
基础知识:数值、显存与运行时:模型为什么数学可行但系统跑不动
这篇文章只回答一个问题:一个模型从“公式上能算”到“线上能跑快、跑稳、跑得起”,中间到底会被哪些系统成本卡住。
很多模型报告会同时出现 BF16、FP8、INT4、KV cache、FLOPs、bandwidth、kernel、runtime、TTFT、TPOT。它们不是一堆独立术语,而是同一条执行链上的不同账本:数值格式决定每个值怎么表示,显存决定哪些张量能常驻,带宽决定数据搬得多快,kernel 决定硬件是否吃到高效路径,runtime 决定请求、batch、cache 和 shape 能否被组织起来。
第一张账:一个数占多少 bytes
先从最小账开始。一个张量的粗略显存是:
这行式子在说:shape 先决定元素个数,dtype 再决定每个元素多少字节。它还不是完整显存,但能把“一个张量大不大”先落到数量级。
常见格式可以先按这张表读:
| 格式 | bytes/value | 常见用途 | 主要风险 |
|---|---|---|---|
| FP32 | 4 | 参考路径、部分 optimizer state | 贵,带宽压力大 |
| FP16 | 2 | 混合精度训练/推理 | 动态范围窄,训练常要 loss scaling |
| BF16 | 2 | 大模型训练常用 | 范围宽但尾数少,精度仍低于 FP32 |
| FP8 / INT8 | 1 | 新硬件训练/推理、量化路径 | scale、outlier、kernel 支持决定成败 |
| INT4 / FP4 | 0.5 | 权重量化、极低比特实验 | 解包、scale、质量回归和 kernel 更敏感 |
低精度的收益不是“格式名字更先进”,而是减少存储和搬运,最好还能命中更快的硬件指令。但每少一位,误差、动态范围、scale 和 fallback 风险都会变得更重要。
FP8 不是一个 dtype 开关
FP8 常见 E4M3 和 E5M2。E4M3 给 mantissa 更多位,精度更细;E5M2 给 exponent 更多位,范围更宽。训练和推理系统通常不会把全模型硬改成 FP8,而是配合 scale、amax history、累加精度和敏感算子保护。
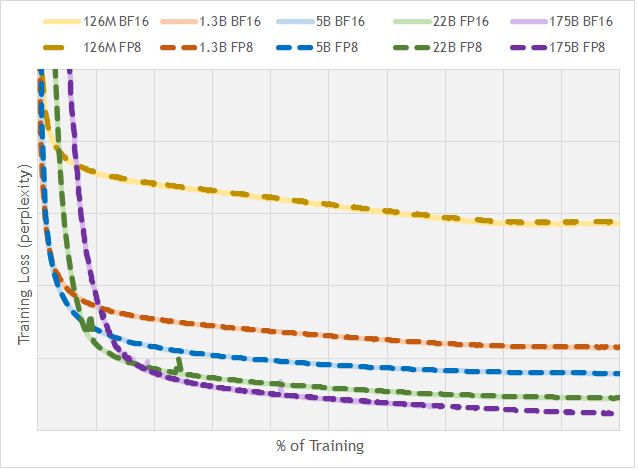
图源:FP8 Formats for Deep Learning,Figure 1。原图对比 BF16 与 FP8 训练曲线。本站用这张图说明:低精度是否可用,要看训练曲线、scale 策略和质量回归,而不是只看每个值从 2 bytes 降到 1 byte。
FP8 路径通常有一个缩放步骤:
这里 是 scale。公式读法是:先把原张量缩放到 FP8 能表示得比较舒服的范围,再 cast。scale 太小会 overflow;scale 太大,主体值会挤在粗糙格点里。NVIDIA Transformer Engine 的 delayed scaling 就是用历史 amax 统计来更新 scale,而不是把“转 FP8”当成孤立操作。
实际混合精度常按路径拆:
| 路径 | 常见精度选择 | 原因 |
|---|---|---|
| 大块 GEMM / Linear / MLP | FP8、BF16、FP16 | 计算和带宽收益最大 |
| LayerNorm / RMSNorm | BF16/FP16 或更高保护 | 统计和缩放对误差敏感 |
| Softmax / logits | BF16/FP16 或更高保护 | 指数、归一化和排序会放大误差 |
| residual add | BF16/FP16 常见 | 跨层累积,误差会传播 |
| optimizer state | FP32、BF16、低精分片 | 更新精度和恢复语义都重要 |
所以 FP8 的工程问题是:哪些张量低精,scale 怎么管,哪些 kernel 真命中,哪些路径保高精,质量回归有没有覆盖关键桶。
