
推理:上下文压缩与 KV 内存管理
长上下文系统的真正瓶颈,常常不是模型参数,而是历史上下文如何存、如何压、何时丢。一旦请求从 4k 扩到 32k、128k 甚至更长,KV cache 显存、prefill 开销和检索拼接策略都会迅速成为主问题。
长上下文系统的本质,不是把窗口一味做大,而是把记忆管理做成系统工程。
长上下文不等于“模型记性无限好”。窗口越长,prefill 越贵,KV cache 越大,历史噪声越多。真正可靠的系统会区分当前必需信息、可摘要信息、可检索信息和可丢弃信息。
一场三小时会议不应该把逐字稿全部塞进下一次讨论。更好的做法是保留决策、待办、约束和争议点,把闲聊和已废弃方案降级或归档。上下文压缩和 KV 淘汰也是在做类似的记忆整理。
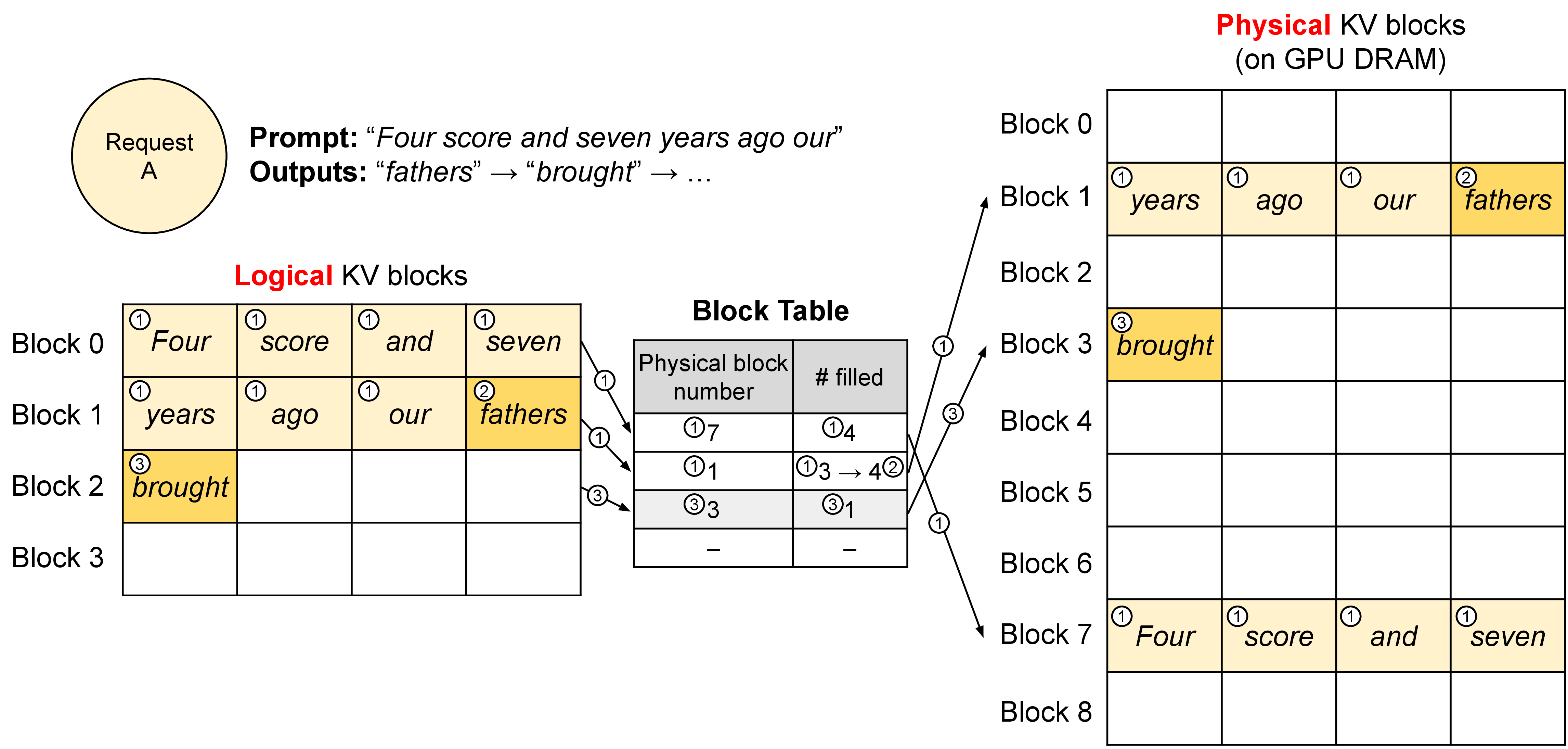
图源:Efficient Memory Management for Large Language Model Serving with PagedAttention,Figure 5。原论文图意:vLLM 用 block table 把 logical KV blocks 翻译到 physical KV blocks,使请求的 KV cache 不必连续存放。
这张图把“上下文很长”落到内存管理问题上:每段历史 token 生成的 KV 都要有物理存放位置。logical block 保持序列语义顺序,physical block 负责实际显存布局。理解了这个映射,后面看 KV eviction、prefix cache、swap、CPU/GPU 分层和多租户隔离会更自然。
长上下文为什么贵
KV cache 大小近似随序列长度线性增长:
其中 是并发数, 是层数, 是上下文长度, 是头数, 是每头维度, 是每元素字节数。
长度翻倍,缓存几乎翻倍;模型越深、头越多、精度越高,缓存越贵。权重量化只能解决参数显存,不会自动解决 KV 增长。
Prefill 和 decode 的问题也不同:prefill 是一次性处理大量 token,计算和带宽压力高;decode 每步新增 token 少,但历史 KV 持续存在并影响每一步注意力。
上下文不是越长越有用
很多真实请求里,大量历史 token 对当前回答边际价值很低。企业助手长对话中可能保留了寒暄、重复确认、旧工具日志和已修正的错误中间结论;真正有价值的是最新目标、关键约束、已确认事实和当前工具状态。
因此上下文管理本质是一种记忆选择问题:
- 哪些内容必须高保真保留;
- 哪些内容可以摘要;
- 哪些内容可以转入外部记忆;
- 哪些内容可以丢弃;
- 哪些内容需要结构化而不是自然语言化。
好的长上下文系统不是“什么都记”,而是“记得有层次”。
压缩方式
