
论文专题讲解:Depth Anything:无标注图像怎样变成单目深度基础模型
论文题名: Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data。
作者: Lihe Yang、Bingyi Kang、Zilong Huang、Xiaogang Xu、Jiashi Feng、Hengshuang Zhao。
机构: 未在公开元数据中稳定解析;以 arXiv/PDF 或官方页 affiliation block 为准。
时间 / 主题: 2024-01;具身智能。
arXiv / 官方报告: arXiv:2401.10891;官方材料:depth-anything.github.io/。
GitHub / 项目: GitHub:github.com/LiheYoung/Depth-Anything;项目页:depth-anything.github.io/。
元数据来源与核验口径: 来源:arXiv;GitHub API / repo;官方 / 项目材料;Checked Date:2026-06-15;Repro Status:Paper / official materials reviewed, independent reproduction not claimed。
Depth Anything 的核心贡献很朴素,也很容易被讲浅:它没有靠复杂新结构取胜,而是把单目深度估计的瓶颈重新放回数据覆盖上。论文问的是:如果真实深度标签很贵,能不能用大量无标注图像把深度模型训练成更强的视觉基础模型?
答案不是“把 pseudo label 加进去就行”。普通 self-training 很可能只让 student 模仿 teacher 已经会的东西。Depth Anything 真正关键的是两步:让无标注图像经过强扰动,迫使 student 学到更鲁棒的视觉知识;再用 DINOv2 feature alignment 保住语义表征,避免深度训练把通用视觉能力洗掉。
一句话核心
Depth Anything 训练的是一个相对深度函数:
其中 是单张 RGB 图像, 是每个像素的相对深度。这里的“相对”很重要:基础模型默认不保证真实米制尺度;它输出的是跨场景更稳的深度排序和几何形状。后续如果需要 metric depth,需要在 NYUv2、KITTI 这类带尺度标签的数据上再 fine-tune。

图源:Depth Anything,Figure 1。原图表达模型在未见场景中的泛化,包括低光、复杂多人、雾天城市和远距离建筑。本站读法:先看场景覆盖,而不是只看 benchmark 平均分。
为什么单目深度特别吃数据覆盖
单目深度没有双目几何的视差约束,也没有激光雷达的真实距离观测。模型必须从纹理、物体大小、透视、遮挡、地平线、语义类别等线索推断深度。这些线索高度依赖数据分布:室内、街景、森林、透明物体、低光、远景建筑都会给模型不同的捷径。
这就是为什么 Depth Anything 没有把精力放在新 decoder 上。论文的判断是:如果训练数据只覆盖有限场景,再漂亮的结构也会学到有限先验;反过来,大规模、多源、便宜的无标注图像能显著扩展视觉分布。
论文的数据可以分成两层:
- labeled images:约 1.5M,提供高质量相对深度监督。
- unlabeled images:约 62M,来自道路、地标、通用物体、场景、分割数据和互联网视觉分布。
无标注数据提供广度,有标注数据提供深度任务锚点。Depth Anything 的方法难点,就是让这两类数据在一个训练目标里互相补充,而不是互相污染。
Teacher-student:无标注图像先要变成可学习目标
对无标注图像 ,teacher model 先生成 pseudo depth:
其中 是 teacher, 是 pseudo label。student 不是简单在原图上拟合它,而是在强扰动后的图像 上预测深度:
这里 表示强扰动,包括颜色变化、模糊、CutMix 等; 是 student; 是相对深度损失。这个式子的关键是 teacher 看相对干净的图,student 看更难的图。student 要想拟合同一个深度目标,就必须学会忽略扰动,抓住更稳定的形状和语义线索。
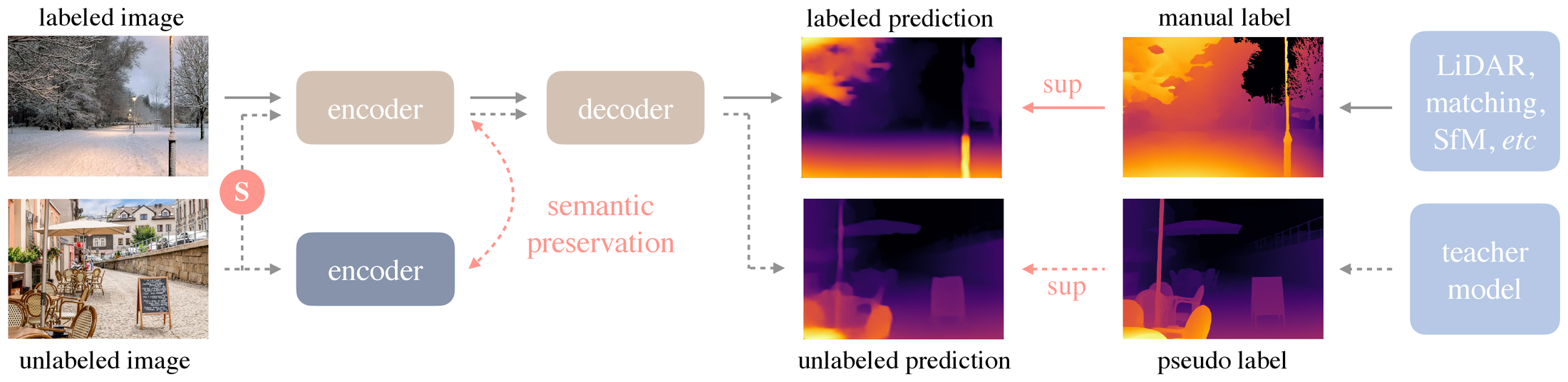
图源:Depth Anything,Figure 2。原图表达 labeled image 和 unlabeled image 两条训练流:无标注图像经 teacher 产生 pseudo label,student 在强扰动图像上学习,并通过 frozen DINOv2 做 semantic preservation。本站读法:把 strong perturbation 和 feature alignment 分开看,二者解决的是不同问题。
