
算子与编译器:Triton 编程模型与自动调优:先画 tile,再谈速度
Triton 不是“Python 版 CUDA”。它真正提供的是一种适合神经网络张量算子的中间层:你不用手写每个 thread 的同步和访存细节,但仍然要明确一个 program instance 负责哪块输出、怎样计算地址、怎样处理边界、怎样累加、怎样选择 tile,以及编译和 autotune 什么时候发生。
读 Triton kernel 时,最重要的问题不是“这段 Python 代码像不像普通循环”,而是:program_id 如何映射到输出 tile,tl.arange 如何生成 block 内索引,tl.load/tl.store 访问了哪张地址矩阵,tl.dot 在什么 dtype 上累加,@triton.autotune 又在什么 shape bucket 上选择配置。
先判断它是不是 Triton 问题
一个 AI 系统从模型代码到 GPU 执行,大致可以分成四层:
1 | PyTorch / JAX model |
Triton 通常站在 generated kernel / custom kernel 这一层。它适合表达规则张量块上的数据流:一个输出 tile 对应哪些输入 tile,中间结果能否留在 register 或 SRAM 近似路径里,多个 elementwise、reduction、matmul epilogue 能否合成一次读写。
写 Triton 之前,先问四个问题:
| 问题 | 为什么 |
|---|---|
| 热点是否已经由 profile 证明 | 没有热点,kernel 再漂亮也只是局部优化。 |
| 输出能否切成规则 block | 每个 program instance 必须知道自己负责哪片输出。 |
| 输入地址能否由 block id 和 stride 算出来 | Triton 擅长规则或半规则 gather,不擅长完全散乱控制流。 |
| 高频 shape 是否集中 | shape 太散会让 JIT、autotune、cache miss 和 fallback 吃掉收益。 |
如果现成 cuBLAS/cuDNN/FlashAttention/CUTLASS 路径已经覆盖热点,或者需要复杂跨 block 同步、跨 GPU 通信重叠、最新硬件极限特化,Triton 未必是第一选择。它最适合“库不覆盖、手写 CUDA 太重、数据流可 block 化、收益能端到端验证”的位置。
program instance 不是 thread
CUDA 初学者通常从 thread、block、grid 开始。Triton 更适合从 program instance 开始:一个 program instance 处理一块向量、一行 softmax、一个矩阵乘输出 tile,或一组 token 的重排。
最小例子是向量加法:
1 |
|
pid 是当前 program instance 在一维 grid 里的编号。tl.arange(0, BLOCK) 不是 Python 循环,而是生成 block 内的一组向量索引。offsets 把“第几块”变成“全局张量里的哪些元素”。mask 处理最后一块不足 BLOCK 的边界,避免越界 load/store。
地址可以写成:
表示 BLOCK, 表示 block 内第几个 lane 对应的元素位置。Triton 编译器会把这些向量表达降到底层并行执行;kernel 作者要保证 offsets、mask、dtype 和写回路径是对的。
stride 才是 layout 的真相
真实模型里的张量经常不是简单 contiguous 一维数组。二维矩阵里,位置 的地址通常写成:
和 是 stride。把 stride 显式传入 kernel,是为了让同一段 Triton 代码处理不同 layout,而不是偷偷假设输入连续。
处理一个 输出 tile 时,常见写法是:
1 | offs_m = pid_m * BLOCK_M + tl.arange(0, BLOCK_M) |
offs_m[:, None] 和 offs_n[None, :] 通过广播生成一张二维地址矩阵。读 Triton kernel 时,先看这张地址矩阵是否对应了正确 layout:行主序、列主序、batch stride、head stride、group stride、packed layout 都会在这里显形。
很多 bug 不是公式错,而是 stride、mask 或边界错。它们只在某些 batch size、head 数、hidden size、非 contiguous 输入或最后一个 tile 上出现,所以测试也必须覆盖这些桶。
matmul 是 tile 设计的主线
矩阵乘是 Triton 最好的入门主线。设:
一个 Triton program instance 通常负责 的一个 tile。它在 维上分块前进:每次读一块 和一块 ,用 tl.dot 累加到 accumulator,最后写回 的 tile。
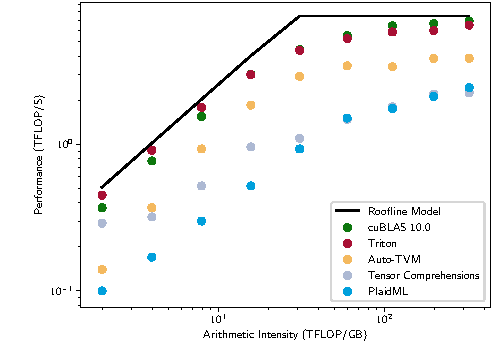
图源:Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations,Figure 1。本站复用已有论文图,未使用 image2 生成新图。原图比较 Triton、cuBLAS、AutoTVM、Tensor Comprehensions 和 PlaidML 在矩阵乘 roofline 图上的位置;本站用它说明 Triton 的价值不是替代所有库,而是在高层框架和手写 CUDA 之间提供 tile 级表达能力。
matmul kernel 可以按这个骨架读:
1 | pid -> 映射到 (pid_m, pid_n) |
这里有三张性能账:
| 账 | 为什么影响性能 |
|---|---|
| tile 复用 | 和 的 tile 是否被足够多输出元素复用。 |
| 边界浪费 | 不是 block 整数倍时,mask 会带来无效 lane。 |
| epilogue 融合 | bias、activation、dequant、requant 能否在 accumulator 写回前完成。 |
BLOCK_M、BLOCK_N、BLOCK_K 太小,数据复用不足;太大,register pressure、SRAM 使用和 occupancy 压力会上升。高性能 kernel 的核心,是把 tile、dtype、layout、accumulator、epilogue 和目标 GPU 放在一起调。
group ordering 是为了 L2 locality
官方 matmul 教程会把 program id 映射到 ,有时还会用 group ordering。它的目的不是让代码更绕,而是改善 L2 cache locality。
如果 grid 简单按行列顺序遍历,邻近 program 可能反复加载不同的 或 tile,缓存复用不稳定。group ordering 会让一组 program 先覆盖相邻的 tile 和 tile,使某些 或 block 更可能在 L2 中被复用。
读这类代码时可以问:连续 program 共享哪一边的数据,是 复用更多还是 复用更多,这是否符合真实 shape。这个问题比 pid 公式看起来是否优雅更重要。
autotune 搜的是 meta-parameters
Triton 的 @triton.autotune 会在一组 triton.Config 里选择配置。常见候选包括:
| 参数 | 影响 |
|---|---|
BLOCK_M/N/K |
tile 大小、复用、边界浪费和 accumulator 大小。 |
num_warps |
一个 program instance 内的 warp 数,影响并行度和资源占用。 |
num_stages |
pipeline 深度,影响预取、寄存器和 shared memory 压力。 |
| group size / swizzle | program 遍历顺序和 L2 locality。 |
| accumulator dtype | 数值稳定、吞吐和写回转换。 |
key 决定什么时候重新选择配置。例如 key 里包含 M,N,K,就表示不同矩阵形状可能用不同配置;如果 key 只包含部分维度,低频变化可能复用同一配置。
autotune 有两个边界。第一,它只能在候选配置里选,不会替你发明更好的数据流。第二,它搜索的目标通常是某个 microbenchmark 的热态时间,未必等于训练 step time、serving TTFT 或线上 P99。
更稳的流程是:
1 | profile 证明热点 |
候选空间太大,autotune 本身会变成成本;候选空间太窄,它只能在差配置里选一个不太差的。真实项目里,shape bucket 往往比“再多搜几个 BLOCK_SIZE”更重要。
JIT、cache 和 fallback 是线上问题
手写 Triton kernel、PyTorch Inductor 生成的 Triton kernel、高层库内部封装的 Triton kernel,都会面对 JIT 编译和缓存。离线 benchmark 往往只测热态 kernel latency,真实服务还要看:
| 指标 | 为什么要单独记录 |
|---|---|
| compile time | 新 shape 首次命中时可能拉高 TTFT 或 P99。 |
| autotune time | 搜索候选配置可能比一次 kernel 执行贵很多。 |