| 方法 | 优点 | 风险 |
|---|---|---|
| 摘要压缩 | 简单、可读、适合纯文本对话 | 丢细节、摘要幻觉、约束模糊 |
| 结构压缩 | 保留目标、事实、工具状态、待办 | 需要 schema 和状态更新逻辑 |
| 向量检索 | 历史不必常驻上下文,可扩展 | 召回漏检或错召回会造成失忆 |
| Token 级压缩 | 直接减少序列长度 | 压缩标准不稳,工程复杂 |
| Learned memory | 模型学习保留关键状态 | 可解释性和回归更难 |
Agent 系统通常更适合结构压缩,因为很多记忆不是故事,而是程序状态:哪个工具调用过、API 返回什么、网页表单填到哪里、哪些约束仍未满足。纯自然语言摘要很容易把动作状态压没。
KV 淘汰
如果显存有限,就必须淘汰或降级。可以把每段记忆看成有价值 和成本 ,在预算 内保留最大价值集合:
常见策略包括:
- FIFO:实现简单,但可能丢掉早期关键约束;
- 最近窗口:适合局部对话,但不适合长任务记忆;
- Attention-aware:按历史注意力或重要度保留,但计算和稳定性更复杂;
- Role-aware:系统 prompt、用户目标、工具结果优先;
- Segment-aware:按文档、回合、工具调用块淘汰;
- Risk-aware:高风险约束和安全相关状态强保留。
KV 淘汰不是纯缓存问题,它会影响回答质量和任务一致性。任何 eviction 策略都需要任务级回归。
内存分层
长上下文系统应有多层记忆:
| 层级 | 保存什么 | 访问特点 |
|---|---|---|
| Prompt 内上下文 | 当前任务最关键 token | 最贵但最可靠 |
| KV cache | 已 prefill 的历史 token 表示 | decode 依赖,显存敏感 |
| 结构化状态 | 目标、约束、工具状态、事实表 | 低成本、可控、适合 agent |
| 向量库/检索 | 长期历史和外部知识 | 召回质量决定效果 |
| 冷存储日志 | 全量历史、审计、复盘 | 不参与实时推理 |
设计目标是让高价值信息留在高成本层,低频或低置信信息退到低成本层。把所有东西都塞进 prompt,是最简单但通常最贵的方案。
质量风险
上下文压缩和 KV 淘汰常见失败包括:
- 关键约束被摘要丢失;
- 旧错误被压缩后变成“已确认事实”;
- 检索漏召回导致模型忘记重要背景;
- KV eviction 丢掉跨轮引用;
- 工具状态和自然语言上下文不一致;
- 压缩策略在短任务上没问题,长任务中累计漂移。
因此需要专门构造长任务回归:多轮约束保持、工具状态一致性、旧事实更正、跨文档引用、长会话恢复和安全约束保留。
评测与指标
建议同时看系统指标和任务指标:
- prefill token 节省量;
