
推理:GPU Kernel、Batching 与显存
这一页把 推理服务系统 里的 queue、prefill、decode 和 KV cache 落到 GPU 执行层。你不需要先会写 CUDA,但要能判断:慢是因为 GPU 算不过来,还是因为 batch 太碎、KV 访存太重、量化 kernel 没命中,或者调度让用户等太久。
从公式回到 GPU 时间线
请求总时延仍然先拆成:
这行式子在说:请求总耗时可以拆成排队、prefill、decode、后处理和网络传输几段;本页主要关心 GPU 上最重的 与 。
GPU 页面重点看中间两段:
| 阶段 | GPU 上主要发生什么 | 常见瓶颈 |
|---|---|---|
| prefill | 大块 GEMM、长上下文 attention、写 KV | Tensor Core 利用率、attention kernel、HBM 带宽 |
| decode | 小步 GEMM、读历史 KV、采样和后处理 | KV 访存、batch 太小、kernel launch、shape 碎 |
TTFT 通常受 影响很大;TPOT 更接近 decode 稳态。若只看全局 tokens/s,就容易把 prefill 问题错当成 decode 问题,或把调度问题错当成 kernel 问题。
Prefill 为什么更像训练
Prefill 一次处理所有输入 token。输入长度为 ,batch 为 时,很多矩阵乘的形状比较大,GPU 更容易发挥 Tensor Core 吞吐。
常见优化包括:
| 方法 | 直觉 | 风险 |
|---|---|---|
| 更大的 prefill batch | 合并更多输入,摊薄启动和调度开销 | 新请求等待更久,TTFT 变差 |
| FlashAttention / 高效 attention | 减少 attention 中间矩阵读写 | 需要匹配 dtype、shape 和 mask |
| prefix cache | 复用系统 prompt 或共享前缀 | prompt 版本和权限隔离要做好 |
| chunked prefill | 长输入切块,避免一次阻塞 decode | 调度更复杂,可能引入额外等待 |
Prefill 最常见的错觉是“只要 GPU 利用率高就好”。如果长文档 prefill 抢占短聊天 decode,GPU 看起来很忙,用户却会觉得系统卡住。
Decode 为什么更难跑满 GPU
Decode 每一步通常只生成一个 token。第 步成本可以粗略理解为:
decode 的难点不是某一步公式复杂,而是它要重复很多次,并且每一步的活跃请求集合都可能变化。
Batching:吞吐和等待时间一起变
Continuous batching 的核心公式是:
batching 的收益和风险:
| 目标 | 更大 batch 可能带来什么 | 需要同时监控什么 |
|---|---|---|
| 吞吐 | GPU 更少空转,tokens/s 上升 | queue time 是否上升 |
| TTFT | 有时可复用批处理,但也可能等 batch | P95/P99 TTFT |
| TPOT | decode kernel 更饱满 | 长短请求混合后的 per-bucket TPOT |
| 公平性 | 高吞吐池更便宜 | 短请求是否被长请求拖住 |
因此 batching 参数不能只按全局 tokens/s 调。在线服务通常要按长度、SLO、租户、模型、LoRA、采样参数分桶,让相似请求更容易合并。
KV Cache 是显存系统的核心
KV cache 数量级:
这个公式在 GPU 页面有三个含义:
- 越长,每个 decode step 要读的历史越多;
- 越大,同时常驻的 KV 越多;
- 从 BF16 降到 INT8 可以省显存,但需要看 dequant 和 kernel 支持。
Paged KV 把 cache 拆成 block/page 管理,减少连续显存需求,但会引入地址间接和 page locality 问题。监控时不能只看显存总量,还要看 free page 分布、fragmentation、page reuse、eviction 和 page miss。
