
基础知识:Transformer 输入与注意力
Transformer 是现代 LLM、VLM、DiT、世界模型和很多推理系统的核心结构。它的关键思想是:把输入变成 token,再用 attention 让 token 之间按相关性互相读取信息。
这页先回答“Transformer 输入与注意力”在「基础知识」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先看本页要补哪一个最小概念;公式或术语卡住时回到术语表,不需要一次吃完整个数学体系。 必要时先回 基础知识入口 或 术语表。
主线关系:把符号、张量、优化、评测和运行时这些前置打稳,后面的扩散、VLM/VLA、训练与系统页才不会断层。
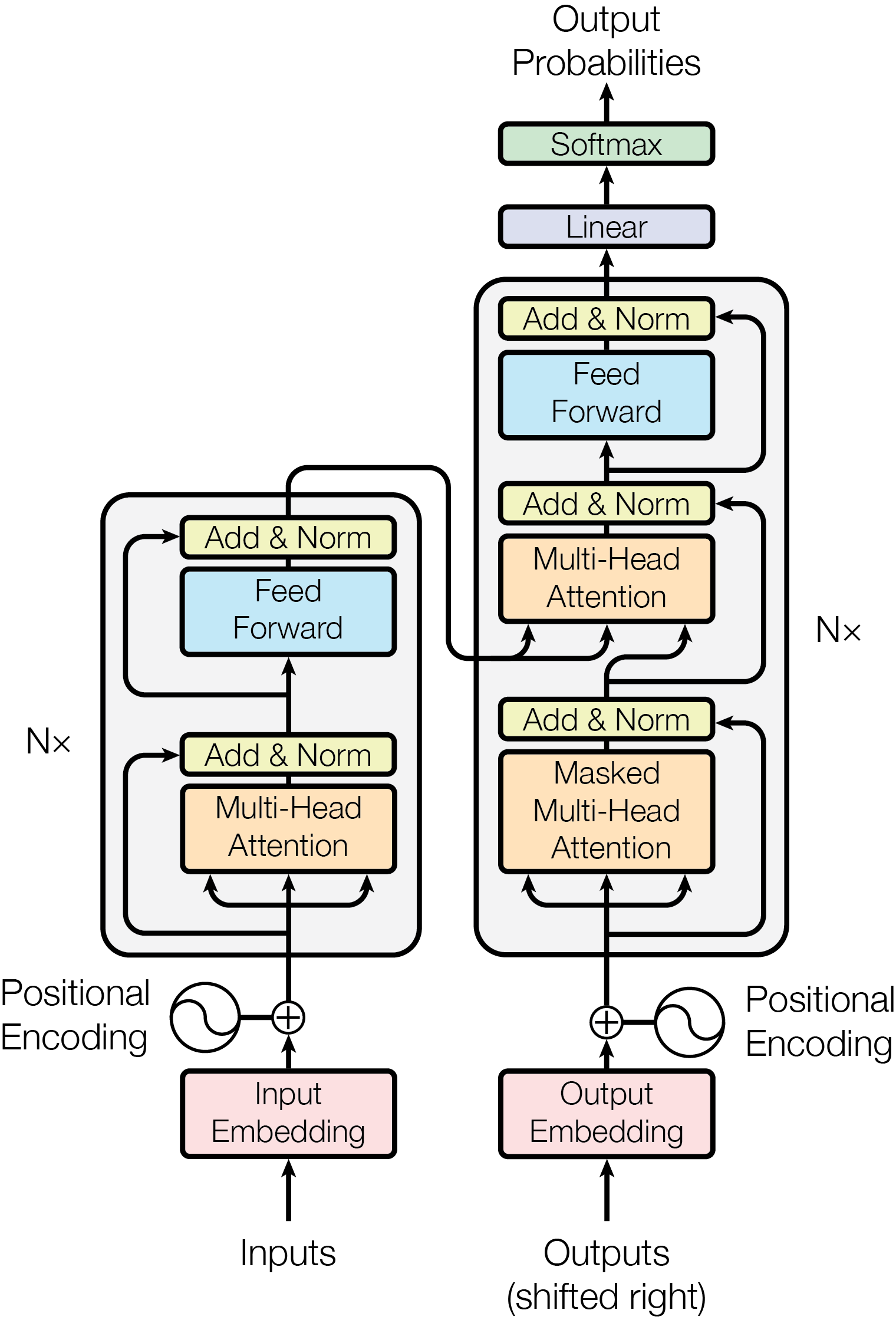 { width=“500” .atlas-figure-tall }
{ width=“500” .atlas-figure-tall }
图源:Attention Is All You Need,Figure 1。原论文图意:Transformer 由 encoder 和 decoder 组成,核心模块包括 multi-head attention、feed-forward、residual connection、normalization、positional encoding 与输出 softmax。
第一次看这张图不要急着背每个框。第一条线是输入 token 先变成 embedding,并叠加 positional encoding,让模型知道顺序。第二条线是每层都交替做 attention 和 feed-forward:attention 负责跨 token 读信息,feed-forward 负责逐 token 变换表示。第三条线是 decoder 比 encoder 多了 masked self-attention 和 encoder-decoder attention,所以它既能按因果顺序生成下一个 token,也能读取 encoder 提供的源序列信息。
Attention 的核心不是“模型很聪明”,而是每个 token 都能按相关性读取其他 token。Q/K/V 可以先理解成:我想找什么、别人暴露什么、真正读走什么。看到 LLM、VLM、DiT 或 agent 模型时,先分清 tokenization、embedding、self-attention、cross-attention 和输出 head 分别在哪一层。
