
基础知识:Mamba 与混合 SSM 架构
Mamba 是近几年最重要的 Transformer 替代/补充路线之一。它的目标不是把 token 之间两两做 attention,而是让序列沿时间方向维护一个紧凑状态,用线性复杂度处理长序列。混合 Mamba-Transformer 架构则更务实:保留一部分 attention 做精确检索和复杂 token 交互,把大量层换成 Mamba / SSM 来降低推理成本。
这页先回答“Mamba 与混合 SSM 架构”在「基础知识」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先看本页要补哪一个最小概念;公式或术语卡住时回到术语表,不需要一次吃完整个数学体系。 必要时先回 基础知识入口 或 术语表。
主线关系:把符号、张量、优化、评测和运行时这些前置打稳,后面的扩散、VLM/VLA、训练与系统页才不会断层。
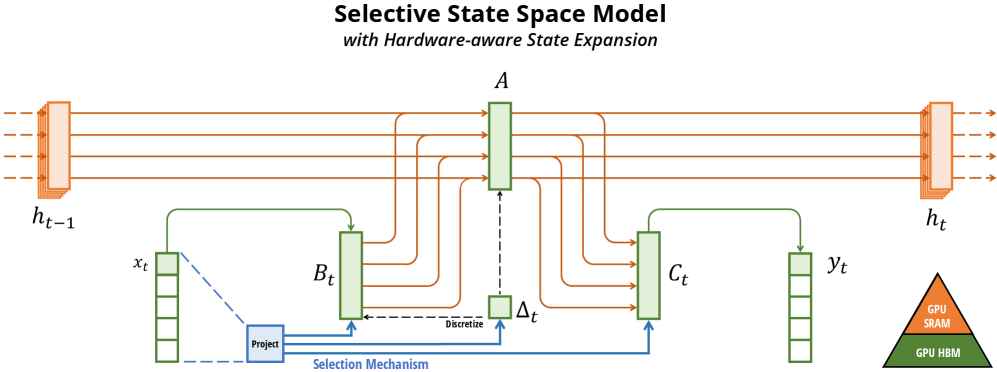
图源:Mamba: Linear-Time Sequence Modeling with Selective State Spaces,Figure 1。原论文图意:Structured SSM 会把输入通道映射到更高维 latent state;Mamba 的 selection mechanism 加入输入相关动态,并用 hardware-aware algorithm 避免把巨大 expanded state 直接物化到 GPU HBM。
先看哪里:先看左侧 Structured SSM,再看中间 selection mechanism,最后看右侧 hardware-aware scan。
图中模块:SSM 用内部状态承接历史;selection 让状态更新依赖当前输入;hardware-aware algorithm 让训练和推理不把巨大 expanded state 全部写回显存。
对应公式:先用 建直觉,再理解 Mamba 把它改成输入相关的 。
容易误读:Mamba 不是没有矩阵乘,也不是普通 RNN;它的重点是用内容选择和并行 scan 把 recurrent state 做到现代 GPU 友好。
Transformer 像“每次都翻完整上下文笔记”,Mamba 像“边读边更新一份工作记忆”。前者擅长精确内容寻址,后者擅长低成本长序列流式处理。现在流行的 Mamba-Transformer 不是二选一,而是让 attention 负责少量关键全局交互,让 Mamba 负责多数 token 的状态推进。
长上下文 KV cache 成本压不住、流式视频/机器人历史需要长期状态但不需要每个 token 精确互查,或者混合架构质量下降但延迟很好时,回看本页。本页能帮你判断该用 attention 做内容寻址、用 SSM 承接历史状态,还是调整 hybrid 中 attention 层的位置和比例。
为什么需要 Mamba
Transformer 的 self-attention 很强,因为它能让任意两个 token 直接交互。但代价也明显:
| 问题 | Transformer 的压力 | Mamba 想解决什么 |
|---|---|---|
| Prefill 复杂度 | attention score 近似随序列长度平方增长 | 用 recurrent / scan 形式线性处理序列 |
| Decode 显存 | KV cache 随上下文长度线性增长 | 每层只保留固定大小的状态 |
| 长上下文成本 | 上下文越长,注意力计算和缓存越重 | 用 compact state 承接历史 |
| 流式输入 | 每步要维护越来越长的 KV | 每步更新状态即可 |
这并不等于 Transformer “过时”。更准确地说:attention 是高质量内容寻址机制,Mamba 是高效状态更新机制。二者解决的是不同瓶颈。
从 SSM 到 Selective SSM
状态空间模型可以从一个很简单的递推式理解:
这里:
| 符号 | 含义 |
|---|---|
| 当前 token 的输入表示 | |
| 到当前位置为止的内部状态 | |
| 旧状态如何保留或衰减 | |
| 当前输入如何写入状态 | |
| 如何从状态读出输出 |
早期 SSM 的难点是参数通常不随输入内容变化,容易像固定滤波器:很会处理连续信号,但不够会“看内容决定记什么”。Mamba 的关键改造是 selective:让部分 SSM 参数由当前输入决定。直观地说,模型读到不同 token 时,可以选择保留、忘掉、写入或读出不同信息。
可以把 Mamba 的递推近似理解为:
其中 会受当前输入影响。这样它就不只是固定动态系统,而是“内容感知”的动态记忆。
Mamba block 里发生了什么
一个 Mamba block 通常可以拆成几步:
- 输入先经过 projection,扩展通道并产生门控分支;
- 用 depthwise convolution 补一点局部上下文;
- 通过 selective scan 沿序列更新状态;
