
算子与编译器:GPU 互联与拓扑映射
大模型系统的很多瓶颈不是单卡 kernel 慢,而是通信路径选错。你可以有很强的 GPU、很快的 GEMM、很成熟的并行框架,但如果张量并行跨了慢链路,MoE token all-to-all 穿过拥塞网络,或者 GPU 到 NIC 走了错误 NUMA 域,端到端吞吐仍然会塌。
核心问题
并行训练和推理把一个模型拆到多张 GPU 上。拆开以后,计算省下来的时间必须和通信增加的时间比较:
其中 可以先粗略读成:
是延迟和调度开销, 是要传的数据量,effective bandwidth 是真实可用带宽,不是宣传页里的峰值。拓扑映射就是在问:哪些通信最频繁、最细粒度、最在关键路径上,它们应该放到哪条链路上?
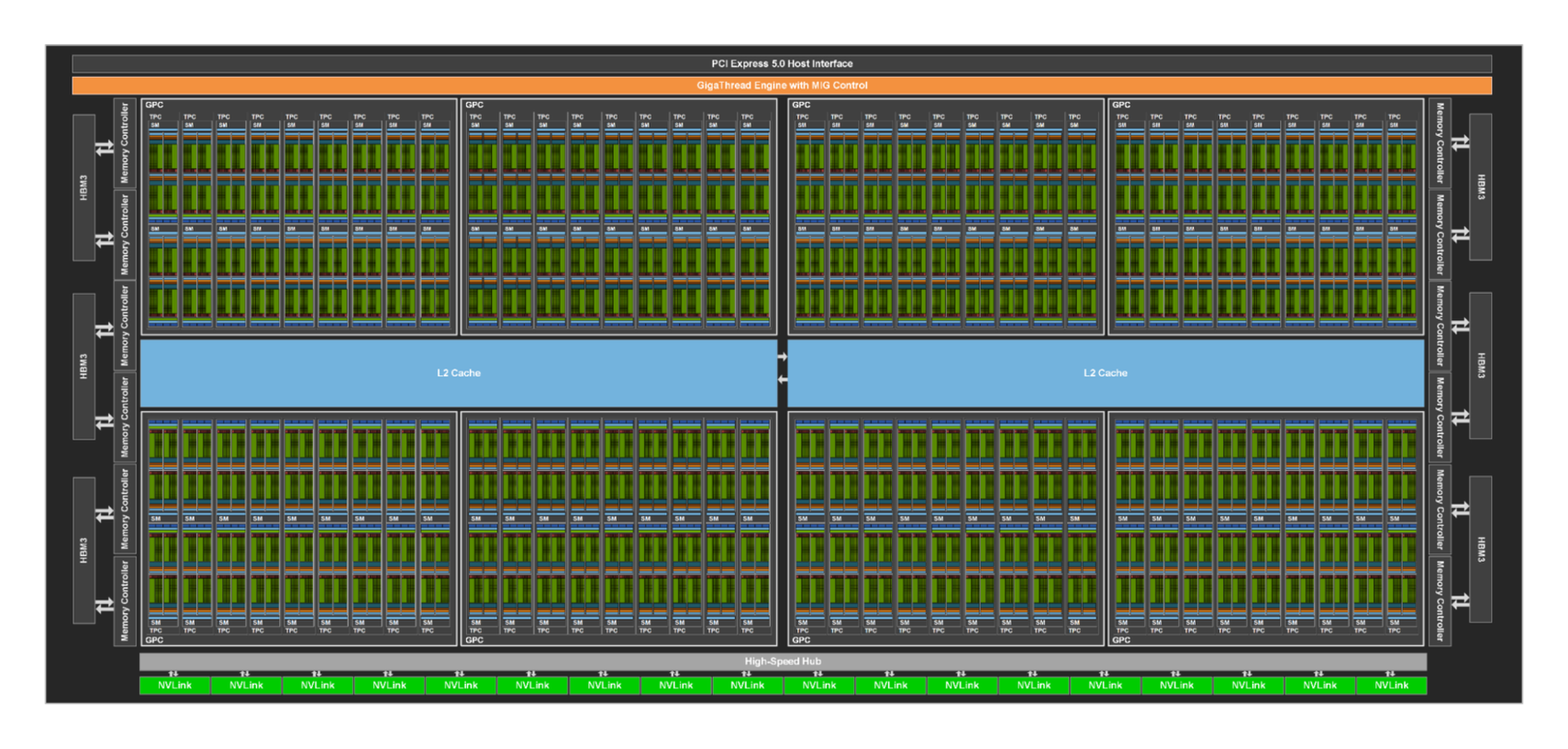
图源:NVIDIA Hopper Architecture In-Depth。原图表达 GH100 内部 SM、L2、HBM、NVLink、PCIe 和控制模块的组织。本站用它说明:GPU 不是孤立算力块,节点内高速互联、共享缓存、HBM 控制器和外部网络共同决定多 GPU 系统上限。
节点内和节点间不是一个量级
通常节点内链路更快、更稳定,节点间链路更慢、更容易拥塞。节点内可能是 NVLink、NVSwitch 或 PCIe;节点间可能是 InfiniBand、RoCE 或以太网络。不同集群的差别非常大,不能只按 GPU 型号推断。
| 链路层级 | 典型特点 | 更适合承载 |
|---|---|---|
| GPU 内部 HBM / L2 | 带宽最高,但只服务本 GPU | 单卡 kernel、局部 KV、激活。 |
| 节点内 NVLink / NVSwitch | 高带宽、低延迟、多 GPU 互联 | TP、频繁 all-reduce、跨卡推理分片。 |
| 节点内 PCIe | 普遍但带宽/延迟不如 NVLink 域 | 较低频通信、Host/GPU 数据交换。 |
| 节点间 IB / RoCE | 可扩展,但延迟和拥塞更敏感 | DP、PP 边界、跨节点 checkpoint 或粗粒度同步。 |
| 跨机架网络 | 拓扑层级更多,抖动更明显 | 更外层 DP、异步数据/评测/存储流量。 |
这就是为什么“8 卡一组”和“跨两个 4 卡节点”不能简单等价。即使总 GPU 数一样,通信图落到物理链路上以后,性能会完全不同。
TP 为什么通常贴节点内高速互联
张量并行把一个层内的矩阵或 attention head 分到多张 GPU 上。它的特点是通信频繁,而且位于 forward/backward 主路径。Megatron-LM 的 tensor model parallelism 里,线性层切分后需要在某些位置做 all-reduce 或 all-gather;这些同步如果跨慢链路,会直接拖慢每层。
因此 TP 通常优先放在节点内 NVLink/NVSwitch 域。一个常见映射是:
1 | 同一节点内: TP group |
这不是铁律,但背后的判断稳定:越频繁、越细粒度、越在关键路径上的通信,越应该放在更快、更低延迟的拓扑域里。
DP 为什么更容易向外扩展