世界模型不是只读一句文本,而是同时读多相机图像、视频历史、机器人状态、动作、语言指令和可能的未来 rollout。Attention 决定这些 token 如何互相读取,KV cache 决定长历史在推理时占多少显存,mask 决定哪些过去和未来能被看见。比如 4 路相机、16 帧、224x224、14x14 patch 就已经有 16,384 个视觉 token;如果分辨率提高到 448x448,视觉 token 会到 65,536,直接超过 32k context。学 attention 不是为了背公式,而是为了能判断 token、context、KV、mask 和吞吐之间的取舍。
视觉 token 一多吞吐就断崖下降、长上下文 decode 被 KV cache 卡住、动作 token 加进去后模型不再关注关键帧、或者不同动作的未来几乎一样时,先回到 tokenization、Q/K/V、self-attention 和 cross-attention 的分工。本页能帮你判断该压视觉 token、改连接器、换 GQA/MLA/KV 量化,还是检查 action token 是否真的进入了可被 attention 读取的位置。
Tokenization:模型如何“切开”输入
Token 是模型处理信息的基本单位。不同模态有不同 token:
| 模态 | token 例子 |
|---|---|
| 文本 | subword token |
| 图像 | patch token |
| 视频 | tubelet token 或 frame token |
| 机器人 | action token、state token |
| 世界模型 | latent token、未来状态 token |
Tokenization 的作用是把复杂输入变成一个序列:
然后每个 token 被映射成 embedding:
| 符号 | 含义 |
|---|---|
| 第 个 token,可以是文本 token、图像 patch 或动作 token | |
| 第 个 token 的向量表示 | |
| 序列长度,token 总数 | |
| hidden dimension,每个 token 向量的长度 |
Attention 的 Q/K/V 直觉
Attention 可以用“提问、匹配、读取”理解:
Q:Query,当前位置想问什么。K:Key,每个位置暴露什么可匹配信息。V:Value,真正被读取的内容。
公式是:
这表示每个 token 会根据相似度,从其他 token 里加权读取信息。
是“每个 query 和每个 key 的匹配分数”,shape 大致是 [L, L]; 用来缩放分数,避免维度大时点积过大;softmax 把分数变成权重;最后乘 ,表示按权重把 value 读回来。最简读法是:先匹配,再归一化,再读取。
| 符号 | 读法 | 含义 |
|---|---|---|
| query | 当前位置想找什么信息 | |
| key | 每个位置提供什么可匹配线索 | |