- 用 gate 控制输出,再投影回 hidden size;
- 外层仍然配合 residual 和 normalization。
它和 Transformer block 的区别不是“有没有矩阵乘”。Mamba 仍然有大量 Linear / projection,也仍然需要高性能 kernel。真正的差别在序列混合方式:
| 结构 | 序列混合方式 | 推理时保存什么 | 强项 | 典型风险 |
|---|---|---|---|---|
| Transformer attention | 当前 token 读取历史 token 的 K/V | KV cache | 精确检索、复杂 token 交互、in-context learning | 长上下文显存和带宽成本高 |
| Mamba / selective SSM | 当前 token 更新 recurrent state | 固定大小状态 | 长序列、流式、低缓存、线性扩展 | 精确复制、稀疏检索、复杂状态追踪可能更难 |
| Hybrid Mamba-Transformer | 大多数层做状态推进,少数层做 attention | 状态 + 少量 KV cache | 在质量和推理成本之间折中 | 层比例、attention 位置、训练 recipe 很敏感 |
Mamba 推理时确实像 recurrent model 一步步更新状态,但训练时会用并行 scan 和硬件感知 kernel 提高吞吐。下面这组对照是理解 Mamba 的关键:它不是回到传统 RNN 的慢训练时代,而是把 recurrent state 重新做成适合现代长上下文和 GPU 的序列层。
Mamba 相比 RNN 改进在哪
最容易产生的误会是:既然 Mamba 也是
那它是不是“换皮 RNN”?答案是:推理形态像 RNN,但训练算法、状态参数化和硬件实现都更现代。
传统 RNN / LSTM / GRU 的基本思路也是维护一个 hidden state,把历史压进 。它们的问题不只是“会不会遗忘”,而是三件事叠在一起:训练强依赖时间步顺序,不容易吃满 GPU;隐藏状态是紧瓶颈,长历史和稀疏信息会互相挤压;门控虽然能选择忘/写,但整体计算没有围绕大模型长上下文推理做系统优化。
| 维度 | 传统 RNN / LSTM / GRU | Mamba 的改进 | 仍然要小心 |
|---|---|---|---|
| 状态更新 | 通常用固定权重和少量门控更新 ,输入会影响 gate,但转移结构比较固定 | Selective SSM 让 这类读写/衰减参数随输入变化,更像“内容感知的状态更新” | 输入相关不等于无限记忆,历史仍被压缩进状态 |
| 长程记忆 | LSTM/GRU 缓解梯度消失,但长序列信息仍容易被 hidden state bottleneck 挤掉 | SSM 参数化可以表示不同时间尺度的衰减与保留,expanded state 提供更大的线性动态容量 | 精确复制、needle retrieval、复杂变量绑定仍常需要 attention 帮忙 |
| 训练吞吐 | 时间步递推天然串行,长序列训练很难像 attention 那样并行展开 | Selective scan 把递推组织成可并行的 scan,在训练时能更好利用 GPU | causal decode 仍是一 token 一 token 往前推 |
| 推理缓存 | 只保留 hidden state,缓存低,但传统结构在大规模语言建模质量上不够稳 | 每层保留固定大小 state,避免 Transformer 那种随上下文增长的 KV cache | 仍有 state cache、projection、kernel 和 batch 调度成本 |
| 工程形态 | 经典 RNN block 相对简单,缺少现代大模型里的高吞吐组件组合 | Mamba block 结合 projection、depthwise conv、gate、residual/norm 和硬件感知 kernel | 不是公式线性就必然快,真实速度取决于 kernel 和 runtime |
所以更短的判断是:Mamba 不是把 RNN 重新包装,而是把 recurrent state 做成了“可并行训练、内容选择、GPU 友好”的状态空间层。它继承了 RNN 推理时固定状态的便宜,也努力补上了传统 RNN 在训练并行度、长程动态和现代硬件效率上的短板。
Selective scan 为什么重要
如果只看数学,Mamba 像一个输入相关的递推模型;如果落到 GPU,难点是如何把这个递推跑快。
原始 Mamba 论文强调两点:
- SSM 参数输入相关后,不能直接沿用传统卷积式 SSM 的高效计算;
- 因此需要 hardware-aware parallel algorithm,在训练时用 scan 并行化,在推理时用 recurrent state 低成本解码。
这也是 Mamba 比很多“线性 attention”路线更受关注的原因:它不只提出了一个低复杂度公式,还给出了能在现代 GPU 上实际跑起来的层实现。
Mamba-2:为什么说 Transformers are SSMs
