
推理:运行时:vLLM、SGLang、TensorRT-LLM
模型推理已经不只是“加载权重然后调用 generate()”。真正决定线上成本和时延的,是一层专门的运行时系统:它管理 continuous batching、KV cache、prefix cache、paged attention、量化 kernel、图捕获、路由、分布式执行、多模型共存和 tracing。vLLM、SGLang、TensorRT-LLM 代表了几条不同取舍路线。
这页和 推理服务系统、GPU Kernel、Batching 与显存、可观测性与在线评测 一起读。推理服务系统页讲资源治理,本页聚焦 runtime 选型。
推理 runtime 是模型和硬件之间的执行层:它决定请求怎么排队、KV 怎么分配、prefix 怎么复用、kernel 走哪条路径、异常 shape 怎么 fallback。选 runtime 时先看 workload,而不是先看榜单。
快餐店、宴会厅和私人订制厨房都能做饭,但组织方式完全不同。vLLM 更像通用高并发后厨,SGLang 更适合多阶段编排,TensorRT-LLM 更适合菜单稳定、硬件固定、追求极致效率的场景。
一、Runtime 在推理栈里的位置
在线推理栈可以粗略拆成:
- 网关、鉴权、配额和流量管理;
- 路由、检索、工具编排和上下文构造;
- 推理 runtime;
- kernel、通信和硬件执行;
- tracing、日志、评测和数据回流。
Runtime 主要负责:模型加载与权重布局、请求编队、prefill/decode 协同、KV cache 分配回收、prefix cache、speculative decoding、量化路径、多 GPU 执行和内部阶段 tracing。它既不是纯模型代码,也不是纯 kernel,而是模型和硬件之间的执行层。
因此 runtime 选型不是“哪个包流行”,而是推理服务系统架构选择。
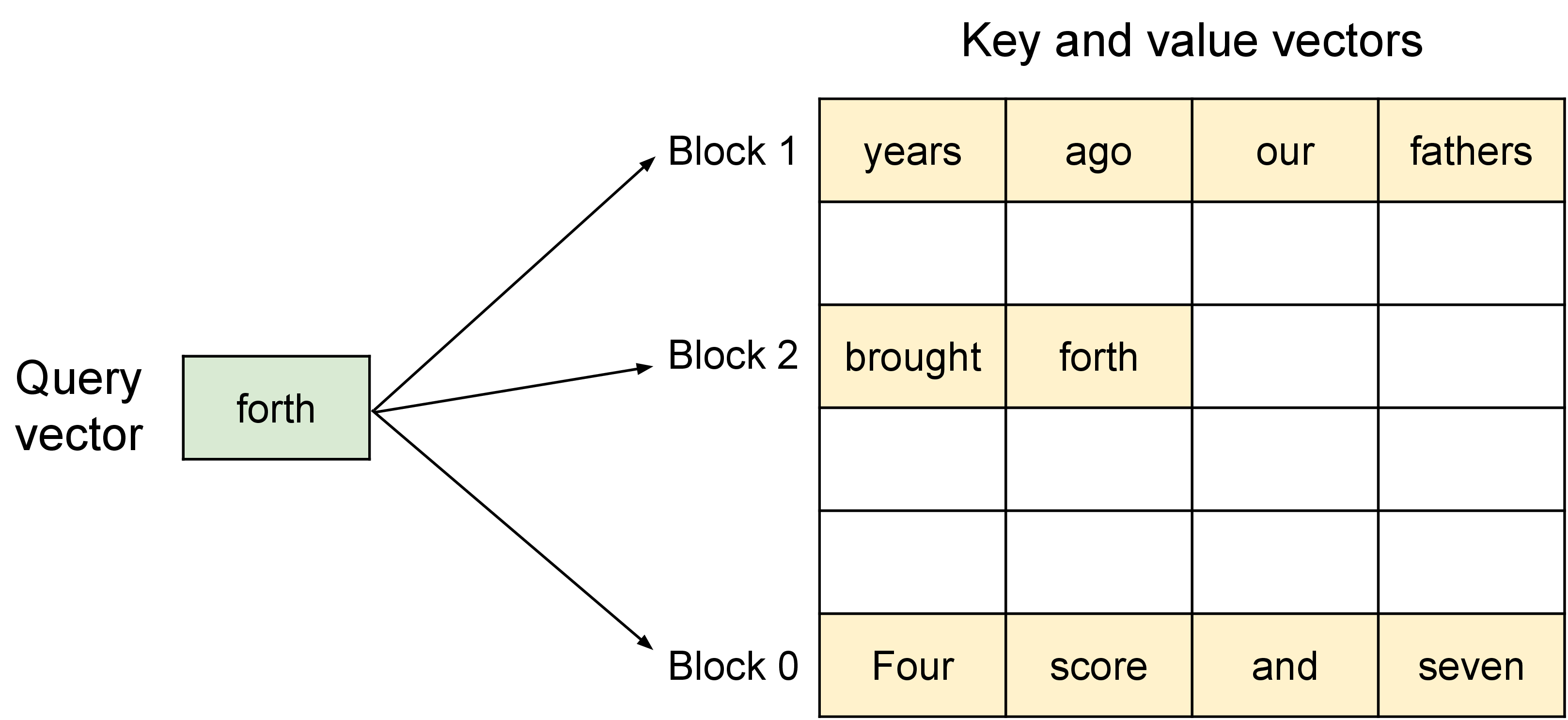
图源:Efficient Memory Management for Large Language Model Serving with PagedAttention,Figure 4。原论文图意:PagedAttention 允许 attention 的 K/V 向量存放在非连续物理内存块中,kernel 通过 block table 找到对应 KV block 并完成注意力计算。
朴素推理服务系统常为每个请求预留一大段连续 KV 空间,导致内部碎片和预留浪费。PagedAttention 的关键是把逻辑 token 序列拆成 block,再映射到不连续的物理 block。这样不同请求、beam 或并行生成分支可以更灵活地共享和回收 KV cache,显存利用率会直接影响可并发请求数。
二、三条代表路线
不同 runtime 的差异,往往来自默认假设不同。
| Runtime | 更像在优化什么 | 典型优势 | 典型代价 |
|---|---|---|---|
vLLM |
通用 LLM serving、continuous batching、Paged KV | 易用性和性能平衡,生态成熟,适合通用文本服务 | 极端硬件特化或复杂编排未必最强 |
