
算子与编译器:GEMM、Attention 与融合 Kernel
现代 AI kernel 的性能,大多围绕数据如何穿过 GEMM、Attention、Norm、Quantization 和 Memory Movement 这一串热点算子被决定。GEMM 是计算主引擎,Attention 是序列模型的结构性热点,融合 kernel 则试图减少中间读写和 launch 开销,让系统更接近硬件上限。
这页不重复数学推导,而是解释这些算子为什么重要、共享哪些优化模式,以及训练和推理系统为什么一再围绕它们重构。
GEMM 负责大量计算,Attention 负责序列信息读取,Fused Kernel 负责少搬数据。性能问题经常不是数学公式慢,而是中间张量写回 HBM、再读回来,浪费了大量带宽。
如果切菜、炒菜、装盘每一步都要把食材搬回仓库,再从仓库拿出来,厨房会很慢。Fused Kernel 像把连续工序放在同一个操作台上完成,减少来回搬运。
热点算子地图
| 算子 | 训练/推理中的位置 | 主要瓶颈 |
|---|---|---|
| GEMM / Batched GEMM | 线性层、QKV、FFN、MoE expert | Tensor Core 利用、tile、epilogue |
| Attention | prefill、decode、长上下文 | score/KV I/O、softmax、mask、KV cache |
| Norm / Softmax / Reduce | 每层高频小算子 | 带宽、归约、数值稳定 |
| Quant / Dequant | 低精度训练和推理 | scale 访问、类型转换、融合边界 |
| Permute / Gather / Scatter | MoE、KV、routing、packing | 不规则访存、负载不均 |
| Fused kernels | residual、activation、dequant、bias 等组合 | 减少 HBM 往返和 kernel launch |
这些算子表面不同,底层问题高度相似:shape 是否规则,数据是否连续,重用是否足够,中间张量是否被 materialize,launch 是否过多,数值稳定是否满足要求。
GEMM 是计算发动机
大模型训练和推理中的绝大多数 FLOPs,都能还原为 GEMM 或 batched GEMM:线性层、QKV 投影、FFN 上下投影、MoE expert 中的 dense matmul,以及量化后的混合精度 GEMM,最终都会落到矩阵乘和它的变体上。
标准 GEMM 更准确地写作 。深度学习里常见的 bias、activation、residual、scale、quant/dequant 等,通常属于 GEMM epilogue 或融合路径,不是 GEMM 定义本身。工程上真正要解决的是输入输出 layout 是否适合 Tensor Core, 如何 tile,数据如何从 HBM 搬到 shared memory 和 register,累加器如何保留在 register,epilogue 能否融合 bias、activation、dequant、quant,以及小矩阵、细碎 shape 和边界是否仍高效。
Tile 的作用是提升数据重用。tile 太小,重用不足、launch 和边界开销偏大;tile 太大,shared memory 和 register pressure 变高,occupancy 下降。GEMM 优化本质上是在 tile、并发、寄存器、片上存储和 epilogue 之间找平衡。
Attention 是 I/O 主战场
Attention 的核心公式是:
朴素实现的最大问题不是 FLOPs,而是把完整 score 矩阵 materialize 到 HBM,再读回来做 softmax 和后续乘法。这会产生巨大的中间张量和带宽压力。
