
基础知识:线性层、MLP 与 GEMM:模型里的矩阵乘为什么这么重要
这篇文章只回答一个问题:为什么大模型系统优化经常绕不开 Linear、MLP 和 GEMM。
最短答案是:Transformer 里大量参数、FLOPs、量化收益、张量并行切分和低精度 kernel,都集中在线性层。Linear 在模型语义上是“把每个 token 的表示投影到新通道空间”;在数学上是矩阵乘;在硬件上通常会落到 GEMM 或 fused GEMM。把这三层分清,后面读量化、推理 runtime、Megatron、CUTLASS、Triton 和 DeepGEMM 才不会混成一团。
Linear 改的是每个 token 的通道表示
最常见的线性层公式是:
如果输入是文本 hidden states:
那么输出是:
这里 是 batch size, 是 token 数, 是输入 hidden dimension, 是输出 hidden dimension。Linear 不会自己让第 3 个 token 读取第 9 个 token;它只是对每个 token 的最后一维做同一套通道变换。Token 之间的信息混合主要来自 attention、convolution、SSM 或其他序列模块。
PyTorch 的 nn.Linear(in_features, out_features) 在 API 里把权重存成 [out_features, in_features],前向等价于:
这和教学里写 不矛盾,只是内存布局和 API 约定不同。读代码、导出 ONNX、做 LoRA merge、写 quantized kernel 时,必须分清“论文公式里的权重方向”和“框架里实际存储的 weight layout”。
MLP 是逐 token 的非线性通道变换
Transformer block 里除了 attention,另一个大计算块就是 MLP / FFN。最朴素写法是:
其中 常把 升到 , 常见为 4 或更高; 是 GELU、SiLU、SwiGLU 里的激活或门控; 再把维度压回 。这像一个临时工作台:先把每个 token 的通道展开,在更大的中间空间里做非线性筛选,再压回 residual stream。
Transformer 的常见 Linear 可以这样定位:
| 位置 | 改什么 | 常见 shape |
|---|---|---|
| Q/K/V projection | 为 attention 生成 query、key、value | |
| Attention output projection | 合并多头输出 | |
| MLP up / gate / value projection | 扩张并筛选通道 | |
| MLP down projection | 回到 residual stream | |
| LM head | hidden 到 vocab logits | $D\rightarrow |
所以一个 Transformer block 的 FLOPs 大头通常不是一个神秘模块,而是一连串大矩阵乘。Attention 负责 token-token 信息读取,MLP 负责 token 内部通道变换;二者都严重依赖 Linear 的执行质量。
Linear 运行时会展平成 GEMM 的 M/N/K
底层 GEMM 常写成:
这里 是 dense matrices, 是标量。把 Linear 落到 GEMM 时,框架常把前面的 batch 和 token 维展平:
对应关系是:
这三个字母是读性能的入口。 是这次同时处理多少 token 行, 是输入通道宽度, 是输出通道宽度。GEMM 的乘加量近似是:
这里的 2 来自一次乘法和一次加法。这个估算不是端到端 latency,但能告诉你哪几个维度会线性放大计算。
Prefill 和 decode 的差异也在 。Prefill 时 prompt 很长, 通常较大,GEMM 更容易跑满 Tensor Core。Decode 时每步只来新 token, 可能很小,瓶颈会从“大吞吐矩阵乘”变成 small-M GEMM、launch overhead、KV cache 读取、dequant 和 runtime dispatch。许多“离线 benchmark 很快,线上 decode 不明显”的问题都出在这里。
GEMM 快不快取决于数据流,不只取决于 FLOPs
Triton 论文里的 roofline 图很适合作为第一张硬件直觉图。
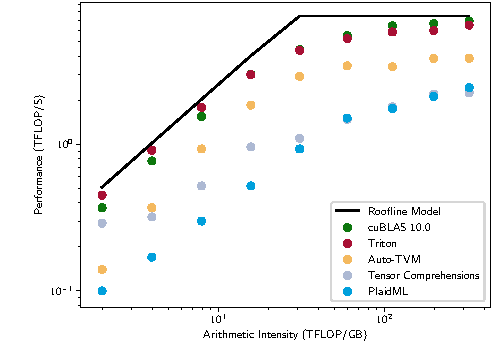