| compile cache hit rate | 动态 shape 太散会反复 miss。 |
| fallback frequency | 不支持某些 shape、dtype、layout 时是否退回慢路径。 |
| graph capture stability | torch.compile 是否稳定捕获到同一条 kernel 路径。 |
上线时常见做法是:离线预热高频 shape,限制在线 autotune,把候选配置固化到少数 bucket,低频 shape 走保守路径,并把 compile、autotune、fallback 时间计入端到端指标。否则“kernel 热态快 20%”可能变成“线上 P99 更差”。
验证一个 Triton kernel
一个 Triton kernel 不能只用“比 PyTorch 快”验收。更完整的验证至少包括五类。
| 验证 | 看什么 |
|---|---|
| 正确性 | contiguous / non-contiguous、边界 tile、不同 dtype、不同 batch/head/hidden size。 |
| 数值 | accumulator dtype、rounding、溢出、NaN/Inf、与 reference 的误差桶。 |
| 性能 | cold start、warmup 后 latency、带宽、Tensor Core 利用、shape bucket 命中率。 |
| 端到端 | 训练 step time、serving TTFT/TPOT/P99、CPU launch、graph capture、fallback。 |
| 可维护 | 配置数量、硬件兼容、版本升级回归、错误日志和保守回退路径。 |
读一个已有 Triton kernel 时,按下面顺序拆会更稳:先找 program_id 到输出 tile 的映射,再看 offsets 和 stride 是否正确,然后看 mask 边界,再看 load/store 的 dtype 和 accumulator,接着看 tl.dot 或 reduction 的循环,最后看 autotune key、候选配置和调用侧 shape bucket。
如果只记住一句话:Triton 的核心不是把 CUDA 写成 Python,而是把张量 kernel 的 block 数据流暴露出来,让程序员控制 tile 和地址,让编译器生成底层并行代码;自动调优只能优化候选配置,不能替代数据流设计和端到端验证。
外部精读
- Triton 官方 Vector Addition tutorial:最小
program_id、tl.arange、mask、load/store 心智模型。 - Triton 官方 Matrix Multiplication tutorial:理解
BLOCK_M/N/K、tl.dot、group ordering 和 autotune。 - Triton
autotuneAPI:查configs、key、reset_to_zero、restore_value等参数语义。 - Triton paper:理解 Triton 作为 tiled neural network computation DSL 的原始定位。
- Triton GitHub repository:查看项目、示例和当前实现生态。
- PyTorch
torch.compiledocumentation:理解 Inductor、编译缓存、graph capture 和生成 kernel 的上层路径。 - CUDA C++ Best Practices Guide:补 coalescing、occupancy、profiling、memory throughput 等 GPU 优化背景。
相关阅读与下一步
- 外部材料:NVIDIA CUDA C++ Programming Guide。
- 外部材料:Triton 文档。
- 外部材料:CUTLASS 文档。
- 站内下一步:算子与编译器专题。
- 站内下一步:CUDA 编程模型与内存层次。
- 站内下一步:Triton 编程模型与自动调优。
- Title: 算子与编译器:Triton 编程模型与自动调优:先画 tile,再谈速度
- Author: Charles
- Created at : 2025-09-04 09:00:00
- Updated at : 2025-09-04 09:00:00
- Link: https://charles2530.github.io/2025/09/04/ai-files-operators-triton-programming-model-and-autotuning/
- License: This work is licensed under CC BY-NC-SA 4.0.