第二张账:哪些张量常驻显存
同一个模型,训练和推理的常驻状态不同。
| 阶段 | 主要显存账 | 备注 |
|---|---|---|
| 训练 | parameters、gradients、optimizer state、activations、workspace | optimizer state 和 activation 常常比权重更麻烦 |
| 推理 prefill | weights、prompt activations、KV 写入、workspace | 长 prompt 计算重,attention 和 GEMM 都忙 |
| 推理 decode | weights、KV cache、采样状态、workspace | 每步生成少量 token,但反复读权重和历史 KV |
| 多模态 | vision/video activations、connector、LLM states | 图像/视频 token 会推高激活和 prefill |
这解释了为什么“模型能推理”不代表“模型能训练”,也不代表“能高并发长上下文服务”。训练时 AdamW 可能要为每个参数保存 momentum、variance 和 master weights;推理时 optimizer 没了,但 KV cache 会随 batch 和上下文长度线性增长。
一个 7B BF16 权重的最小常驻显存约为:
这行式子只算权重。若训练,还要加梯度、optimizer state、activation;若长上下文推理,还要算 KV cache。
KV cache:长上下文服务里的主角
自回归 decode 每生成一个 token,都要读取历史 token 的 Key/Value。KV cache 的数量级可以写成:
这里前面的 2 表示 K 和 V, 是层数, 是活跃序列数, 是上下文长度, 是 KV head 数, 是每个 head 的维度。读这行公式时抓住线性关系:batch 翻倍、上下文翻倍、KV heads 翻倍,KV 显存都会相应翻倍。
举个常见量级:32 层、batch 8、上下文 16k、8 个 KV heads、head dim 128、BF16:
如果是普通 MHA 而不是 GQA,KV heads 可能接近 query heads,KV cache 会更大。若使用 MQA/GQA/MLA,KV 宽度下降,decode 的显存和读带宽压力也会下降。判断长上下文是否跑得动,不能只看参数量,要看 layers、active batch、context、KV heads、head dim、dtype、paged cache 和 prefix reuse。
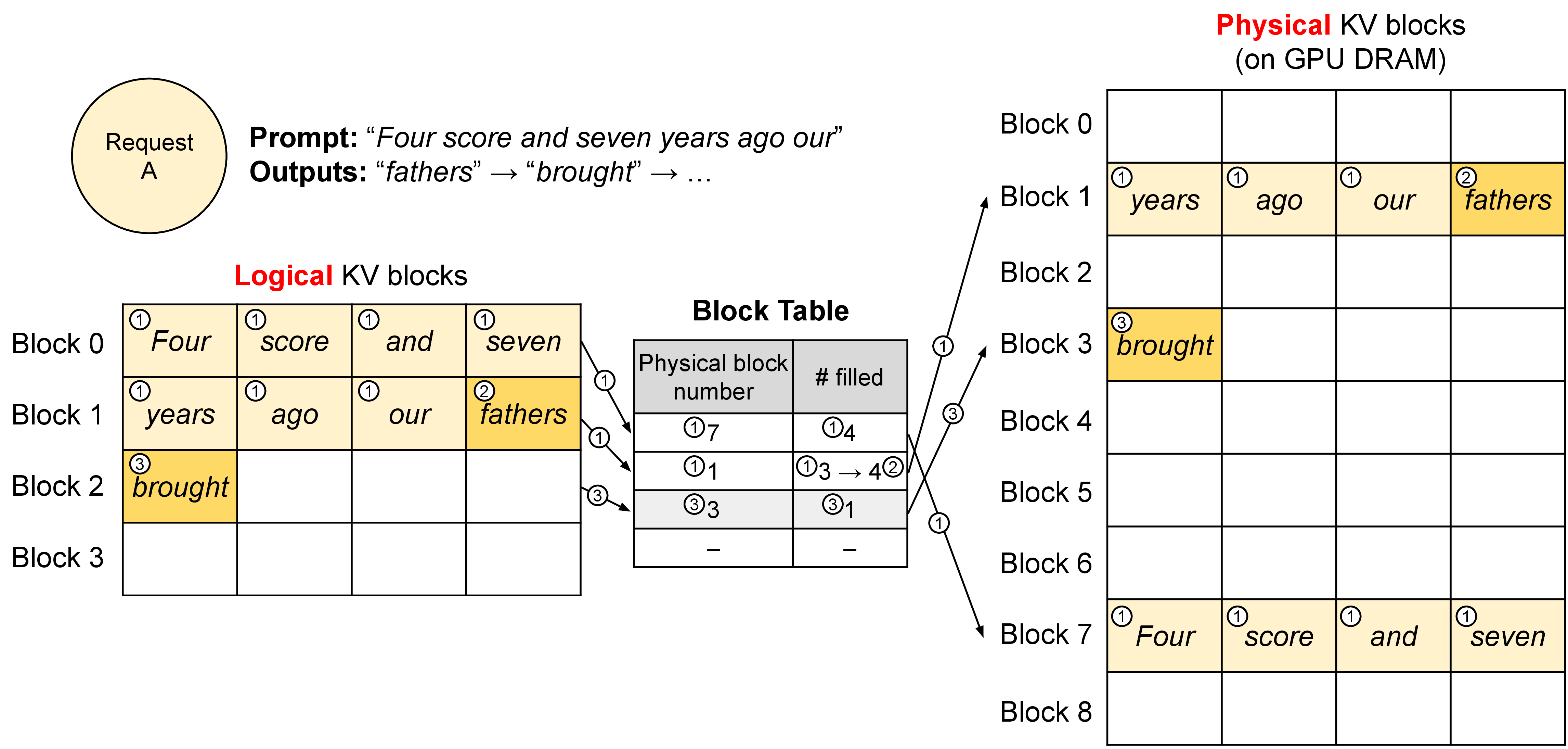
图源:vLLM PagedAttention blog。原图表达:sequence 的逻辑 KV block 可以映射到不连续的物理 block。本站用这张图说明:serving runtime 的关键工作之一,是管理 KV cache 生命周期和碎片,而不是只调用一次模型 forward。
PagedAttention、TensorRT-LLM KV cache reuse、KV offload、prefix cache 和 KV 量化,本质上都是围绕同一件事:有限 GPU 显存应该如何服务更多活跃请求,同时不伤质量和 P99。
第三张账:FLOPs 不等于速度
一个 Linear 层 ,权重 。不含 bias 时:
这两行式子在说:单个 token 通过这层时,每个权重大致贡献一次乘加,所以参数量和单 token MACs 主项看起来相同。但它们不是同一件事。Params 是静态存储;MACs 是在某个输入 shape、某个阶段实际执行的乘加。batch、prefill、decode、MoE routing、attention 长度都会让二者分开。
