因是回流样本价值低、标注噪声大,或失败类型未区分。抓空、打滑、遮挡和规划错被混在一起时,很难定向改进。
12.3 只做视觉随机化,不做动力学随机化
结果是看得更稳,但一接触就错。
12.4 只关注平均成功率
平均分上升,不代表那些最关键的长尾场景被解决了。
13. 工程判断
很多具身任务真正稀缺的不是模型,而是高质量、闭环、带失败标签的数据。
如果没有持续回流和筛选机制,sim2real 几乎不可能靠一次训练彻底解决。
更实用的路线通常是用仿真做冷启动,用随机化拓宽鲁棒性,用真实部署数据回流补长尾,再用评测集持续跟踪 sim2real gap。
14. 总结
Sim2Real 不是一个单点技术问题,而是一条持续运营的问题链。
域随机化帮助策略“别太脆”,system identification 帮助仿真“别太假”,而数据引擎负责把真实世界的失败不断带回训练环。
真正强的具身系统,往往不是一开始就完美,而是能通过这套闭环越来越接近真实世界。
快速代码示例
1 | import random |
这段代码示意了 Sim2Real 的两件基础工作:训练时做域随机化,回流时提升失败样本优先级。它对应“先让策略有鲁棒性,再让数据引擎把真实失败持续喂回训练”的闭环思路。
工程收束
Sim2Real 的重点不是把仿真做得“像照片”,而是让仿真覆盖真实世界最容易出错的变量,并让实机失败能回流成下一轮随机化、校准和 hard set。域随机化负责提前见过变化,数据引擎负责把没见过的变化补回来。
- Title: 具身智能:Sim2Real 与具身数据引擎
- Author: Charles
- Created at : 2025-06-13 09:00:00
- Updated at : 2025-06-13 09:00:00
- Link: https://charles2530.github.io/2025/06/13/ai-files-embodied-ai-sim2real-and-data-engines/
- License: This work is licensed under CC BY-NC-SA 4.0.