为什么普通 self-training 不够
如果 student 和 teacher 架构相近、初始化相近,直接用 pseudo label 训练很容易变成“复读 teacher”。student 学到的是 teacher 的输出分布,而不是无标注图像里额外的视觉知识。论文消融显示,单纯加入 pseudo-labeled images 并不稳定,只有加上 strong perturbations 后,才明显提升 zero-shot 深度泛化。
可以用一个直觉理解:teacher 给的是“这张图大概哪里远哪里近”;强扰动让 student 面对颜色、纹理和局部拼接被破坏的图像。如果 student 还能恢复同样深度,就说明它不能只依赖浅层外观,而要学习物体边界、空间结构和语义一致性。
这也是 Depth Anything 相比普通半监督深度更强的地方。它不是把 pseudo label 当廉价真值,而是把无标注图像变成一种视觉鲁棒性训练。
相对深度损失:尺度和偏移不能硬对齐
不同数据集、不同相机、不同场景的深度尺度不一致。单目相对深度训练通常使用 scale-and-shift invariant 的对齐方式:先把预测和标签在尺度、偏移上对齐,再比较形状误差。
可以把对齐写成:
其中 是第 个像素的预测深度, 是标签或 pseudo label, 是最优尺度和偏移。这个公式说明模型训练时更关注深度形状和排序,而不是绝对米制距离;这也是为什么 Depth Anything 基础模型适合做 relative depth,metric depth 需要额外 fine-tuning。
DINOv2 feature alignment:保住语义,不让深度任务变窄
Depth Anything 使用 DINOv2 initialization。DINOv2 本身有很强的语义和形状表征,如果只用深度目标训练,模型可能逐渐丢失这些通用视觉能力。论文因此加入 feature alignment:让 student depth encoder 的中间特征不要偏离 frozen DINOv2 encoder 太远。
简化目标可以写成:
其中 表示 student depth model 在像素或 patch 的特征, 表示 frozen DINOv2 的特征, 是 tolerance margin, 是参与计算的位置集合。这里的 margin 很关键:DINOv2 会把同一物体不同部位拉近,但深度模型必须区分物体内部的前后距离;所以论文不强迫所有特征完全一致,而是只在相似度太低时施加约束。
这一步把 Depth Anything 从“深度专用模型”推向“可迁移视觉 backbone”。论文后续在 metric depth、semantic segmentation 和 ControlNet 条件生成上都展示了这个价值。
实验应该怎样读
Depth Anything 的 zero-shot 结果要按分布读,而不是只看平均排名。论文在 KITTI、NYUv2、Sintel、DDAD、ETH3D、DIODE 等未见数据集上评估,覆盖室内、室外、合成、自动驾驶和真实 3D 数据。这个评测组合能检查模型是否只记住某种相机或场景。

图源:Depth Anything,Figure 3。原图表达模型在多个 unseen datasets 上的定性结果。本站读法:观察边界、远景、透明/细长结构和室内外切换,而不是只看颜色图是否漂亮。
消融结果可以拆成三个判断。
第一,labeled data 是深度任务锚点,没有它,无标注图像很难直接变成可靠深度监督。第二,pseudo label 只有在 strong perturbation 下才更有价值,因为它把无标注数据变成鲁棒性任务。第三,feature alignment 主要应该加在 unlabeled data 上;对 labeled data 强加语义对齐,可能干扰高质量深度标签本身。
和具身智能有什么关系
机器人需要深度,但真实系统不总能依赖完美 RGB-D。深度相机可能受光照、透明物体、反射、距离范围和标定影响;单目深度虽然没有真实尺度,但覆盖广、成本低,能为感知和策略提供空间先验。
Depth Anything 对具身系统的意义主要有三层:
- 作为 relative depth 估计器,帮助 VLA 或 diffusion policy 理解前后关系和可达空间。
- 作为 metric depth fine-tuning 的强初始化,在少量米制标签上适配具体相机。