| value | 真正被读走的内容 | |
| head dimension | 单个 attention head 的维度 |
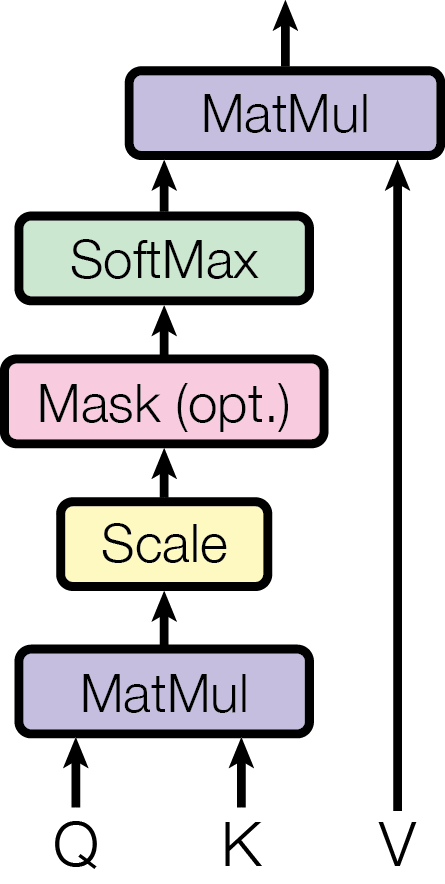
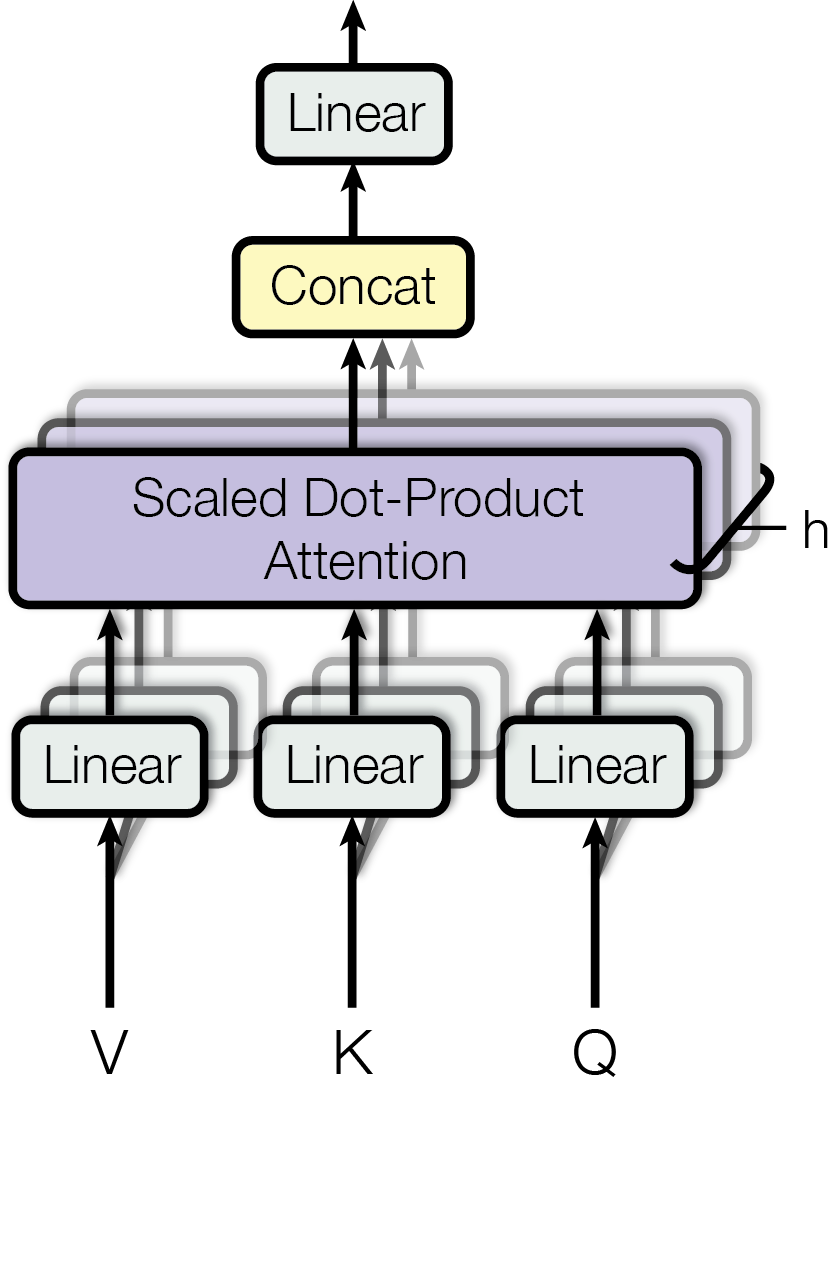
图源:Attention Is All You Need,Figure 2。原论文图意:左图是 scaled dot-product attention 的 Q/K/V 计算流程,右图是 multi-head attention 将多组 attention 并行后拼接再投影。
单个 attention head 只能在一套相似度空间里读取信息。Multi-head attention 等于让模型同时用多套“问题-匹配-读取”规则看同一段序列:有的 head 可能关注局部语法,有的关注长距离依赖,有的关注对齐关系。最后的线性投影再把这些视角合并起来。
Self-Attention 和 Cross-Attention
Self-Attention
Q、K、V 都来自同一个序列。例如 LLM 中每个 token 读取上下文中的其他 token。
Cross-Attention
Q 来自主干序列,K/V 来自外部条件。例如扩散模型中,图像 latent 的 query 去读取文本 embedding 的 key/value,从而让图像生成受 prompt 控制。
一个极简伪代码:
1 | # self-attention |
为什么 Attention 强也贵
Self-Attention 的核心矩阵是 ,其中 是序列长度。序列越长,attention 计算和显存压力越大。
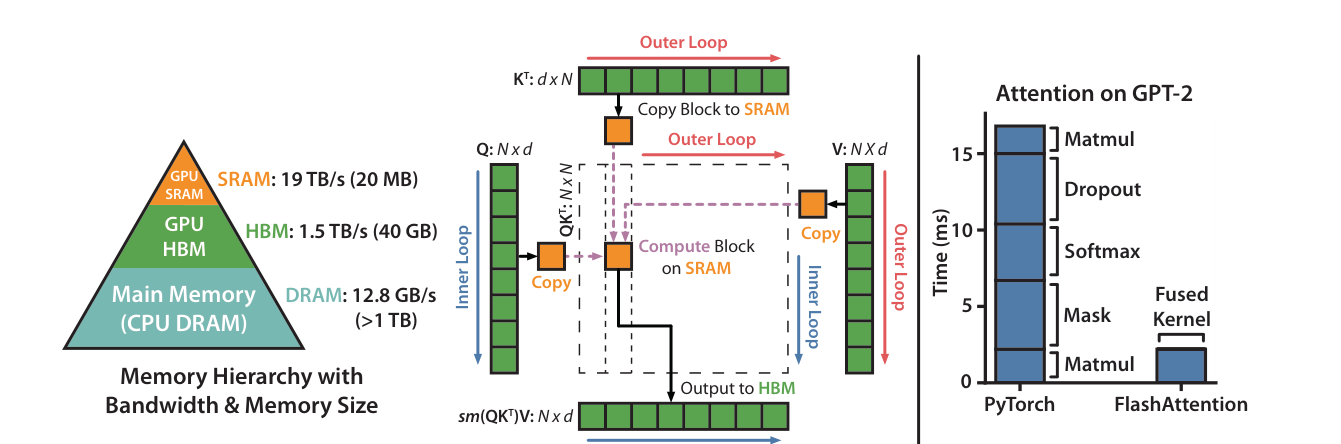
图源:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,Figure 1。原论文图意:FlashAttention 用 tiling 避免把巨大的 attention matrix 写到 HBM,并把 attention 的多步 PyTorch 实现融合成更少的高效内核。
Attention 贵不只是因为 FLOPs 多,还因为朴素实现会把 score、mask、softmax、dropout 等中间结果反复读写到 HBM。FlashAttention 图里的核心证据是:把 Q/K/V 分块搬进 SRAM 并融合计算,可以避免物化完整 矩阵。这解释了为什么同样数学公式,kernel 和 memory layout 会让长上下文吞吐差一个量级。
4.1 算一遍:视觉 token 一多,score matrix 先爆