速度还取决于算术强度:
如果一个算子每搬很多 bytes 只做一点计算,它通常被 memory bandwidth 限制;如果每搬少量 bytes 做很多矩阵乘,它更可能 compute-bound。Roofline 图就是把“算力上限”和“带宽上限”放到同一张图里看。Nsight Compute 的 roofline 能帮助判断一个 kernel 是计算没吃满,还是数据搬运拖住。
这就是为什么 FlashAttention 影响很大:它不是改变 attention 的数学结果,而是用 tiling 减少 HBM 和 SRAM 之间的读写,把原本 IO-heavy 的路径组织得更接近硬件友好。
第四张账:kernel 命中和 runtime 调度
低精度模型文件变小,不等于端到端变快。一个 INT4 权重模型若没有高效 INT4 kernel,可能先解包/反量化成 FP16,再走普通 GEMM;文件省了,TPOT 未必省,甚至可能更慢。
上线前要把“格式支持”拆成四层:
| 层 | 要确认什么 |
|---|---|
| 硬件 | 是否有对应 Tensor Core / MMA / 指令路径 |
| kernel | 热点 shape 是否命中 FP8/INT8/INT4 GEMM、attention 或 fused kernel |
| graph/runtime | cast、dequant、transpose、layout transform 是否被融合或隐藏 |
| serving | batching、shape bucket、KV cache、prefix reuse、fallback 是否影响 P95/P99 |
Runtime 负责把请求组织成硬件能吃的形状。prefill 通常 batch 大、矩阵乘更饱;decode 每步 token 少、请求进出频繁、KV 读写重,更容易被调度、内存和小 kernel 开销限制。一个方案在 microbenchmark 上快,不代表在真实请求分布上快。
一个可复算例子:为什么权重量化不一定解决长上下文
假设 70B 模型用 BF16 权重,权重约:
如果权重量化到 4-bit,权重存储可以粗略降到约 35 GB。听起来已经解决问题,但长上下文服务可能仍被 KV cache 卡住。
还是用 KV 公式。若模型 80 层,batch 8,上下文 32k,8 个 KV heads,head dim 128,BF16:
这行计算表示:即使权重已经被压到 4-bit,KV cache 仍可能占掉几十 GB。若线上还要保留 page metadata、workspace、并发请求和碎片,显存压力不会因为权重变小就自动消失。此时更相关的手段可能是 GQA/MQA/MLA、KV 量化、paged cache、prefix cache、context trimming 或请求路由。
| 优化动作 | 主要省什么 | 不一定省什么 |
|---|---|---|
| 权重量化 | 权重显存、部分权重带宽 | KV cache、activation、decode 调度 |
| KV 量化 | 长上下文并发显存、decode 读带宽 | prefill 计算、scale/dequant 开销 |
| FlashAttention | attention 中间读写 | KV 生命周期和请求调度 |
| CUDA Graph / compile | launch overhead、图执行开销 | 形状过散时命中率可能低 |
| shape bucketing | padding 浪费、kernel 命中率 | 长尾请求和质量差异 |
这个例子说明:系统优化要先找主瓶颈。权重、KV、activation、workspace、kernel、runtime 各自有不同解法。
怎么验证系统改动真的有效
一个低精度、KV cache 或 kernel 改动,至少要同时看:
| 指标 | 说明什么 |
|---|---|
| peak memory / KV GiB | 是否真的降低常驻和峰值显存 |
| TTFT | prefill、排队和 cache hit 是否改善 |
| TPOT | decode 每步是否更快 |
| P95/P99 | fallback、编译、cache miss、长尾请求是否拖慢 |
| kernel trace | 是否真命中目标 dtype/kernel,而不是回退 |
| quality buckets | 数学、代码、长上下文、OCR、工具调用是否退化 |
| cost per successful request | 质量和系统成本是否一起改善 |
不要只报平均吞吐。真实服务里,长 prompt、长输出、多轮工具调用、低 cache hit、低投机接受率、动态 batch、视觉输入和不规则 shape 都会制造尾延迟。系统报告如果只展示一个漂亮的 tokens/s,很难证明线上会更好。
读完以后怎么判断
数值格式决定每个值怎样表示,显存决定哪些状态能常驻,带宽决定数据搬运是否成瓶颈,kernel 决定低精度和融合能否兑现,runtime 决定请求、batch、KV cache 和 shape 是否被组织好。读 FP8、量化、FlashAttention、vLLM、TensorRT-LLM 或 DeepSeek-V3 这类材料时,不要先背技术名词,先问:它省的是哪张账,代价转移到哪里,质量和 P99 是否一起验证。
外部精读
- NVIDIA Mixed Precision Training Guide:理解 loss scaling、Tensor Core 和混合精度训练的基本路径。
- NVIDIA Transformer Engine FP8 Delayed Scaling:理解 FP8 scale 和 amax history。
- FP8 Formats for Deep Learning:理解 E4M3/E5M2、scale 和训练曲线证据。
- Nsight Compute Roofline:理解 compute-bound 与 memory-bound 的判断方式。
- FlashAttention:理解 IO-aware attention 如何减少 HBM 读写。
- vLLM PagedAttention blog:理解 KV cache block 管理、continuous batching 和 serving 内存浪费。
- TensorRT-LLM KV Cache System:理解 KV reuse、offload、eviction 和生产 runtime。
- General Compute: Quantization for Inference:用工程视角区分 GPTQ、AWQ、SmoothQuant 和 FP8 的适用瓶颈。
相关阅读与下一步
- 外部材料:The Illustrated Transformer。
- 外部材料:Dive into Deep Learning。
- 外部材料:Distill Circuits。
- 站内下一步:基础概念专题。
- 站内下一步:Transformer 输入与注意力。
- 站内下一步:数值、内存与运行时基础。
- Title: 基础知识:数值、显存与运行时:模型为什么数学可行但系统跑不动
- Author: Charles
- Created at : 2025-06-26 09:00:00
- Updated at : 2025-06-26 09:00:00
- Link: https://charles2530.github.io/2025/06/26/ai-files-foundations-numerics-memory-and-runtime-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.