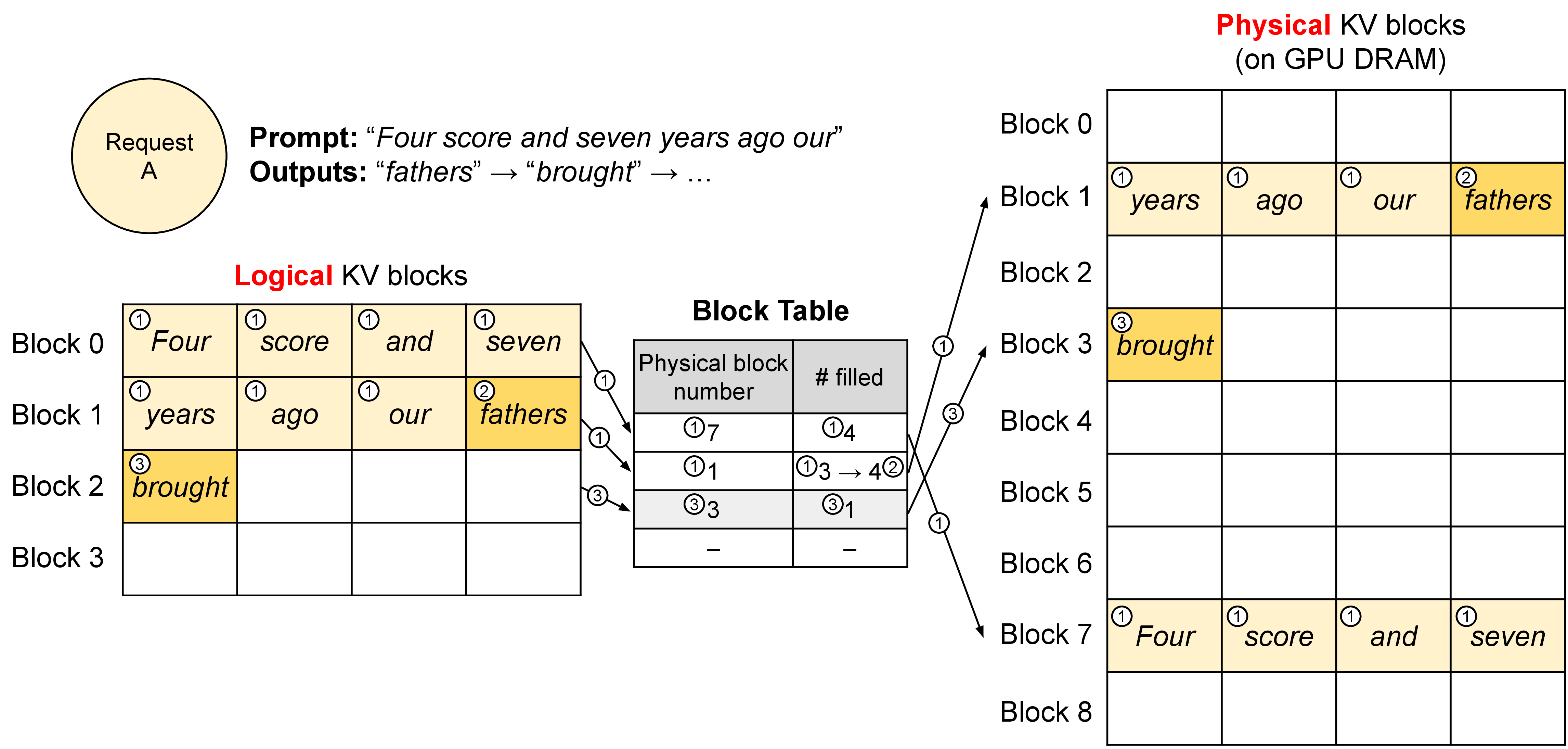
图源:Efficient Memory Management for Large Language Model Serving with PagedAttention,Figure 5。原论文图意:vLLM 用 block table 把 logical KV blocks 翻译到 physical KV blocks,使请求的 KV cache 不必连续存放。
这张图怎么看。
logical block 是请求语义上的上下文顺序,physical block 是显存里的实际位置。block table 负责翻译。这样系统可以灵活复用和回收 KV,但 decode attention kernel 每一步都要按表找到历史 KV,因此 page 布局和局部性会影响 TPOT。
Roofline 直觉:算力不等于速度
GPU 性能常用 roofline 直觉理解:
如果一个操作搬很多数据但计算很少,它就更容易 memory-bound;如果计算量很大、数据复用好,它才更可能 compute-bound。推理 decode 里 KV 读取、RMSNorm、embedding gather、dequant 和 logits 后处理经常受带宽或 launch 开销限制。
量化为什么不等于一定更快
Low-bit survey 的数据传输图很适合说明这个坑:低比特会减少某些数据搬运,但也可能增加 dequant、scale 读取、layout 转换和不友好 shape 的开销。
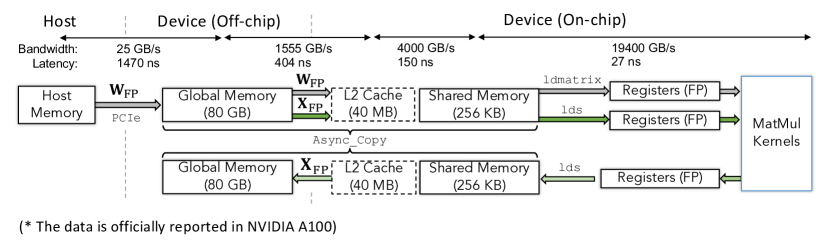
图源:A Survey of Low-bit Large Language Models,Figure 4。原论文图意:以 NVIDIA A100 为例展示 weight 和 activation 在 host、global memory、L2、shared memory、registers 与 MatMul kernel 之间的数据传输。
这张图怎么看。
顺着箭头看数据在哪里移动:host、global memory、L2、shared memory、registers。推理慢时不一定是矩阵乘不够快,也可能是数据在层级之间搬得太多。量化只有在 kernel 能把低比特存储、dequant 和 matmul 高效融合时,才更可能转成真实加速。
KV cache 量化也一样。它能减少 KV 存储和读取,但 attention 前往往需要 dequant:
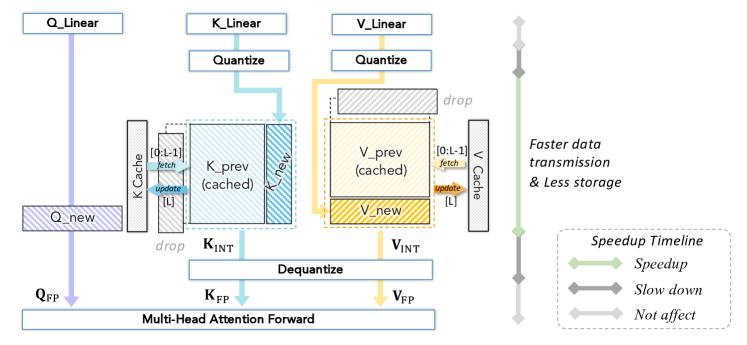
图源:A Survey of Low-bit Large Language Models,Figure 6。原论文图意:展示 quantized KV cache 如何减少缓存存储和数据传输,并在 attention forward 前 dequantize。
这张图怎么看。
左边是压缩后的 KV 存储,右边是 attention 计算前的恢复路径。收益来自少存少搬,代价来自 dequant 和可能的精度损失。长上下文服务尤其要用长任务质量回归验证,不能只看短 benchmark。
Kernel 热点怎么分
| 热点 | 出现在哪里 | 看什么指标 |
|---|---|---|
| Prefill attention | 长输入、RAG、PDF | prefill time、HBM bandwidth、attention kernel time |
| Decode attention | 长输出、长会话 | TPOT、KV read bandwidth、page miss |
| GEMM / quant GEMM | 权重计算 | Tensor Core util、kernel hit rate、dtype |
| Fusion | 小算子密集路径 | kernel launch count、memory round trip |
| Sampling / logits | 大 vocab、结构化输出 | logits processor time、CPU/GPU sync |