沿用前面的机器人世界模型例子:4 路相机、16 帧、224x224、14x14 patch,共 16,384 个视觉 token。单个 attention head 的 score matrix 是:
如果用 BF16 物化,只是一个 head 的 score 就约:
16 个 heads 就是约 8GiB,这还没算 softmax/dropout 中间结果、反向传播保存、QKV、MLP 激活和多层堆叠。FlashAttention 可以避免把完整 score matrix 落到 HBM,但它没有把 attention 的数学复杂度变成线性;如果 token 数从 16k 涨到 65k, 仍然会把算力和调度压力推上去。
所以真正的取舍链是:
1 | 症状:多相机长历史一接入,显存爆或 token/s 掉到不可用 |
这解释了为什么长上下文推理会重点优化:
- KV cache:缓存历史 token 的 key/value,避免解码每一步重复计算完整上下文。
- FlashAttention:重排 attention 计算和显存访问,减少中间矩阵落显存的成本。
- sliding window attention:只让 token 关注附近窗口,牺牲部分全局交互换取更低复杂度。
- context compression:压缩或摘要长历史,把有限上下文留给最关键证据。
- prefix cache:复用相同前缀的 KV 结果,适合模板化 prompt 或多请求共享上下文。
如果你关心为什么长上下文还会涉及位置编码、causal mask、padding mask 和 KV cache,可以继续看 位置编码与上下文 Mask。
进阶读法:技术报告里的 Transformer、KV cache、MLA 与 MoE
读 DeepSeek-V3、Kimi K2、Qwen3 这类技术报告时,Transformer 已经不只是“Q/K/V + MLP”这张课堂图了。它更像一个系统接口:attention 决定长上下文怎么存,FFN 决定参数容量怎么用,router 决定 token 会被送到哪台机器上的哪个 expert。
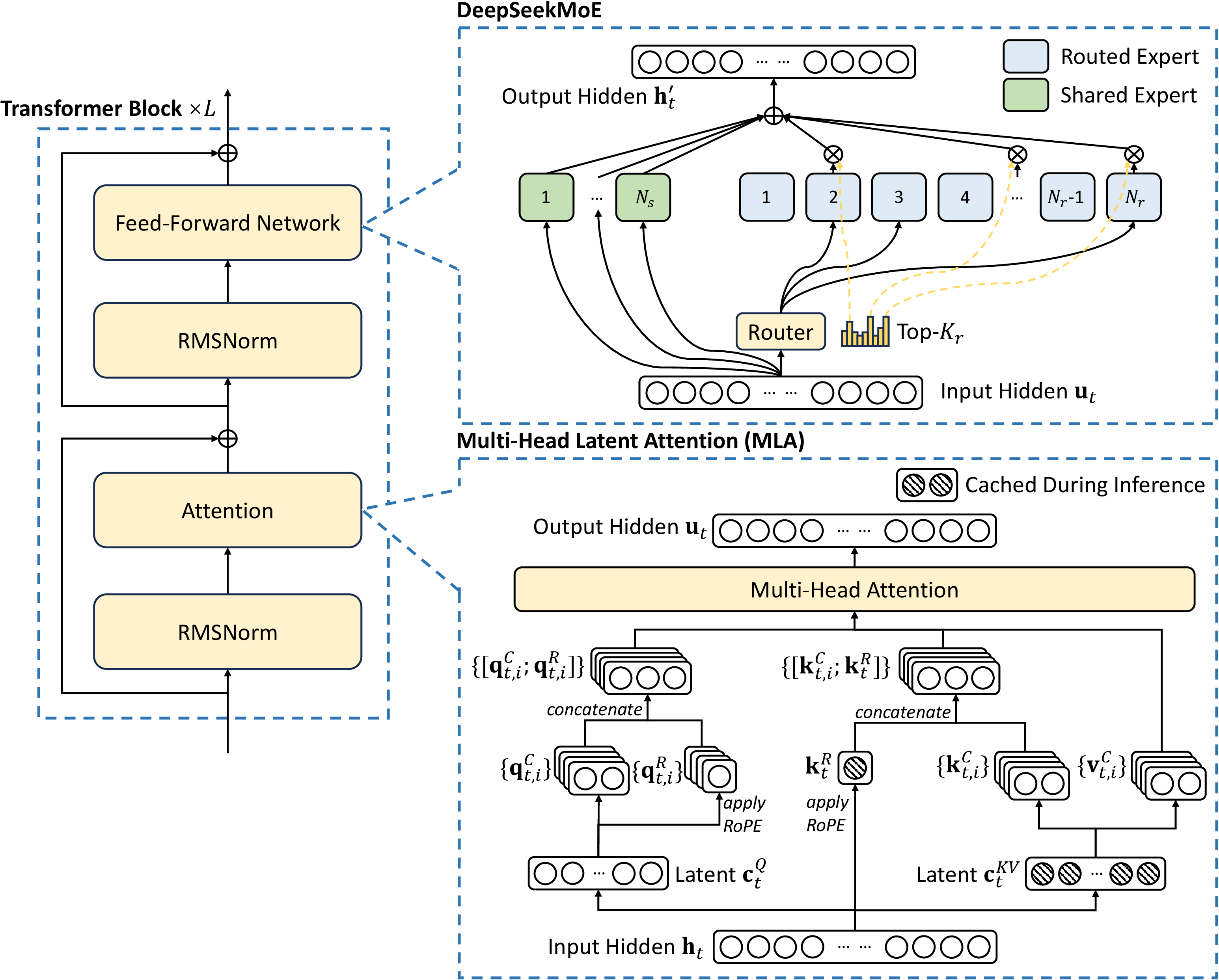
图源:DeepSeek-V3 Technical Report,Figure 2。原论文图意:DeepSeek-V3 的 Transformer block 采用 MLA 和 DeepSeekMoE;MLA 缓存压缩 latent 与 RoPE key,MoE 由 shared experts 和 routed experts 共同组成。
左边仍是熟悉的 Transformer block:attention、FFN、RMSNorm、残差。真正需要补的是右边两个放大框。MLA 解决的是长上下文推理时 KV cache 太大的问题;MoE 解决的是“想要更多参数容量,但不想每个 token 都跑完整参数”的问题。也就是说,现代大模型架构的很多创新并不是换掉 Transformer,而是在 Transformer 的两个热区上做系统化改造。