SGLang |
复杂生成流程和编排/runtime 协同 | 更适合 agent、多阶段结构化生成、程序化请求 | 选型时要看上层流程是否真正受益 |
TensorRT-LLM |
硬件特化、图优化、部署工程 | 在固定硬件和稳定 workload 下可吃到深度优化 | 构建、转换、量化和部署链路更重 |
这不是三选一的绝对排名。通用服务常把 vLLM 作为起点,复杂 agent 系统可能更关注 SGLang 的编排能力,固定场景高吞吐部署可能更愿意接受 TensorRT-LLM 的工程约束。
三、先看 Workload,再看 Benchmark
选 runtime 前至少回答:
- 主任务是短聊天、长文档、agent、多模态还是固定批量服务;
- 更看重 TTFT、TPOT、吞吐、P99 还是单位成本;
- 是否需要多模型、多 LoRA、工具调用和结构化输出;
- 输入/输出长度分布是否稳定;
- 是否有固定硬件和稳定模型格式;
- 团队是否能维护更重的编译、量化和部署链路。
不同 workload 的关注点不同:
| Workload | 主要关注 |
|---|---|
| 高并发聊天 | continuous batching、decode 吞吐、P99、多租户 |
| 长文档问答 | prefill、prefix cache、KV 管理、长上下文 kernel |
| 复杂 agent | 请求可编程性、阶段切换、工具 trace、结构化输出 |
| 固定高吞吐部署 | 图捕获、静态 shape、量化、硬件特化 |
| 多模型级联 | 路由、fallback、模型切换成本、缓存隔离 |
单一 benchmark 很危险。固定 batch、固定长度、固定量化下的高 token/s,不代表真实混合流量里的 TTFT、P99 和成本更好。
四、核心差异:Cache、图、量化和编排
Runtime 真正拉开差距的地方通常不是“能不能生成文本”,而是以下能力。
KV 与 Prefix Cache
KV cache 是 decode 的核心资源。runtime 需要管理页面/块分配、回收、碎片、prefix 复用、多租户隔离和 speculative 临时分支。prefix cache 对企业助手、客服规则、多用户共享文档、多轮 agent 很有价值,但会引入 prompt 版本、权限隔离和失效策略问题。
图捕获与静态优化
图捕获和深度编译优化在 shape 稳定、模型固定、量化路径明确时收益明显。但真实线上输入长度、输出长度、工具路径和租户配置经常变化,这会削弱静态优化收益。越动态的 workload,越要重视 runtime 的调度弹性。
量化路径
量化不是 runtime 的外挂功能。runtime 决定权重布局、scale 访问、dequant 位置、kernel 替换、KV cache 是否量化和 fallback 路径。同一量化方案在不同 runtime 上表现不同,常常是 layout 和 kernel 协同不同。
编排能力
Agent 请求不是一次输入一次输出,而是生成、调工具、解析、再生成的多阶段程序。runtime 需要支持状态复用、阶段切换、结构化输出和 trace。复杂 agent 系统不应只看裸 token/s。