- 作为视觉 backbone,把几何和语义表征交给后续策略、重建或生成模型。

图源:Depth Anything,Figure 4。原图表达 Depth Anything 预测的深度可以作为 ControlNet 条件,帮助生成更稳定的图像。本站读法:这说明更好的深度不仅服务机器人感知,也能成为生成模型的结构控制信号。
边界与误解
第一,Depth Anything 的基础输出不是绝对米制深度。把颜色图直接当距离用,会误导规划和控制。需要真实尺度时,应做 metric fine-tuning 或结合相机标定、双目、深度传感器。
第二,它不解决所有几何问题。单目深度看不到遮挡后的物体,也不能从一张图恢复完整 3D 拓扑。对抓取、避障和接触控制来说,深度只是输入之一。
第三,pseudo label 会继承 teacher 偏差。大规模无标注数据能扩展分布,但不自动保证透明物体、镜面、极端光照和罕见相机视角都正确。Depth Anything 的贡献在于显著提升泛化,不是消灭单目深度的不适定性。
证据链快照
| 论文主张 | 主要证据 | 读数边界 |
|---|---|---|
| 大规模无标注图像能提升单目深度泛化 | zero-shot benchmark、Figure 3 定性结果、unlabeled data 消融 | 不能推出所有无标注图像都有价值;teacher 偏差和场景覆盖仍关键 |
| strong perturbation 是 pseudo-label 学习的关键 | self-training / perturbation ablation | 说明鲁棒训练有效,不代表 pseudo label 本身无噪声 |
| DINOv2 feature alignment 保留语义表征 | feature alignment 相关消融和下游表现 | 保留语义不等于获得米制尺度或完整 3D |
| 深度可作为生成/感知结构条件 | depth-conditioned synthesis 图和项目 demo | 结构条件有效不等于机器人闭环控制有效 |
阅读结论
Depth Anything 的主要内容要按数据配方读:labeled depth data 提供几何锚点,teacher pseudo labels 把大规模无标注图像转成可训练目标,strong perturbation 让 student 不只是复读 teacher,DINOv2 feature alignment 则避免深度训练损坏通用语义表征。实验上,zero-shot benchmark、定性深度图和消融共同支撑“无标注数据释放泛化”的主张。
它适合被复用为单目相对深度基础模型、metric depth fine-tuning 初始化或机器人视觉的空间先验;不能直接当米制距离、完整 3D 重建或闭环控制证据。下一步如果接到具身系统,需要补相机标定、尺度恢复、遮挡/透明物体失败分析,以及策略使用深度后是否提升任务成功率的闭环评测。
外部精读
- Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data:论文原文,建议重点读 data engine、training strategy 和 ablation。
- Depth Anything project page:项目页适合直观看不同场景的 zero-shot 深度效果。
- LiheYoung/Depth-Anything:代码与模型发布页面。
- DINOv2: Learning Robust Visual Features without Supervision:理解 feature alignment 为什么能保住语义表征。
相关阅读与下一步
- 外部材料:论文标题 arXiv 检索。
- 外部材料:Semantic Scholar 标题检索。
- 外部材料:Papers with Code 检索。
- 站内下一步:论文精读专题。
- 站内下一步:论文专题写作规范。
- 站内下一步:外部精读来源台账。
- Title: 论文专题讲解:Depth Anything:无标注图像怎样变成单目深度基础模型
- Author: Charles
- Created at : 2025-09-23 09:00:00
- Updated at : 2025-09-23 09:00:00
- Link: https://charles2530.github.io/2025/09/23/ai-files-paper-deep-dives-embodied-ai-depth-anything/
- License: This work is licensed under CC BY-NC-SA 4.0.