
论文专题讲解:GR-2:Web 视频知识怎样迁移到机器人操作
论文题名: GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation。
作者: Chi-Lam Cheang、Guangzeng Chen、Ya Jing、Tao Kong、Hang Li、Yifeng Li、Yuxiao Liu、Hongtao Wu、Jiafeng Xu、Yichu Yang 等(共 12 人)。
机构: ByteDance Research。
时间 / 主题: 2024-10;具身智能。
arXiv / 官方报告: arXiv:2410.06158;官方材料:gr2-manipulation.github.io/。
GitHub / 项目: GitHub:github.com/mees/calvin;项目页:gr2-manipulation.github.io/。
元数据来源与核验口径: 来源:arXiv;GitHub API / repo;官方 / 项目材料;Checked Date:2026-06-15;Repro Status:Paper / official materials reviewed, independent reproduction not claimed。
GR-2 这篇论文的核心问题是:机器人数据很贵,但公开视频里有大量人和物体互动的动态知识,这些视频能不能帮助机器人学操作?
它的答案不是把公开视频直接当机器人 demonstration。公开视频没有机器人动作标签,也没有末端位姿,更没有夹爪状态。GR-2 的路线是:先用大规模视频预训练学“接下来会发生什么”,再用机器人轨迹微调,让模型同时预测未来视频和动作轨迹。视频预训练学世界动态,机器人微调把动态知识接到可执行动作上。
可以想一个“拧开瓶盖再放下”的任务。公开视频里有大量人手旋转瓶盖、瓶身保持、盖子分离的视觉变化;这些视频没有机器人夹爪的 标签,但它们告诉模型“旋转前后物体状态会怎样变”。机器人数据再告诉模型:如果要让真实机械臂制造这种变化,末端应该怎样靠近、夹住、旋转和松开。GR-2 的迁移不在于把人手动作直接复制给机器人,而在于把公开视频里的未来状态变化,重新绑定到机器人动作轨迹上。
一句话核心
GR-2 学的是一个 video-language-action 序列模型:
其中 是当前和历史视频 token, 是机器人状态, 是语言指令, 是未来视频, 是未来动作轨迹。这里最重要的是双输出:未来视频让模型保持动态想象,动作轨迹让它能落到机器人控制。
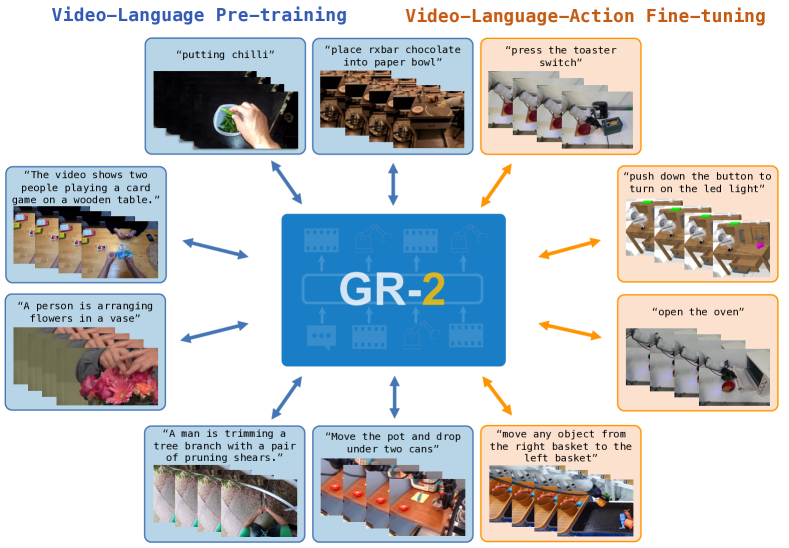