FlashAttention 的核心思想是:不改变数学结果,重写数据流。它通过分块、在线 softmax 和片上累积,避免显式写出完整 score 矩阵。
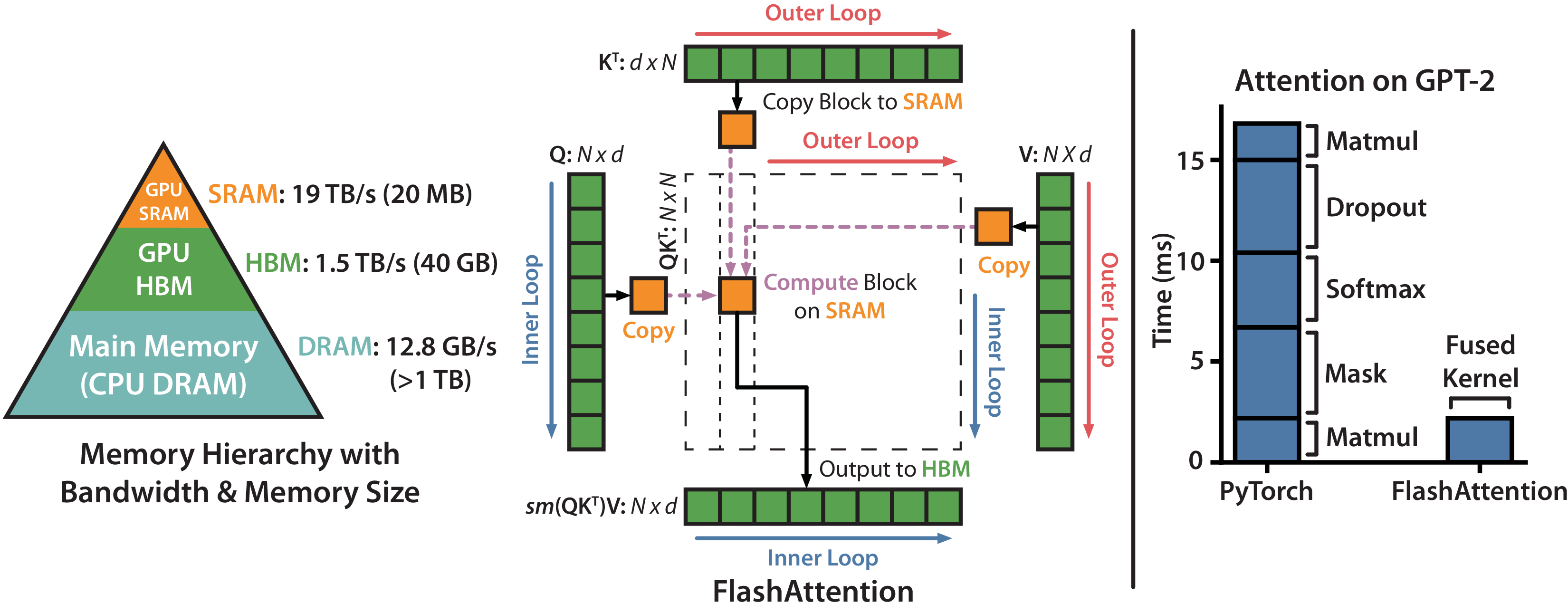
图源:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,Figure 1。原论文图意:左侧展示 FlashAttention 如何按块把 Q/K/V 放入 SRAM,避免 materialize 完整 attention matrix;右侧展示在 GPT-2 attention 上相对 PyTorch 实现的加速效果。
这张图容易被误读成“近似 attention”。实际上 FlashAttention 没有改 、softmax 和 的数学结果,它改的是计算顺序和内存层级:每次只处理一块 K/V 和一块 Q,用在线 softmax 保持数值正确,再把累积输出写回。它快的原因是减少 HBM 中间读写,而不是牺牲 attention 质量。
Attention 在不同 serving 阶段的画像也不同:
| 场景 | 主要特征 | 优化重点 |
|---|---|---|
| Prefill | 长输入、高并行、大矩阵 | 高吞吐、长序列 tile、FlashAttention |
| Decode | 每步少量新 token | KV cache 访问、launch、tail latency |
| Long-context decode | KV 很长但 query 很短 | Flash Decoding、跨 KV 分块并行 |
| Paged KV | KV cache 页式管理 | 页面索引、不连续访问、cache locality |
| MQA/GQA | K/V 共享减少 cache | 带宽下降,但 kernel layout 改变 |
这也是为什么 attention kernel 不能只按“公式一样”复用。prefill、decode、paged KV 和长上下文解码面对的是不同系统瓶颈。
高频小算子不能忽略
Softmax、LayerNorm、RMSNorm、Reduce、RoPE、activation 单次看起来小,但调用次数极高,且经常是带宽受限。它们的优化重点通常不是增加算力,而是减少读写和同步。
| 算子 | 关键点 |
|---|---|
| Softmax | 数值稳定、局部 max/sum、长行分块、避免中间写回 |
| LayerNorm / RMSNorm | 向量化 load/store、统计量计算、融合 residual/scale |
| Reduce | warp primitive、分层归约、原子写回或 block 汇总 |
| RoPE | 位置变换与 Q/K 读写融合 |
| Activation | 与 FFN epilogue 融合,避免额外读写 |
许多“模型层面的小改动”会在 kernel 层变成大量零散操作。如果这些操作没有融合,端到端性能会被 launch 和 HBM 往返吃掉。
融合 Kernel 的核心价值
融合 kernel 的目标是把多个逻辑操作放进一条数据路径里,减少中间张量 materialization。
常见模式包括 GEMM 后融合 bias、activation、residual、scale、quant/dequant 的 epilogue fusion,Norm 与 residual、dropout、scale 合并的 norm fusion,QK、mask、softmax、PV 走同一个分块数据流的 attention fusion,permute、padding、expert GEMM、unpermute 减少搬运的 MoE fusion,以及尽量不把 dequant + matmul + requant 拆成多个 kernel 的 quant fusion。