| Communication | TP/PP/EP/MoE | all-reduce/all-to-all time、rank imbalance |
新手排查顺序建议:
- 先按 queue / prefill / decode / post 拆时延;
- prefill 慢,先看输入长度、prefix cache、attention kernel;
- decode 慢,先看 batch、KV cache、page locality、sampling;
- 显存紧,先看 KV 而不是只看权重;
- tokens/s 好但 P99 差,先看分桶和调度;
- 只有确认热路径在 kernel 上,再考虑写新 kernel 或换 runtime。
vLLM 的 Triton attention backend 文章很适合把这个排查顺序落到 kernel 设计:先确定热路径是不是 attention,再看 tile 怎么映射到 query / key / value,autotuning 在哪些 shape 上选择配置,CUDA graphs 是否减少 launch overhead,persistent kernel 是否把更多工作留在 GPU 上。它的启发不是“所有人都要写 Triton”,而是 GPU 优化必须从 workload 形状、memory traffic 和 runtime 调度一起看。
真实排查案例:Batch 变大后体验下降
症状:连续批处理参数调大后,tokens/s 提升 22%,但聊天产品 TTFT P95 从 1.1s 涨到 2.0s。
关键指标:实际 batch size 变大,GPU utilization 更高;queue time 和 prefill waiting time 同时上升;短请求被长文档请求拖住。
判断:GPU 层吞吐更好,但产品层 SLO 变差。问题不是 kernel 慢,而是 batching 策略没有区分短交互和长文档。
修复:按输入长度和 SLO 分队列;短请求设置更小 max wait;长文档进入吞吐池;灰度指标同时看 tokens/s、TTFT、TPOT 和 P99。
读完以后怎么判断
GPU 推理优化不是微基准游戏。真正要改善线上体验,需要同时看请求分桶、queue、prefill、decode、KV 生命周期、kernel 热点和 SLO。一个优化只有在真实请求桶里同时改善成本、延迟和质量,才算真的有效。
外部精读
- vLLM Triton Attention Backend Deep Dive:学习 attention kernel、Triton tile、autotuning、CUDA graphs 和 persistent kernels 如何连成工程链。
- CUTLASS GEMM API docs:学习 GEMM 从 threadblock、warp 到 instruction 的层级。
- NVIDIA CUTLASS 3.x blog:学习如何用可组合抽象解释 kernel,而不是只列 API。
- vLLM PagedAttention blog:学习 KV cache 为什么是推理系统容量瓶颈。
相关阅读与下一步
- 外部材料:vLLM PagedAttention 博客。
- 外部材料:TensorRT-LLM KV Cache System。
- 外部材料:SGLang 文档。
- 站内下一步:推理系统专题。
- 站内下一步:推理运行时。
- 站内下一步:缓存、路由与投机解码。
- Title: 推理:GPU Kernel、Batching 与显存
- Author: Charles
- Created at : 2025-07-15 09:00:00
- Updated at : 2025-07-15 09:00:00
- Link: https://charles2530.github.io/2025/07/15/ai-files-inference-gpu-kernels-batching-and-memory-systems/
- License: This work is licensed under CC BY-NC-SA 4.0.