图源:GR-2,Figure 1。原图表达 GR-2 先做 web-scale video generative pre-training,再在机器人数据上同时学习视频生成和动作预测。本站读法:不要把未来视频看成可视化附件,它是把公开视频知识迁移到机器人操作的桥。
为什么公开视频能帮机器人
机器人操作有两类知识。第一类是语义知识:杯子、抽屉、瓶盖、按钮是什么。第二类是动态知识:物体被推会怎样移动,瓶盖旋开前后外观怎样变化,倒水时容器和液体关系怎样变化。公开视频虽然没有机器人动作标签,但包含大量动态知识。
VLA 如果只在机器人数据上训练,很容易受限于任务数量、物体数量和环境数量。GR-2 先在约 38M video clips、超过 50B tokens 的公开视频数据上做 generative pre-training,让模型学会预测未来视频 token。这个阶段没有机器人动作,但它建立了“人类操作和物体变化”的视觉动态先验。
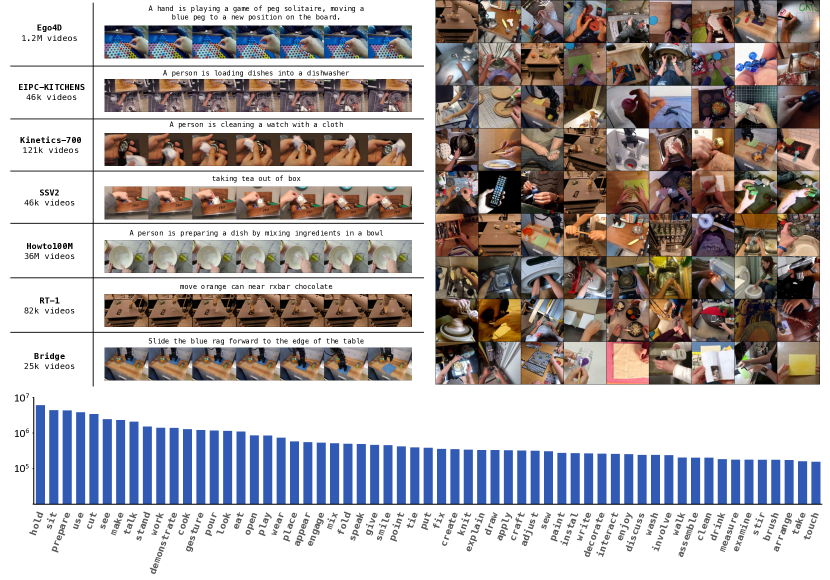
图源:GR-2,Figure 2。原图表达大规模视频预训练数据和从 web video 到机器人数据的训练路线。本站读法:先看预训练学的是 future video prediction,再看机器人微调怎样把这个能力接到 action prediction。
视频 token:为什么不用直接预测像素
GR-2 使用 VQGAN 把图像压成离散 visual tokens。这样 GPT-style transformer 可以像处理文本 token 一样处理视频 token。未来视频预测目标可以写成:
其中 是第 帧的离散视觉 token, 是历史视觉 token, 是语言条件。这个目标让模型学习“给定当前画面和指令,未来画面 token 应该如何变化”。它不需要动作标签,所以可以利用公开视频。
这一步的价值不是生成好看的视频,而是让 transformer 内部表征包含动作后果、物体状态变化和场景动态。机器人微调阶段会把这些表征重新绑定到机器人动作上。
机器人微调:未来视频和动作一起学
机器人数据有多视角图像、语言指令、状态序列和动作轨迹。GR-2 在这个阶段同时预测未来视频和动作:
其中 继续约束未来画面, 约束未来动作轨迹, 控制动作损失权重。这里要读懂的是:视频目标没有在微调时被丢掉。模型一边保持对未来状态的想象,一边学习怎样输出控制轨迹。
动作不是单步命令,而是一段 Cartesian action trajectory。可以写成:
其中 表示末端位移, 表示姿态变化, 表示夹爪状态。轨迹输出比单步动作更平滑,也更容易交给低层控制器执行。
为什么 future video 不是装饰