五、可观测性是 Runtime 验收的一部分
再强的 runtime,如果内部决策不可观测,线上退化就很难管理。验收时至少看:
- batch 组织过程能否追踪;
- cache 命中、淘汰、碎片是否可见;
- prefill/decode 阶段时间是否可拆;
- route 到不同 kernel/path 的原因是否可解释;
- 异常 shape、fallback 和 JIT/graph cache miss 是否有 trace;
- 多 LoRA、多模型、agent 分桶后的延迟和成本是否可见。
生产系统里,不可观测的 5% 性能损失,往往比可观测的 10% 性能损失更贵。runtime 选型必须和 tracing、replay、shadow、灰度和回滚设计一起做。
六、选型与验证流程
一个稳妥流程是:
- 画出请求生命周期,明确 runtime 影响哪些阶段;
- 用真实流量统计输入/输出长度、任务桶、租户桶、工具桶;
- 定义 TTFT、TPOT、P95/P99、成本、质量和稳定性目标;
- 在 workload-matched replay 上比较 runtime;
- 单独测试 KV、prefix cache、量化、多 LoRA、多模型、agent 路径;
- 检查 tracing 和 fallback;
- 小流量灰度,并按高价值桶观察。
优先通用 runtime 的情况:workload 变化大、多模型迭代快、需要快速接入新模型、团队更重视灵活性。优先深度优化 runtime 的情况:模型和硬件稳定、工作负载规律、目标是极致成本/时延、团队能接受更高系统复杂度。
七、最小选型清单
选型时至少写清:
- 主工作负载和长度分布;
- 质量、延迟、吞吐、成本的优先级;
- KV/prefix cache 策略;
- 量化和 kernel 路径;
- 多模型、多 LoRA、agent 编排需求;
- tracing、fallback、replay 和灰度能力;
- 部署链路、版本维护和团队能力成本。
vLLM、SGLang、TensorRT-LLM 的差异,真正值得比较的不是“谁绝对更强”,而是谁的默认假设、部署方式、可观测性和工作负载契合度更适合你的系统。
1 | def choose_runtime(workload): |
这段伪代码只是表达判断顺序:先看是否能吃静态特化,再看是否有强编排需求,否则从更通用的 serving runtime 起步。
- Title: 推理:运行时:vLLM、SGLang、TensorRT-LLM
- Author: Charles
- Created at : 2025-08-11 09:00:00
- Updated at : 2025-08-11 09:00:00
- Link: https://charles2530.github.io/2025/08/11/ai-files-inference-serving-runtimes-vllm-sglang-and-tensorrt-llm/
- License: This work is licensed under CC BY-NC-SA 4.0.