- KV 显存占用、碎片率、eviction 次数;
- 压缩后 token 数和压缩耗时;
- 检索召回率、错召回率、漏召回率;
- 多轮任务成功率;
- 约束保持率和事实一致性;
- p50/p95/p99 延迟;
- 出错时是否能追溯到哪一层记忆丢失。
长上下文优化不能只看“能塞多长”。真正的验收是:在固定显存和延迟预算下,系统是否更可靠地保留了对当前决策有用的记忆。
工程上建议把压缩策略、检索策略和 KV 淘汰策略都做成可回放配置。出现质量问题时,能够复现当时哪些内容被保留、哪些内容被摘要、哪些内容被淘汰,比单纯查看最终 prompt 更有排障价值。
如果系统面向多租户或企业场景,还要把记忆层级与权限系统绑定。被压缩或转入外部记忆的内容仍然可能包含敏感信息,不能因为它不在当前 prompt 里,就忽略审计、过期和删除策略。
真实排查案例:KV 淘汰省了显存,答案开始忘约束
输入症状:长会话 agent 接入激进 KV eviction 后,单机并发提升 35%,但多轮任务中“必须使用指定工具”“不能覆盖原文件”等约束遵守率下降。
关键指标:KV 显存水位下降,eviction 次数上升;平均延迟改善,但第 8 轮以后的任务成功率下降;错误集中在跨轮约束和工具状态一致性。
Nsight / trace 观察:系统 trace 显示 eviction 在 decode 前频繁触发,GPU kernel 没有异常;回放 prompt 发现自然语言摘要保留了目标,却丢掉了约束来源和工具状态版本。
判断:这是记忆层级策略问题,不是模型能力突然下降。KV 淘汰把对当前决策仍然关键的信息移出了高保真状态,摘要层又没有承接足够结构化约束。
修复:把约束、权限、工具状态从普通文本摘要中拆成结构化 memory;KV eviction 按“决策相关性”而非单纯时间淘汰;长会话回归集加入约束保持率、工具状态一致性和旧事实更正。
反例:如果任务是单轮长文档摘要,且关键证据已经被检索片段覆盖,激进上下文压缩可能很划算。多轮 agent 和机器人闭环则不能只按 token 节省量判断。
- Title: 推理:上下文压缩与 KV 内存管理
- Author: Charles
- Created at : 2025-07-25 09:00:00
- Updated at : 2025-07-25 09:00:00
- Link: https://charles2530.github.io/2025/07/25/ai-files-inference-context-compression-kv-eviction-and-memory-hierarchies/
- License: This work is licensed under CC BY-NC-SA 4.0.