
基础知识:概率与潜变量模型
生成模型的目标不是记住训练样本,而是学习数据背后的分布,并从这个分布中采样出新样本。
这页先回答“概率与潜变量模型”在「基础知识」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先看本页要补哪一个最小概念;公式或术语卡住时回到术语表,不需要一次吃完整个数学体系。 必要时先回 基础知识入口 或 术语表。
主线关系:把符号、张量、优化、评测和运行时这些前置打稳,后面的扩散、VLM/VLA、训练与系统页才不会断层。

图源:Denoising Diffusion Probabilistic Models,Figure 2。原论文图意:前向过程 逐步加噪,反向生成过程 逐步去噪,从噪声链条恢复数据样本。
这张图可以先看成一个带很多中间变量的生成模型。前向链 把真实数据 变成一串越来越 noisy 的潜状态,反向链 则学习每一步的条件分布,最后从噪声恢复到样本。扩散、VAE、世界模型都可以先放进“分布、潜变量、目标函数、采样”这套框架里理解;区别在于潜变量怎么定义、目标函数怎么写、采样过程要走多少步。
生成模型不是背训练集,而是学习“什么样的样本更像真实数据”。潜变量可以理解成模型内部的草稿:先组织姿态、风格、结构或状态,再生成可见结果。读扩散、VAE、世界模型或生成式模拟时,重点分清数据分布、条件分布、潜变量、likelihood、ELBO 和采样分别在什么位置。
世界模型 rollout 越滚越漂、同一历史下多种未来被平均成一个模糊未来、risk head 很自信却漏报 near-miss,或者 latent 看起来压得很省但 planner 用不了时,先回到分布、条件分布、潜变量和不确定性。本页能帮你判断模型是在学 ,还是只学了一个漂亮但不可控的平均视频分布。
概率与潜变量不是抽象基础课,而是在世界模型里决定“模型知道自己不知道什么”。好的 latent 能降低 token 成本和训练成本;好的不确定性建模能降低 rollout 误判成本。反过来,若分布假设错了,模型会把多种未来平均掉,让 planner 在低成本想象里做高风险决策。
符号卡:概率页先认这些
| 符号 | 读法 | 含义 |
|---|---|---|
| data distribution | 真实数据背后的分布 | |
| model distribution | 参数为 的模型分布 | |
| conditional distribution | 给定条件 时生成 | |
| latent variable | 模型内部看不见但要推断的隐藏因素 | |
| inference distribution | 看到 后推断 的近似分布 | |
| KL divergence | 两个分布之间的差异 | |
| ELBO | evidence lower bound | 带潜变量模型里常用的可优化目标 |
看到 和 时先不要慌。一个很常见的约定是: 负责“生成或预测”, 负责“看到真实数据后反推 latent”。不同论文会有差异,但先按这个方向读通常不容易迷路。
分布是什么
可以把数据看成来自某个未知分布:
生成模型希望学一个模型分布 ,让它接近真实数据分布。
如果是条件生成,例如文生图,则写成:
其中 可以是文本、类别、图像、动作或其他条件。
潜变量为什么有用
很多数据背后有隐藏因素。例如一张人脸图片背后可能有姿态、光照、表情、身份、背景等因素。潜变量 用来表示这些隐藏结构:
直觉上,潜变量像草稿或内部状态。模型先在潜空间里组织结构,再把它解码成可见样本。
2.1 潜变量不是一个东西,而是一类“内部草稿”
读后面的论文专题时,最容易卡住的一点是:大家都在说 latent,但含义并不完全一样。可以把 latent 想成厨师做菜前的“备菜台”:有的 latent 是一张图片的压缩草图,有的是一段视频的时空压缩,有的是智能体脑中的当前局势,有的是扩散模型从噪声走向样本的中间状态。
| 场景 | latent 在表示什么 | 它服务谁 |
|---|---|---|
| VAE / 视频 VAE | 把像素压成更短、更容易建模的连续表示 | 让 DiT / U-Net 不必直接处理高分辨率像素 |
| 扩散模型 | 是从干净样本到噪声之间的中间状态 | 让模型学会一步步把噪声推回数据分布 |
| RSSM / Dreamer | belief state 同时记住历史和当前不确定性 | 让 agent 在脑内 rollout,训练 actor / critic |