Mamba-2 的论文标题很有意思:Transformers are SSMs。它不是说 Transformer 和 Mamba 完全一样,而是指出 attention、SSM 和一类 structured semiseparable matrix 之间有统一视角。
这带来两个重要启发:
| 启发 | 怎么理解 |
|---|---|
| attention 和 SSM 不是完全割裂 | 它们都可以看成某种序列混合矩阵,只是矩阵结构和计算方式不同 |
| Mamba-2 更像工程化 refinement | 通过 SSD framework 重新组织 selective SSM,核心层比 Mamba 更快,同时保持语言建模竞争力 |
从学习路线看,Mamba-2 的价值不是多背一个名字,而是帮你理解:现代长序列模型正在从“attention vs RNN”走向“不同结构矩阵的高效实现”。
Mamba-3:新的推理优先视角
截至 2026 年,Mamba-3 继续沿着“推理效率和模型质量同时优化”的方向推进。论文强调当前 Transformer 强在质量,但 quadratic compute 和线性 KV memory 让推理昂贵;很多线性模型虽然理论上高效,却会牺牲状态追踪等能力。
Mamba-3 的几个关键词是:
| 关键词 | 含义 |
|---|---|
| SSM discretization | 从状态空间离散化角度设计更强递推 |
| complex-valued state update | 用复数状态更新增强状态表达 |
| MIMO formulation | 多输入多输出形式,在不增加 decode latency 的前提下改善性能 |
| state tracking | 更重视模型是否真的记住和更新状态,而不只看困惑度 |
这说明 Mamba 路线还在快速演化:早期重点是“能不能替代 attention 的长序列成本”,后续重点会变成“能不能在真实推理任务里保持状态、检索和推理质量”。
什么是 Mamba-Transformer 混合架构
Mamba-Transformer 通常不是一个固定模型名,而是一类混合架构:
1 | token embedding |
它流行的原因很直接:纯 Mamba 在某些能力上可能不如 attention 稳,纯 Transformer 又有 KV cache 和长上下文成本。混合架构试图吃到两边好处。
| 组件 | 在混合架构里的角色 |
|---|---|
| Mamba layer | 替代大量 self-attention,降低每 token decode 成本和 cache 压力 |
| Attention layer | 周期性提供精确 token-to-token 路由,帮助检索和复杂上下文绑定 |
| MLP / MoE | 提供逐 token 非线性容量,MoE 可扩大总参数但控制 active 参数 |
| GQA / sliding / local attention | 降低剩余 attention 层的 KV 和计算压力 |
| Norm / residual | 保证深层混合训练稳定 |
代表工作:Jamba、Jamba-1.5、Nemotron-H
| 工作 | 核心设计 | 为什么值得看 |
|---|---|---|
| Jamba | hybrid Transformer-Mamba-MoE,交错 Transformer 和 Mamba layer | 证明混合架构可以在大模型、长上下文和单卡部署约束下工作 |
| Jamba-1.5 | instruction-tuned Jamba 系列,Mini/Large 两个规模,有效上下文 256K | 把混合架构从 base model 推到 instruction/chat 场景,并配套 ExpertsInt8 |
| Nemotron-H | NVIDIA 的 hybrid Mamba-Transformer family,用 Mamba 替换大多数 self-attention layer | 更像工业推理成本导向:目标是在同等精度下减少推理成本,报告最高约 3x 推理加速 |
Jamba 的重点是“怎么组合”:attention 和 Mamba 的比例、层排列、MoE 放在哪里都会影响大规模训练。Nemotron-H 的重点是“为什么组合”:当 inference-time scaling 变重要时,模型越会推理,越需要把每个生成 token 的成本降下来。
设计混合架构时看哪些旋钮
读任何 Mamba-Transformer 技术报告时,可以按下面清单拆:
| 旋钮 | 要问的问题 |
|---|---|
| Attention ratio | 每多少层放一次 attention?attention 是全局、局部还是 GQA? |
| Mamba state size | 每层状态多大?状态越大是否真的提升任务能力? |
| Layer layout | attention 是均匀插入,还是靠前/靠后集中? |
| MoE placement | 哪些层用 dense MLP,哪些层用 MoE?路由和通信成本如何处理? |