图源:Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations,Figure 1。原图比较 cuBLAS、Triton、Auto-TVM、Tensor Comprehensions 和 PlaidML 在矩阵乘 上相对 roofline model 的性能。本站使用这张图说明:GEMM 性能不仅取决于算术量,也取决于数据复用、访存和 kernel 实现能否接近硬件上限。
Roofline 的横轴是 arithmetic intensity,也就是每搬运一单位数据能做多少计算;纵轴是性能。低 intensity 时,瓶颈常在带宽;高 intensity 时,瓶颈才更接近算力上限。GEMM 之所以适合加速器,是因为 tiling 可以让一小块 和 在 shared memory、cache 或 register 里反复复用,避免每个输出元素都从 HBM 重新读完整数据。
一个高性能 GEMM 大致会做四件事:
| 阶段 | 它在优化什么 |
|---|---|
| Tiling | 把 切成适合 threadblock / warp / MMA 指令的块 |
| Data movement | 把 分块搬进 shared memory、register 或 TMA pipeline |
| Accumulation | 用 Tensor Core / MMA 在 accumulator 里累加 |
| Epilogue | 写回 ,并可能融合 bias、activation、scale、dequant、requant、residual |
这就是为什么同一个数学矩阵乘,在 cuBLAS、cuBLASLt、CUTLASS、Triton、DeepGEMM 或 TensorRT 里会有不同实现。它们争的不是公式,而是 tile、layout、dtype、epilogue、调度和目标硬件。
Epilogue fusion 决定 Linear 后面会不会多搬一次数据
深度学习里的 Linear 很少只有 。它后面常接 bias、GELU、SwiGLU、residual、dropout、quant/dequant 或 scale。若 GEMM 先把结果写回 HBM,再由另一个 kernel 读出来做激活,就会多一次读写和 launch。
Fused epilogue 的价值是把这些轻量操作接在 GEMM 写回之前完成。例如:
1 | acc = matmul(x, W) |
如果拆成多个 kernel,acc 可能会被写回再读入;如果融合在 epilogue,accumulator 可以尽量留在 register 或更近的存储层里处理。CUTLASS 和 cuBLASLt 都把 epilogue 当成重要设计点,原因就在这里。
这也解释了量化为什么不一定提速。INT4 权重如果先解包/反量化成 FP16,再走普通 GEMM,文件小了,但 dequant 和布局转换可能吃掉收益。真正有用的低比特路径通常要把 unpack、scale 读取、dequant 和 matmul 尽量融合到同一个 kernel 或短路径里。
Megatron 为什么按 Linear/GEMM 切并行
大模型训练中,单卡放不下或算不动时,会把 Linear 的大矩阵切到多张卡上。Megatron-LM 的 MLP tensor parallel 图就是经典例子。
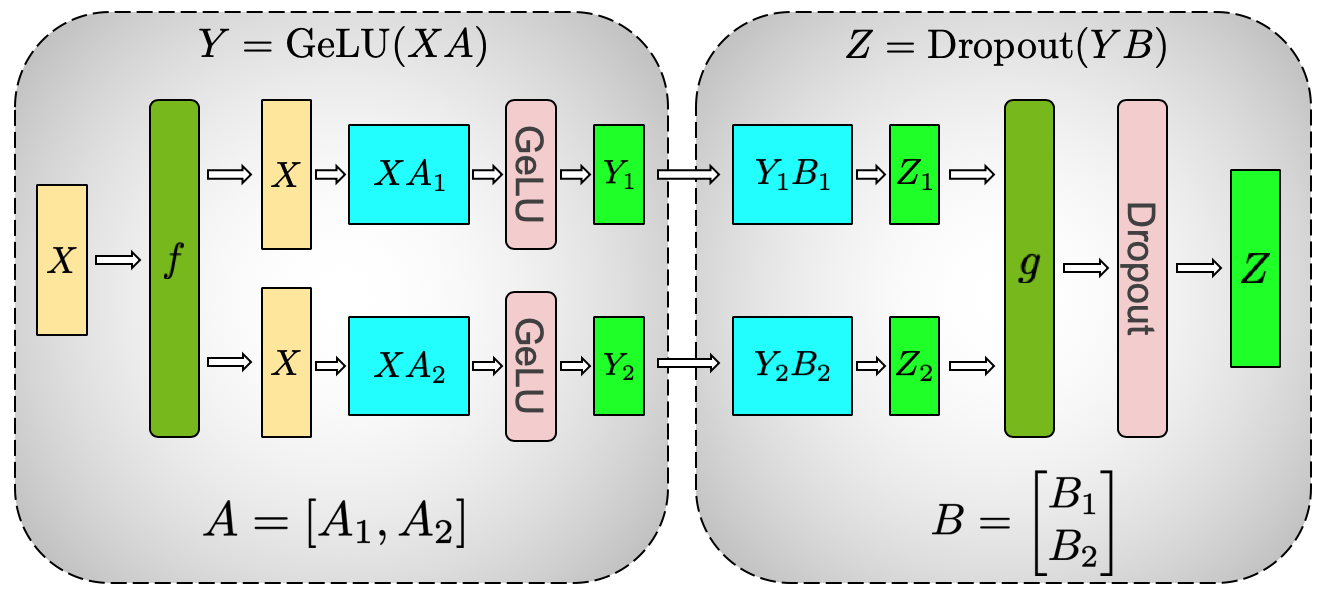
图源:Megatron-LM,Figure 3a。原图表达 MLP 第一层按列切分 ,各 GPU 本地计算 和 GeLU;第二层按行切分 ,最后通过通信合并输出。本站使用这张图说明:张量并行不是抽象切模型,而是在切 Linear/GEMM 的矩阵维度和通信位置。
第一层 按 的输出列切分,每张 GPU 得到一部分中间通道,可以本地做 GeLU。第二层 按输入行或中间通道切分,各 GPU 计算部分输出贡献,最后做 all-reduce 合并。这个设计的关键是把通信放在少数必要位置,而不是每个小操作后同步。
这张图也提醒你:MLP 里的 Linear 不只是“模型层”,还是分布式系统里的切分对象。hidden size、intermediate size、tensor parallel size、activation function 和通信拓扑都会影响训练吞吐。
读 Linear 性能时先问六件事
| 问题 | 为什么重要 |
|---|---|
| 当前是 prefill、decode、训练还是离线 batch? | 维和复用方式完全不同 |
| 分别是多少? | 决定 GEMM shape、tile 和 Tensor Core 利用 |