数据并行让每个 rank 拥有模型副本或 ZeRO 分片,通信多发生在梯度、参数或 optimizer state 同步阶段。它的通信量也很大,但更容易 bucket、overlap,也更适合作为跨节点扩展的外层维度。
以 ring all-reduce 的粗略通信量看,每个 rank 需要发送和接收接近:
这里 是参与 rank 数。rank 越多,总网络压力越大;但如果通信能和 backward overlap,或者 ZeRO 把状态分片,实际感知开销会比裸公式更复杂。重点不是背这个系数,而是知道:DP 可以扩展,但网络和 overlap 能力会决定它能扩到哪里。
PP 的问题是带宽,也是 bubble
流水线并行把模型层分成多个 stage。它传的是 stage 边界激活和梯度,不像 TP 那样每层都全局通信,但会引入 pipeline bubble。拓扑映射时要同时看两件事:stage 之间激活是不是走慢链路,micro-batch 数是否足够隐藏 bubble。
如果 PP stage 跨节点,最好让相邻 stage 的通信路径稳定且带宽足够;如果某个 stage 本身算得慢,还会形成 straggler。拓扑映射和层切分需要一起看,不是先平均分层再祈祷通信没事。
MoE 的 all-to-all 最容易制造网络热点
MoE 把 token 路由到不同 expert。训练和推理时,token 可能要从一个 GPU 发送到另一个 GPU 上的 expert,再把结果发回来。这个 all-to-all 很容易制造三类问题:
| 问题 | 结果 |
|---|---|
| 热门 expert 集中在某个拓扑域外 | 大量 token 跨慢链路。 |
| 路由负载不均 | 某些 GPU 和链路过热,其他 GPU 空闲。 |
| expert placement 不看网络 | 模型层面负载均衡了,系统层面仍拥塞。 |
所以 MoE placement 不是单纯把 expert 平均放到 GPU 上。它同时是路由、负载均衡和拓扑映射问题。看 MoE benchmark 时,要问 token all-to-all 是否跨节点、是否跨机架、是否有 expert 热点,以及通信时间是否被 overlap 掩盖。
推理服务也会被拓扑影响
在线推理不像训练那样每步大规模反向通信,但拓扑仍然重要。TP 推理需要跨卡同步 logits 或中间张量;多 GPU KV cache 会涉及跨卡读写;MoE 推理有 expert dispatch;prefill/decode 分池时,不同池子的 GPU 和网络质量会影响 TTFT 和 P99。
服务里最容易误判的是只看平均 tokens/s。长 prompt 请求可能把 prefill 压到某组 GPU,短输出请求可能主要受 decode 和 KV 读取影响;如果调度器不知道拓扑,可能把延迟敏感请求放到跨慢链路的资源组上。
更稳的做法是把拓扑标签进入调度和实验记录:
1 | node_id, rack_id, gpu_id, nvlink_domain, nic_id, numa_domain, tp_group, pp_stage, dp_group |