很多论文会把中间可视化当成解释工具,但 GR-2 的 future video 是训练目标的一部分。它至少提供三种作用。
第一,它让模型在动作前想象任务进展。比如“把杯子放进篮子”不是一个瞬时动作,而是一段物体位置、夹爪状态和遮挡关系变化。第二,它让 web video pretraining 的知识在 robot fine-tuning 中继续被使用,而不是被动作回归目标覆盖。第三,它提供了一个额外正则:如果动作预测和未来视频不一致,模型需要在训练中调整内部表示。

图源:GR-2,Figure 4。原图表达 105 个桌面任务和 8 类操作技能。本站读法:这张图不是任务炫耀,而是说明机器人微调阶段覆盖了多个操作原语,方便把公开视频动态迁移到真实动作。
数据增强:让机器人数据更像开放世界
GR-2 还使用物体替换和背景替换增强。论文用分割和生成模型把新对象或新背景插入机器人轨迹视频,尽量保持机器人运动和任务结构。这一步的作用是补机器人数据的视觉多样性。
这和 web video pretraining 的关系很清楚:预训练给大范围动态先验,数据增强让机器人微调不要只记住固定桌面、固定物体和固定背景。两者一起降低了 policy 对实验室视觉分布的依赖。
执行:VLA 输出还要经过控制器
GR-2 输出的不是电机级命令。真实机器人执行时,动作轨迹会被低层控制器处理,并考虑碰撞、可操作性、关节限制和安全约束。这个细节很重要,因为很多 VLA 文章容易让人误以为 transformer 直接控制电机。
更准确的系统图是:GR-2 预测一段末端轨迹,低层控制器把轨迹投影到机器人可执行动作,真实传感器再反馈下一步观测。高层模型负责语义和动态,低层控制器负责物理执行。
实验应该怎样读
GR-2 的真实机器人评测可以分成三组。
第一组是多任务桌面操作。论文报告 GR-2 在 100 多个任务上有很高平均成功率,并在 simple、distractor、unseen backgrounds、unseen environments 和 unseen manipulation 等设置下比较。读这组结果时要看难度梯度:背景和环境泛化主要考察视觉鲁棒性,unseen manipulation 才更接近新技能组合。
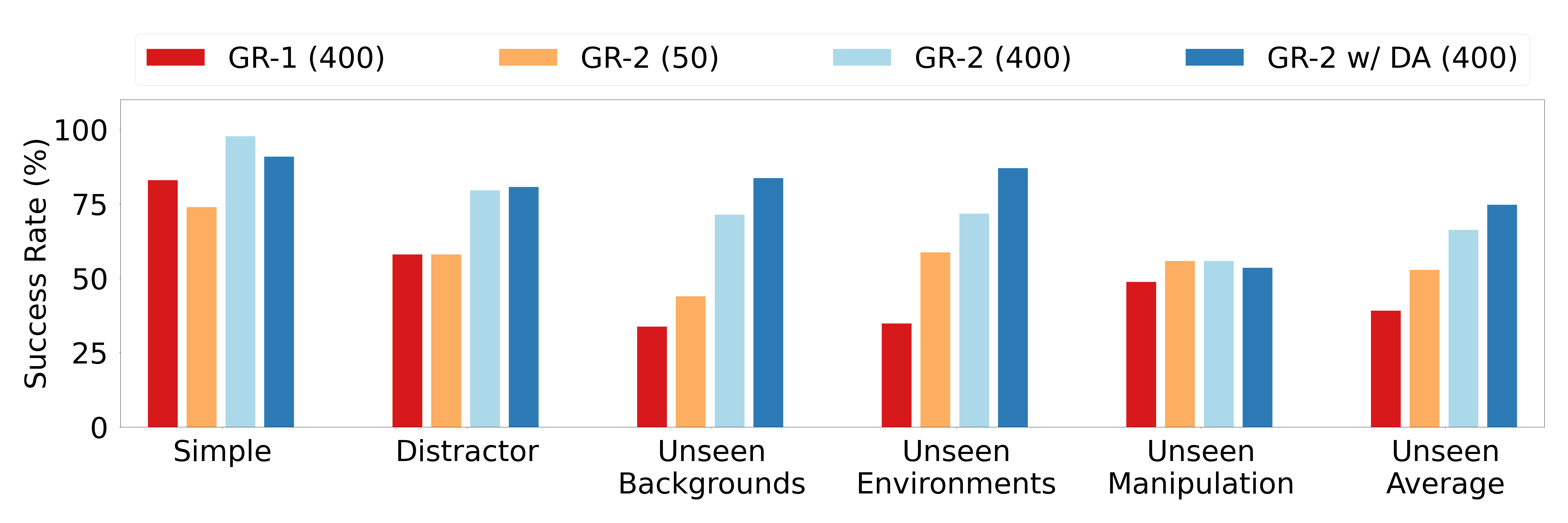
图源:GR-2,Figure 6。原图表达多任务真实机器人评测。本站读法:重点看 unseen manipulation 与其他条件的差距,这能暴露模型是否真的学会新操作组合。