| Positional handling | attention 层是否还需要 RoPE 或其他位置机制?Mamba 层如何感知顺序? |
| Training recipe | 是否需要更小学习率、更强 norm、FP8/BF16 recipe 或蒸馏? |
| Serving path | 状态 cache、KV cache、batching、paged memory 和 kernel 是否都支持? |
混合架构不是把两种 block 随便拼起来。它更像系统设计:质量、吞吐、显存、上下文长度、训练稳定性和服务 runtime 需要一起调。
常见误解
| 误解 | 更准确的说法 |
|---|---|
| Mamba 一定比 Transformer 好 | Mamba 更省长序列状态成本,但 quality / retrieval / reasoning 要看任务和规模 |
| Mamba 没有 KV cache,所以推理免费 | 它减少 KV cache 压力,但仍有状态、projection、kernel 和 batch 调度成本 |
| 混合架构就是 50% attention + 50% Mamba | 实际常是少量 attention + 大量 Mamba,比例需要消融 |
| Mamba 不需要位置编码 | 递推本身有顺序,但混合架构里的 attention 层仍可能需要位置机制 |
| 线性复杂度一定带来真实速度提升 | 只有 kernel、内存布局、batching 和 runtime 配合好,理论复杂度才会变成 wall-clock 收益 |
和现有基础知识怎么接
| 如果你想理解 | 回看 |
|---|---|
| Mamba 里的 projection 和 gate 为什么仍然耗算力 | 线性层、MLP 与 GEMM |
| attention 为什么质量强但 KV cache 贵 | Transformer 输入与注意力 |
| RoPE、mask、上下文窗口和 KV cache | 位置编码与上下文 Mask |
| hidden state、latent state 和状态递推 | 概率与潜变量模型 |
| kernel、显存带宽和推理 runtime | 数值、显存与运行时 |
参考资料
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces:selective SSM、hardware-aware scan 和 Mamba block 的起点。
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality:Mamba-2 和 SSD 统一视角。
- Jamba: A Hybrid Transformer-Mamba Language Model:Transformer-Mamba-MoE 混合架构代表。
- Jamba-1.5: Hybrid Transformer-Mamba Models at Scale:instruction-tuned hybrid model 与 256K 上下文。
- Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models:推理成本导向的混合 Mamba-Transformer family。
- Mamba-3: Improved Sequence Modeling using State Space Principles:2026 年的新一代 SSM 改进,关注 state tracking 与推理效率。
- state-spaces/mamba:Mamba 官方实现入口。
本页结论
Mamba 的价值不是简单替代 Transformer,而是把“长序列记忆”从巨大 KV cache 转成紧凑状态更新;Mamba-Transformer 的价值也不是堆新名词,而是在注意力质量和状态空间效率之间找工程折中。以后读大模型架构报告时,看到 Mamba-heavy、hybrid、SSM、linear recurrent,先问:哪些层负责精确检索,哪些层负责状态推进,推理时到底缓存了什么。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:概率与潜变量模型。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:Mamba 与混合 SSM 架构
- Author: Charles
- Created at : 2025-06-23 09:00:00
- Updated at : 2025-06-23 09:00:00
- Link: https://charles2530.github.io/2025/06/23/ai-files-foundations-mamba-and-hybrid-ssm-transformers/
- License: This work is licensed under CC BY-NC-SA 4.0.