
推理:容量规划与推理优化
这篇回答的问题。 如何理解“容量规划与推理优化”背后的核心机制、适用边界和下一步阅读路径。
推理系统上线后,团队很快会遇到两个问题:现在还能撑多久,下一步该先优化哪里。这两个问题表面像“算资源”,本质是在做系统建模。大模型推理容量不是固定常数,而是请求分布、输入输出长度、模型结构、batch 策略、缓存命中、工具调用和 SLO 共同作用的结果。
这页把推理优化从零散技巧整理成容量规划和瓶颈归因框架。
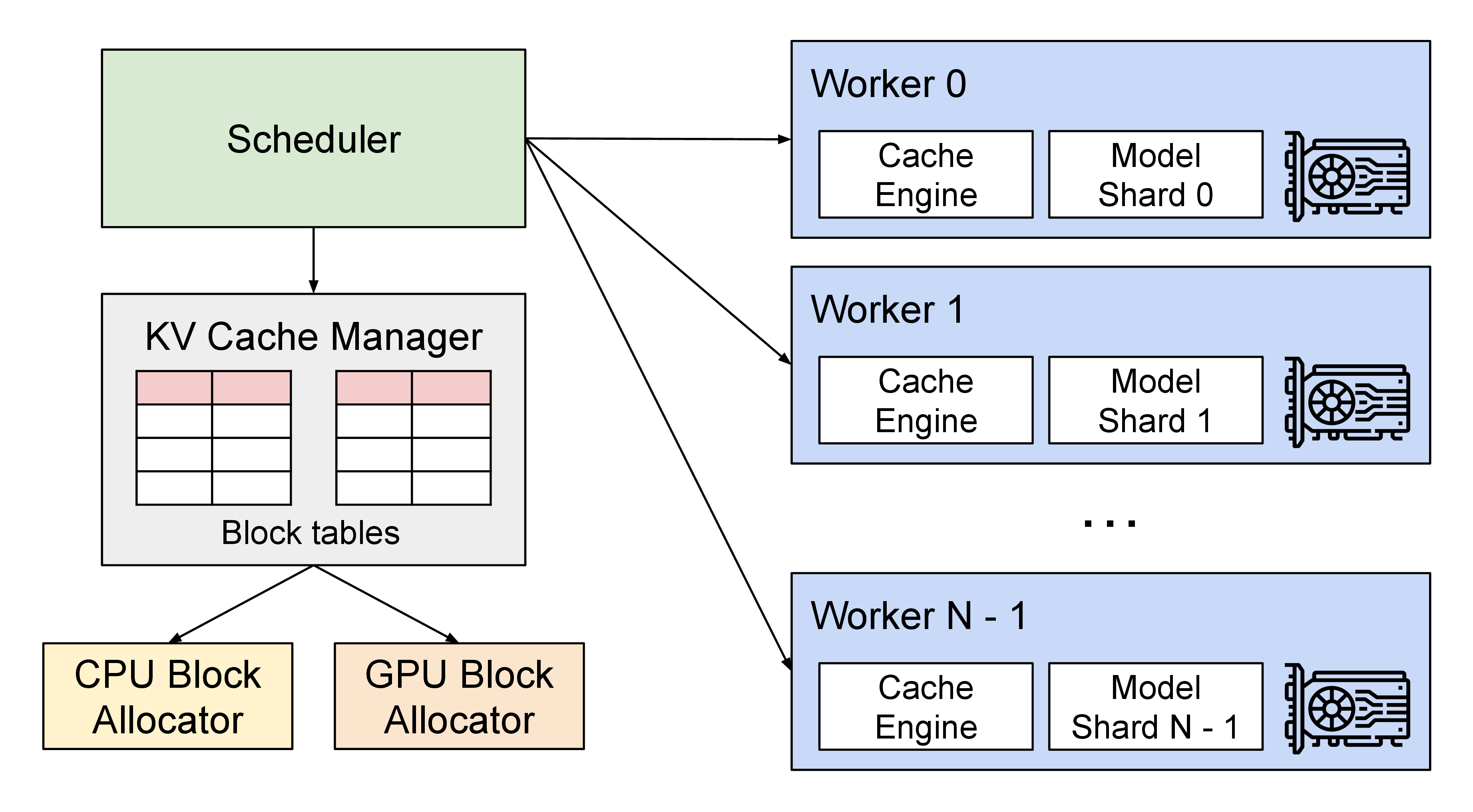
图源:vLLM 官方博客。原图表达 serving runtime 中 scheduler、KV cache manager、allocator 与 GPU worker 的协作;本站读法是把容量规划落到请求队列、prefill/decode、KV 和 worker 饱和度,而不是只看 GPU 利用率。它不能证明某个优化动作一定优先,优先级仍由 workload 分桶决定。
请求画像先于资源估算
设请求到达率为 ,平均服务时间为 ,负载强度可粗略写成:
当 接近系统有效处理能力时,排队时间和尾延迟会快速恶化。LLM/VLM 系统中 不是常数,通常更接近:
因此容量规划必须先统计真实请求画像,包括输入长度和输出长度分布、长上下文和多模态占比、工具调用轮次和外部依赖耗时、模型路由分布、prefix / KV cache 命中率,以及峰值流量和多租户叠加。
不要只看平均 token。少量超长 PDF、代码仓库或多图请求,可能占掉大部分算力和显存。
Prefill、Decode 与 Queue
推理总延迟至少应拆成:
Prefill 一次性处理全部输入 token,长上下文时成本高;decode 每次只生成少量 token,但要重复很多轮,并持续访问 KV cache。Queue 则反映容量、调度和优先级是否健康。
很多“延迟高”不能笼统归因于模型太大,而要问它究竟来自 queue、prefill、decode、KV cache、工具/网络,还是调度和 batching 没组织好。不同瓶颈对应完全不同的优化动作。
分层优化清单
| 层级 | 关注点 | 常见动作 |
|---|---|---|
| 请求层 | 输入/输出长度、RAG 拼接、多模态大小 | prompt 收缩、检索裁剪、输出限长、任务分流 |
| 调度层 | queue、continuous batching、priority、routing | 动态 batching、优先级、SLA 隔离、路由 |
| 模型层 | 参数量、量化、draft、early exit | 量化、蒸馏、speculative、模型分层 |
| 缓存层 | prefix、KV、工具结果 | prefix cache、KV paging、eviction、结果缓存 |
| Kernel 层 | GEMM、attention、norm、decode kernel | FlashAttention、paged attention、fused kernels |
| 系统层 | 多实例、网络、存储、外部工具 | 横向扩容、隔离、降级、异步化 |