| weight layout 和 transpose 是否匹配 kernel? | 转置、contiguous 和 layout transform 可能隐藏成本 |
| dtype 是 BF16、FP8、INT8、INT4 还是 FP4? | 决定是否命中硬件和低比特 kernel |
| epilogue 是否融合 bias / activation / dequant / residual? | 不融合会增加 HBM 读写和 kernel launch |
| 端到端热点是否真在 GEMM? | 小算子、KV cache、通信、dispatch 也可能主导 |
不要只看单 kernel TFLOP/s。一个 GEMM microbenchmark 很漂亮,不代表线上服务就快;一个 Linear 参数量很大,也不代表它是当前 trace 的瓶颈。真正稳的做法是先在 trace 里定位热点,再把热点 GEMM 的 、dtype、layout、epilogue 和调用阶段写清楚。
容易误读的地方
| 误解 | 更准确的说法 |
|---|---|
| Linear 就是矩阵乘,所以都一样 | 模型语义、API MatMul 和 kernel GEMM 是三层不同抽象 |
| FLOPs 少就一定快 | layout、dtype、tile、launch、epilogue 和 HBM 读写都会改变 latency |
| Prefill 快说明 decode 也快 | Decode 常是 small-M GEMM + KV 读取 + dispatch 问题 |
| 量化权重小就一定提速 | 没有 fused low-bit GEMM 时,dequant 可能吃掉收益 |
| GEMM 是唯一瓶颈 | Norm、softmax、rope、gather/scatter、通信和 KV cache 都可能拖慢 |
| Tensor parallel 只是把模型切开 | 它具体是在切 Linear/GEMM 的矩阵维度,并安排通信 |
读完以后怎么判断
Linear 是每个 token 的通道投影,MLP 是逐 token 的非线性通道变换,MatMul 是数学/API 操作,GEMM 是硬件执行里的 dense matrix multiply 家族。真正的系统问题发生在这些层之间:shape 怎么展平为 ,prefill 和 decode 的 怎么变,weight layout 是否匹配 kernel,epilogue 能否融合,低比特 scale 是否顺路读入,张量并行在哪里通信。
以后读任何 Transformer、量化、推理 runtime 或训练并行论文时,看到 Linear 不要只划过去。把它翻译成一次具体 GEMM: 是多少, 是多少, 是多少,dtype 是什么,后面融合了什么,在哪个阶段运行。很多性能和显存问题就会立刻变得可解释。
外部精读
- PyTorch
nn.Linear:确认真实 API、weight shape 和前向定义。 - NVIDIA cuBLAS documentation:理解 BLAS/GEMM 在 NVIDIA GPU 上的库接口。
- NVIDIA CUTLASS GEMM API:看 GEMM 如何拆成 threadblock、warp、MMA instruction 和 epilogue。
- CUTLASS 3.x blog:理解可组合 GEMM kernel 和 epilogue fusion。
- Triton paper:理解 tiled neural network computation 和 roofline 视角。
- Megatron-LM:理解张量并行如何切 Linear/GEMM 并控制通信位置。
相关阅读与下一步
- 外部材料:The Illustrated Transformer。
- 外部材料:Dive into Deep Learning。
- 外部材料:Distill Circuits。
- 站内下一步:基础概念专题。
- 站内下一步:Transformer 输入与注意力。
- 站内下一步:数值、内存与运行时基础。
- Title: 基础知识:线性层、MLP 与 GEMM:模型里的矩阵乘为什么这么重要
- Author: Charles
- Created at : 2025-06-18 09:00:00
- Updated at : 2025-06-18 09:00:00
- Link: https://charles2530.github.io/2025/06/18/ai-files-foundations-linear-layers-mlp-and-gemm/
- License: This work is licensed under CC BY-NC-SA 4.0.