5.1 KV cache 不是小细节
自回归推理时,每生成一个新 token,模型都要读取历史 token 的 key/value。标准 MHA 会在每层、每个历史 token 上缓存完整 K/V,序列一长,显存就像滚雪球一样增长。很多长上下文模型不是算力先爆,而是 KV cache 先把显存吃满。
MLA 的直觉可以理解成“给历史笔记做压缩索引”。模型不再把每个 token 的完整 K/V 原样存下来,而是缓存更紧凑的 latent 表示和必要的位置信息,真正做 attention 时再展开需要的部分。这样做不会让长上下文免费,但会把服务时的内存曲线压低。
5.2 MoE 的关键是 activated params
MoE 最容易被误读成“参数越多,每个 token 计算越多”。实际上稀疏 MoE 的核心是:
1 | 总参数很大 |
例如 DeepSeek-V3 报告里的 671B total params / 37B activated params,Kimi K2 报告里的 1.04T total params / 32.6B activated params,都在强调同一件事:模型仓库很大,但每次只打开其中少数几个抽屉。读 MoE benchmark 时,应同时看 total params、activated params、active experts、shared experts 和路由策略,而不是只盯总参数。
5.3 Router 也是系统设计
MoE 里的 router 不只是一个数学函数。它会决定 token 被送到哪些 expert;如果 expert 分布在不同 GPU 或节点上,router 也间接决定了通信路径。某些 expert 过热,就会拖慢对应设备;负载均衡太强,又可能破坏 expert specialization。
这就是为什么 DeepSeek-V3 会讲 auxiliary-loss-free load balancing,Kimi K2 会讲 sparsity scaling 和训练基础设施。MoE 的真实难点不是“把 MLP 复制很多份”,而是让模型容量、专家分工、通信成本和训练稳定性同时成立。
| 技术报告常见词 | 它在基础层面对应什么 | 读的时候先问 |
|---|---|---|
| KV cache / MLA / GQA | 历史 token 的 K/V 如何存和读 | 长上下文显存是否可控 |
| total / activated params | 参数容量和单 token 计算的分离 | 每个 token 实际跑了多少参数 |