这样当同一个模型在不同节点池表现不一致时,团队能先查物理映射,而不是误以为模型、kernel 或 batch 设置变了。
怎么排查拓扑问题
排查顺序不要从改并行配置开始,而是先画图:
- 画物理拓扑:GPU 到 GPU 是 NVLink、NVSwitch 还是 PCIe,GPU 到 NIC 是否跨 NUMA,节点间是否同机架。
- 跑分层通信基准:节点内、跨节点、跨机架分别测 all-reduce、all-to-all、point-to-point。
- 贴上进程组:把 TP、PP、DP、MoE expert group 映射到物理图上。
- 对照 trace:看通信时间、straggler、链路拥塞、CPU/NIC/GPU 等待。
- 做故障演练:降级节点、链路抖动、替换机型后重新验证映射。
如果单卡 kernel 没退化,但端到端变慢,优先查通信是不是跨了错误拓扑域、NCCL 是否选了次优路径、某个 NIC 是否过热、进程绑核是否跑到远端 NUMA、机架网络是否拥塞。
容易误读的地方
| 误解 | 更准确的说法 |
|---|---|
| GPU 数一样,性能就应该接近 | 拓扑不同,通信路径和拥塞完全不同。 |
| TP/PP/DP 配置只和模型大小有关 | 配置必须贴合物理链路,尤其是 TP 和 MoE。 |
| 理论带宽够就没问题 | effective bandwidth、延迟、拥塞、NCCL 路径和 overlap 都会改变结果。 |
| 拓扑只是部署细节 | 它会直接改变训练成本、推理 P99 和并行策略上限。 |
外部精读
- NVIDIA Hopper Architecture In-Depth:理解 H100/GH100 的 NVLink、HBM、L2 和 SM 组织。
- NVIDIA NCCL documentation:查 collective、拓扑检测、环境变量和调试方法。
- NCCL Tests:节点内/节点间 all-reduce、all-to-all 和 point-to-point 基准入口。
- Megatron-LM paper:理解 tensor model parallelism 为什么通信频繁。
- DeepSpeed ZeRO:理解数据并行状态分片和通信/显存权衡。
相关阅读与下一步
- 外部材料:NVIDIA CUDA C++ Programming Guide。
- 外部材料:Triton 文档。
- 外部材料:CUTLASS 文档。
- 站内下一步:算子与编译器专题。
- 站内下一步:CUDA 编程模型与内存层次。
- 站内下一步:Triton 编程模型与自动调优。
- Title: 算子与编译器:GPU 互联与拓扑映射
- Author: Charles
- Created at : 2025-08-11 09:00:00
- Updated at : 2025-08-11 09:00:00
- Link: https://charles2530.github.io/2025/08/11/ai-files-operators-gpu-interconnects-and-topology-mapping/
- License: This work is licensed under CC BY-NC-SA 4.0.