优化顺序应由瓶颈决定,而不是由技术新不新决定。很多团队一上来做 speculative 或手写 kernel,但真正瓶颈可能只是 prompt 太长、RAG 拼接过量、路由不合理或 cache 命中低。
容量模型
容量规划至少要估计三类资源:计算容量看 prefill FLOPs、decode step 和 Tensor Core 利用率;显存容量看权重、KV cache、batch 中间状态和碎片;服务容量看 queue、batching、工具、网络和实例副本。
一个实用方法是按请求桶建模,而不是建一个全局平均模型:
| 请求桶 | 主要成本 | 典型优化 |
|---|---|---|
| 短问答 | queue 和 launch 开销 | batching、轻量模型、prefix cache |
| 长文档 | prefill 和 KV | 检索裁剪、上下文压缩、prefill 分离 |
| 长输出 | decode | speculative、draft model、输出策略 |
| 工具 agent | 外部调用和多轮 | 工具缓存、状态压缩、异步执行 |
| 多模态 | 编码器和跨模态 token | 图像裁剪、视觉缓存、模型路由 |
如果 10% 的长请求占据 60% 的 GPU 时间,优化策略就不能平均铺开。
容量规划闭环图
flowchart LR
A["请求日志"] --> B["请求分桶"]
B --> C["成本归因: queue/prefill/decode/tool"]
C --> D["容量模型"]
D --> E["优化动作"]
E --> F["灰度压测"]
F --> G["SLO 与成本复核"]
G --> A
这张图说明容量规划不是一次性估算,而是运营闭环。请求分布会变,模型版本会变,缓存命中会变,工具链也会变;每次变化都要更新容量模型,否则优化策略会慢慢和真实系统脱节。
一个容量表口径
| 请求桶 | QPS | P95 输入/输出 | 主瓶颈 | 动作 |
|---|---|---|---|---|
| 短问答 | 20 | 1k / 200 | queue、decode launch | continuous batching |
| 长文档 | 3 | 32k / 600 | prefill、KV | 分池、上下文裁剪 |
| 工具 agent | 2 | 4k / 多轮 | 外部工具 | 工具缓存、异步 |
| 多模态 | 1 | 多图 / 300 | vision encoder | 图像缓存、路由 |
SLO 驱动优化
容量规划必须和 SLO 绑定。常见指标包括 TTFT、TPOT、p50/p95/p99 请求延迟、tokens/s、requests/s、错误率、超时率、降级率、单请求成本、单 token 成本,以及任务成功率和质量指标。
不同业务的 SLO 不同。企业问答可以接受更高延迟但要求证据可靠;屏幕 agent 更看重每步交互延迟;批处理文档分析更看重吞吐和成本。没有 SLO,优化会变成无限追求更快,却不清楚哪些改动值得做。
降级与扩容策略