融合也不是越多越好。过度融合会带来 register pressure 过高、编译时间和 autotuning 空间爆炸、shape 专用性太强导致复用差、数值调试困难,以及和框架 graph rewrite 冲突等问题。
判断是否值得融合,核心看它是否减少了昂贵的 HBM 往返或 launch,而不是看“逻辑上能不能写到一起”。
Shape、Dtype 与 Layout
同一个算子在不同 shape、dtype 和 layout 下可能完全是不同问题。
| 维度 | 为什么重要 |
|---|---|
| Shape | 小 batch、长尾 shape、非对齐维度会降低 tile 利用率 |
| Dtype | FP16/BF16/FP8/INT8 决定 Tensor Core 路径和累计精度 |
| Layout | row/col major、packed layout、swizzle 影响 coalescing 和 bank conflict |
| Sparsity | MoE 和稀疏路由带来负载不均与不规则访问 |
| Dynamic batching | serving 中 shape 经常变化,专用 kernel 未必总能命中 |
训练阶段常见的是大 batch、规则 shape、高吞吐;推理 decode 常见的是小 query、长 KV、动态 batch、尾延迟敏感。因此训练 kernel 和 serving kernel 的设计目标经常不同。
选型与实现路线
实际工程中常见路线可以分成四层:框架默认算子最快接入,适合作为 baseline;cuBLAS、cuDNN、CUTLASS、FlashAttention 等库级优化适合稳定热点;Triton / DSL kernel 适合快速写专用 shape、融合和 autotuning;手写 CUDA / PTX / SASS 调优则只适合极端热点或库无法覆盖的路径。
选型时建议先问热点是否足够稳定、值得写专用 kernel,shape 是否集中并能通过 bucket 提高命中,dtype 和 layout 是否已经定型,融合后是否仍能保持数值可验证,以及框架 graph、runtime 和调度是否能稳定调用它。
不要在还没 profile 的地方写自定义 kernel。自定义 kernel 的维护成本很高,只有在热点明确、收益可测、回归可控时才值得进入主线。
Profiling 清单
排查 GEMM、Attention 和融合 kernel 时,建议先用 trace 定位热点,而不是凭直觉;再区分瓶颈来自 Tensor Core 利用不足、HBM 带宽、L2、同步、launch 还是调度;随后看 shape 分布和长尾 bucket,检查是否有本可避免的中间张量 materialize 和额外读写,确认低精度是否真的走到硬件加速路径;最后做数值回归和端到端对比,因为单 kernel 变快不等于训练或推理真的变快。
GEMM、Attention 和融合 kernel 的共同原则是:不只优化公式,更要优化数据流。现代 AI 系统的很多性能跃迁,来自把原本在 HBM 中反复读写的中间状态,改成在片上存储和寄存器里连续完成。
- Title: 算子与编译器:GEMM、Attention 与融合 Kernel
- Author: Charles
- Created at : 2025-09-02 09:00:00
- Updated at : 2025-09-02 09:00:00
- Link: https://charles2530.github.io/2025/09/02/ai-files-operators-gemm-attention-and-fused-kernels/
- License: This work is licensed under CC BY-NC-SA 4.0.