| routed / shared experts | 通用能力与专家能力的分工 | router 是否稳定、专家是否过热 |
| all-to-all | MoE token dispatch/gather 通信 | 通信是否吃掉训练吞吐 |
所以,学 Transformer 不应停在“attention 会看上下文”。读技术报告时更有用的问题是:上下文怎么缓存,参数怎么稀疏激活,token 怎么路由,通信怎么隐藏,最后这些设计是否真的换来了更好的训练和服务效率。
Transformer Block 的基本结构
一个常见 block 可以写成:
1 | function TransformerBlock(x): |
这里的残差连接和归一化非常关键。没有它们,深层 Transformer 很难稳定训练。
和后续专题的关系
- 扩散模型中的 DiT:图像 patch token 进入 Transformer 去做去噪。
- VLM 架构与训练:图像 token 和文本 token 如何连接。
- 推理系统:KV cache 和 attention 决定长上下文成本。
- 算子与编译器:FlashAttention 和 GEMM 是 Transformer 性能核心。
- 线性层、MLP 与 GEMM:理解 QKV 投影、MLP 和矩阵乘热路径。
- Mamba 与混合 SSM 架构:理解为什么一些新模型用 recurrent state 替代大量 attention,并保留少量 attention 做混合架构。
本页结论
Transformer 的核心不是“一个大模型名字”,而是一套 token 之间动态通信的机制。理解 token、embedding、Q/K/V、self-attention 和 cross-attention,就能读懂很多现代 AI 系统的共同骨架。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:位置编码与 Mask:顺序和可见性。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:Transformer 输入与注意力
- Author: Charles
- Created at : 2025-07-13 09:00:00
- Updated at : 2025-07-13 09:00:00
- Link: https://charles2530.github.io/2025/07/13/ai-files-foundations-transformer-attention-and-tokenization/
- License: This work is licensed under CC BY-NC-SA 4.0.