| JEPA / V-JEPA | 被预测的不是像素,而是抽象表示 | 让模型学“世界结构”,不被纹理细节拖住 |
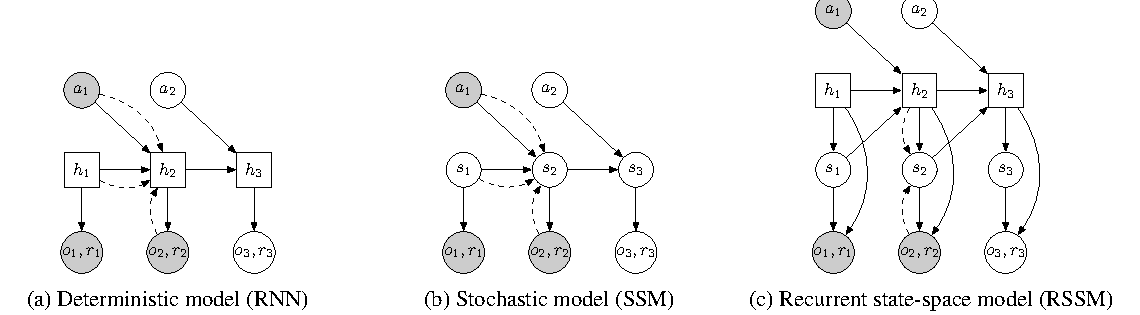
图源:Learning Latent Dynamics for Planning from Pixels,Figure 2。原论文图意:比较 RNN、SSM 和 RSSM 三种 latent dynamics 设计;RSSM 同时保留 deterministic hidden state 和 stochastic state,用于从像素学习可规划的潜空间动力学。
这张图可以把 latent 的作用讲得很直观:模型并不想在像素上直接规划,而是先把过去看到的画面和动作压进内部状态。RNN 路线像一本连续日记,擅长记历史;SSM 路线像每一步都抽一次签,擅长表达不确定性;RSSM 把二者合起来,既有长期记忆,也有随机潜状态。Dreamer 系列后来能在 latent space 里“想象未来”,靠的就是这种内部草稿足够稳定。
所以,看到论文里写 latent,不要马上把它翻译成“隐藏向量”就结束。更应该追问三件事:这个 latent 保留了哪些信息,丢掉了哪些细节;它能不能被稳定 rollout;它最后是服务生成画面、压缩计算,还是服务决策。
2.2 算一遍:小概率漏报会怎样放大
世界模型常见失败不是每一步都错,而是每一步都有一点点没校准的风险。假设 risk head 对“接触即将失败”的漏报率是 5%。单步看似不大,但 20 步 rollout 中至少漏一次的概率是:
这就是为什么世界模型不能只报一个最可能未来。若未来分布是多峰的,均值预测可能看起来 loss 低,却会把“会滑落”和“能抓稳”平均成一个模糊中间态。对 planner 来说,中间态不是保守,而是危险:它既不对应真实可执行动作,也低估了长尾风险。
一个更可用的判断链是:
1 | 症状:open-loop 画面平均还行,长 horizon 决策越来越漂 |
Likelihood、KL 和 ELBO
很多生成模型想最大化 likelihood:
但带潜变量时,真实 likelihood 往往难算,所以会用 ELBO 这类可优化下界。
ELBO 常见形式可以粗略理解为:
这解释了为什么 VAE 既要重建样本,又要约束 latent 不要乱跑。
初学者先把 ELBO 读成两股力:一股力让模型从 latent 还原出像真实数据的样本,另一股力让 latent 分布别跑得太散、太怪。前者保证有用,后者保证可采样、可泛化。扩散、VAE、RSSM 和世界模型虽然公式不同,但常常都在平衡“解释观测”和“约束内部状态”。
Score 和扩散模型
Score 指的是:
它表示在当前位置,往哪个方向走会更接近高概率数据区域。扩散模型可以理解为学习一个随噪声时间变化的 score field 或等价的噪声预测器。
这也是为什么扩散采样可以被看成“从噪声往数据分布走回去”。
采样:从分布到具体样本
训练得到分布还不够,最终要采样出具体样本:
1 | z = sample_prior() |
不同生成模型的差异,很多时候就体现在 denoise_or_update 怎么定义。
和后续专题的关系
- 扩散模型路线图:理解加噪、去噪和 score。
- Score Matching 到 SDE:理解连续时间生成轨迹。
- 世界模型路线图:理解潜状态、未来预测和动作条件分布。
- 量化:低精度误差最终也会改变模型分布。
本页结论
生成模型的核心问题是:如何表示分布、如何训练分布、如何从分布采样。只要这三件事清楚,扩散、VAE、世界模型和视频生成之间的关系会更容易理解。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:优化与训练入门。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:概率与潜变量模型
- Author: Charles
- Created at : 2025-07-08 09:00:00
- Updated at : 2025-07-08 09:00:00
- Link: https://charles2530.github.io/2025/07/08/ai-files-foundations-probability-latent-variables-and-generative-models/
- License: This work is licensed under CC BY-NC-SA 4.0.