
基础知识:自动微分与激活显存
训练大模型时,显存压力往往不是权重单独造成的,而是权重、梯度、optimizer state 和中间激活一起造成的。自动微分让训练变简单,也带来了保存计算图和激活的显存成本。
这页先回答“自动微分与激活显存”在「基础知识」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先看本页要补哪一个最小概念;公式或术语卡住时回到术语表,不需要一次吃完整个数学体系。 必要时先回 基础知识入口 或 术语表。
主线关系:把符号、张量、优化、评测和运行时这些前置打稳,后面的扩散、VLM/VLA、训练与系统页才不会断层。
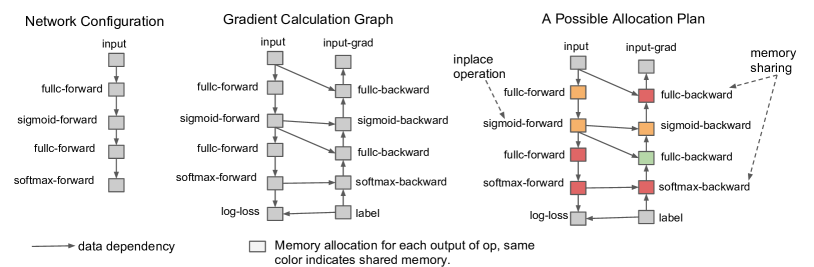
图源:Training Deep Nets with Sublinear Memory Cost,Figure 1。原论文图意:把神经网络前向计算表示成有向计算图,反向传播时需要中间节点的值;若不保存全部中间值,就需要在 backward 前重新计算部分节点。
这张图把训练看成一张计算图:前向时每个节点产生中间激活,反向时梯度需要沿图反传并读取这些激活。全保存最省计算但占显存;activation checkpointing 只保存少数关键节点,反向时从最近 checkpoint 重新跑一段前向,换回缺失激活。训练显存不够时,不一定先换模型,可以先看 checkpointing、batch size、sequence length、ZeRO/FSDP、低精度和重算策略。
推理只要算出答案,训练还要记住“答案是怎么来的”,这样 backward 才能算 gradient。显存压力很多时候不是权重本身,而是中间激活、梯度和 optimizer state 一起叠加。看到训练 OOM 时,先估计这几类状态谁是主因,再决定是 checkpointing、ZeRO/FSDP、offload 还是降 batch。
同一模型推理能跑、训练一开就 OOM,activation checkpointing 后吞吐掉得过多,或者恢复训练后梯度和数据游标对不上时,回看本页。本页能帮你判断显存该从 activation、optimizer state、重算策略还是 checkpoint 恢复语义入手。
符号卡:自动微分里的几个词
| 符号或词 | 含义 |
|---|---|
| forward | 从输入算到 loss 的过程 |
| backward | 从 loss 把梯度传回参数的过程 |
| activation | 前向中间结果,反向常要用 |
| checkpoint | 被刻意保存下来的中间节点 |
| recompute | 反向时重新计算丢掉的激活 |
| loss 对参数的偏导数 | |
| optimizer state | AdamW 等优化器保存的动量、二阶矩等状态 |
推理只需要 forward;训练需要 forward、保存或重算激活、backward 和 optimizer update。因此训练显存通常明显高于推理。
自动微分在做什么
现代框架会记录前向计算图,然后自动根据链式法则计算梯度。
1 | y = model(x) |
这背后会记录:
- 哪些张量参与了计算;
- 每个算子的 backward 规则;
- backward 时需要哪些中间值;
- 梯度应该累积到哪些参数上。
为什么训练比推理更占显存
推理只需要前向输出,训练还需要保存反向传播所需状态。
| 项目 | 推理 | 训练 |
|---|---|---|
| 权重 | 需要 | 需要 |
| 中间激活 | 通常可释放 | 需要保存或重算 |
| 梯度 | 不需要 | 需要 |
| optimizer state | 不需要 | AdamW 通常需要额外状态 |
| checkpoint | 可选 | 必须治理 |
AdamW 训练中,单个参数可能对应权重、梯度、一阶动量、二阶动量等多份状态,因此训练显存通常远高于推理。
Activation Checkpointing 的核心折中
Activation checkpointing 的思想是:前向时不保存所有中间激活,只保存少数 checkpoint;反向时重新计算丢掉的激活。
它用更多计算换更少显存。
1 | Forward: |
这在大模型训练中非常常见,尤其是长上下文、多模态和视频模型。
一个简单例子
假设有 6 层网络:
1 | x -> L1 -> L2 -> L3 -> L4 -> L5 -> L6 -> loss |
不做 checkpoint 时,可能保存每一层激活。
做 checkpoint 时,只保存 、、 的输出。反向传播到 时,再从 重新计算 、。
这样显存下降,但训练时间会上升。
训练显存账:为什么长视频最先爆
flowchart LR
A["Forward"] --> B["保存必要激活"]
B --> C["Loss"]
C --> D["Backward"]
D --> E["读取激活 / 重算激活"]
E --> F["梯度"]
F --> G["Optimizer state"]
G --> H["参数更新"]
I["Activation checkpointing"] --> E
J["FSDP / ZeRO"] --> G
以一个多相机视频 VLA batch 为例:B=2、4 路相机、16 帧、每帧 1024 个视觉 token、hidden size 1024、BF16。仅视觉 token 激活一层就是:
如果模型有几十层,并且反向传播需要保存多种中间激活,显存会迅速超过权重本身。这也是为什么视频世界模型训练经常要组合使用 gradient checkpointing、短长 horizon 混合、视觉 token 压缩、activation offload 和序列并行。
| 手段 | 省什么 | 代价 |
|---|---|---|
| Activation checkpointing | 中间激活 | 反向重算,step time 增加 |
| 降低视觉 token | 激活、attention、KV | 可能丢小物体和接触线索 |
| Sequence / context parallel | 长序列激活分摊 | 通信和实现复杂 |
| ZeRO/FSDP | 参数、梯度、optimizer state | 通信与恢复语义更复杂 |
| Offload | GPU 显存 | PCIe/NVMe 带宽和尾延迟 |
显存排查顺序
遇到 OOM 时,可以按下面顺序检查:
- batch size 是否过大;
- sequence length 或图像分辨率是否过高;
- activation checkpointing 是否开启;
- 是否使用 BF16/FP16/FP8 等混合精度;
- optimizer state 是否可分片;
- 是否需要 ZeRO、FSDP、TP/PP/CP;
- 数据加载或缓存是否意外占显存。
和后续专题的关系
- 训练稳定性:理解 OOM、NaN、梯度异常。
- 分布式训练与 Checkpoint:理解恢复语义和状态分片。
- Megatron、DeepSpeed 与训练栈:理解 ZeRO、TP、PP、CP。
- 数值、显存与运行时:理解显存、dtype 和 runtime 的关系。
本页结论
自动微分让训练更容易,但训练系统必须为计算图和中间激活付出显存代价。Activation checkpointing 是最常见的折中:少存一点,多算一点。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:数据划分与评测指标。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:自动微分与激活显存
- Author: Charles
- Created at : 2025-06-16 09:00:00
- Updated at : 2025-06-16 09:00:00
- Link: https://charles2530.github.io/2025/06/16/ai-files-foundations-autograd-activation-checkpointing-and-memory/
- License: This work is licensed under CC BY-NC-SA 4.0.