第二组是 bin picking。这个设置更接近工业:源篮、目标篮、seen / unseen objects、cluttered settings。论文报告 GR-2 相比 GR-1 有明显提升,并且在 unseen 和 cluttered 条件下保持较强表现。这里 web video 和数据增强的作用更明显,因为随机物体和复杂堆叠更依赖视觉动态与物体先验。

图源:GR-2,Figure 7。原图表达 bin picking 的源篮、目标篮、seen / unseen objects 和 cluttered setting。本站读法:这组实验比固定桌面任务更能检查物体泛化和视觉拥挤场景。
第三组是 CALVIN 长链任务。每个 episode 要连续执行多条语言指令,指标会统计完成第 1 到第 5 个任务的比例。GR-2 在 5-task success 和 average length 上高于 GR-1,说明 future video + action trajectory 的序列建模对长链任务有帮助。
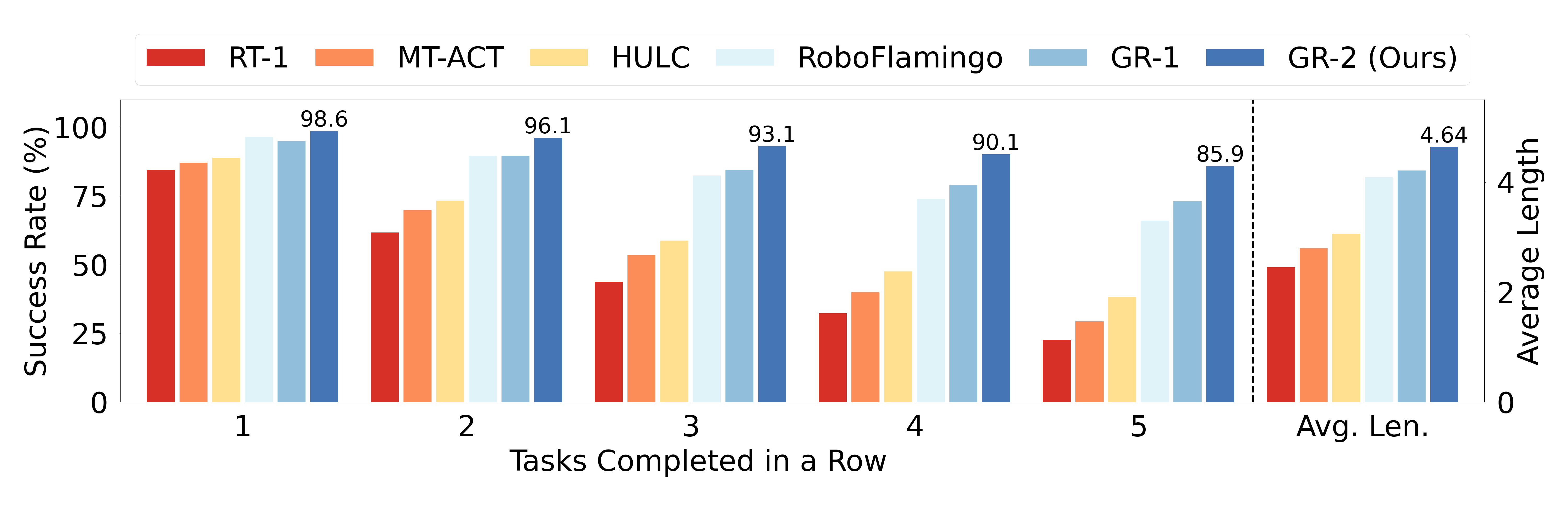
图源:GR-2,Figure 10。原图表达 CALVIN ABC-D 上 1 到 5 个连续任务的成功率。本站读法:长链任务最容易暴露误差累积,不能只看第一个子任务成功率。
和 DreamZero 的区别
GR-2 和 DreamZero 都把未来视频放进机器人 policy,但侧重点不同。GR-2 是 GPT-style video-language-action model,先用 web video 做生成式预训练,再用机器人数据把未来视频和动作轨迹一起学出来。DreamZero 则更强调 WAM:基于视频扩散 backbone,联合预测未来视频和动作,并通过系统优化做到实时闭环。
可以粗略理解为:GR-2 证明 web-scale video pretraining 能帮助机器人 manipulation;DreamZero 进一步追问视频世界模型本身能否成为 zero-shot policy。
边界与误解
第一,公开视频不是机器人 demonstration。GR-2 从中学的是视觉动态和物体交互先验,不是可直接执行的动作标签。
第二,future video 不是因果规划器。它帮助模型保持动态一致性,但并不显式搜索动作空间,也不保证安全约束。真实系统仍需要控制器和安全逻辑。
第三,105 个任务和 CALVIN 结果说明泛化能力强,但不能直接推出开放世界家务全覆盖。未见物体、透明/反光物体、柔性物体、双手协调和长时程任务分解仍是明显边界。
第四,模型变大带来提升,但也带来部署成本。GR-2 的 scaling 结果说明参数规模对视频生成 loss 和真实任务成功率有帮助,但机器人系统还要考虑控制频率、延迟和硬件可用性。