当资源紧张时,系统不应只有“一起变慢”。应提前设计降级:低优先级请求切到小模型,长上下文请求限制最大输入,关闭多样本采样、二次重排或高成本工具,批处理任务延后执行,高风险任务保留强模型和人工审核,p99 恶化时关闭 speculative 或降低 batch。
扩容也要按瓶颈扩。若瓶颈是 KV 显存,单纯增加计算实例未必有效;若瓶颈是外部工具,增加 GPU 也不会改善端到端延迟。
验收清单
做推理优化前后,至少回答这些问题:瓶颈属于 queue、prefill、decode、KV、tool、network 还是 kernel;优化收益在哪些请求桶成立;p95/p99 是否改善,是否牺牲 TTFT;质量、错误率和降级率是否变化;cache 命中、KV 占用和 batch 形态是否改变;峰值流量下收益是否还成立;回退路径是否稳定;单请求成本是否真的下降。
推理优化的核心不是收集技巧,而是建立请求画像、瓶颈分解、容量模型和 SLO 之间的闭环。
真实排查案例:扩 GPU 没救 P99
输入症状:峰值时段 P99 超时,团队先把 GPU 实例翻倍,但 P99 只从 13s 降到 11s,成本几乎翻倍。
关键指标:GPU util 不高但 queue time 高;外部检索和工具调用 P95 接近 4s;长上下文请求触发更多 prefill;失败重试率在高峰时上升,进一步放大流量。
Nsight / trace 观察:GPU trace 没有长时间饱和,反而存在空洞;系统 trace 显示请求大部分时间卡在检索、重排、工具 I/O 和重试队列,进入 GPU 时已经接近超时预算。
判断:容量瓶颈不在 GPU compute,而在请求链路和重试放大。单纯扩 GPU 只能改善局部阶段,无法缩短端到端关键路径。
修复:按阶段拆 SLO:检索、重排、prefill、decode、工具、后处理分别限时;高峰关闭二次重排和低价值工具;对超时请求禁止盲目重试,改为降级模型或返回部分结果;成本账改成“每成功任务成本”。
反例:如果 trace 显示 GPU queue 和 prefill/decode 阶段长期饱和,且外部工具时间很小,扩 GPU 或分池才是正确方向。容量规划必须先定位瓶颈层。
相关阅读与下一步
- 外部材料:vLLM PagedAttention 博客。
- 外部材料:TensorRT-LLM KV Cache System。
- 外部材料:SGLang 文档。
- 站内下一步:推理系统专题。
- 站内下一步:推理运行时。
- 站内下一步:缓存、路由与投机解码。
- Title: 推理:容量规划与推理优化
- Author: Charles
- Created at : 2025-07-20 09:00:00
- Updated at : 2025-07-20 09:00:00
- Link: https://charles2530.github.io/2025/07/20/ai-files-inference-optimization-checklist-and-capacity-planning/
- License: This work is licensed under CC BY-NC-SA 4.0.