证据链快照
| 论文主张 | 主要证据 | 读数边界 |
|---|---|---|
| web video pretraining 能提供操作动态先验 | 38M clips / 50B tokens、future video prediction | 视频不是机器人 demonstration,没有动作标签 |
| 机器人微调要同时保留视频和动作目标 | video-language-action 训练链路、future video + action loss | future video 不是显式 planner,只是训练约束 |
| 真实机器人任务体现物体泛化 | 105 tasks、bin picking、CALVIN / real results | 不能外推到开放世界所有家务和灵巧操作 |
| 数据增强降低实验室分布依赖 | 背景、物体、任务变化实验 | 不替代真实失败恢复数据 |
| 模型 scale 有帮助但有成本 | scaling 结果和部署系统 | 控制频率、延迟和安全仍要单独验收 |
阅读结论
GR-2 最值得记住的是:web video pretraining 提供的是“物体互动会怎样演化”的动态先验,robot fine-tuning 提供的是“机器人怎样执行这种演化”的动作接口。未来视频不是展示用附件,而是训练目标的一部分;它让模型在动作预测时仍然保留对任务进展、物体状态和遮挡变化的想象。
所以 GR-2 是 VLA 路线里的一个关键证据:公开视频能帮助机器人操作,但帮助方式不是把公开视频当 demonstration,而是先学未来视觉,再用机器人轨迹把未来视觉和可执行动作对齐。它的边界也在这里:没有足够机器人动作数据、控制器和安全门禁时,视频动态先验不会自动变成可靠闭环控制。
外部精读
- GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation:论文原文,重点读 pretraining、robot fine-tuning 和真实机器人实验。
- GR-2 project page:项目页适合看任务视频和模型输出。
- ar5iv HTML version:在线阅读图表更方便。
- CALVIN benchmark:理解长链语言条件机器人操作评测。
- Diffusion Policy:作为动作生成路线对照,帮助区分 trajectory prediction 和 diffusion action generation。
相关阅读与下一步
- 外部材料:论文标题 arXiv 检索。
- 外部材料:Semantic Scholar 标题检索。
- 外部材料:Papers with Code 检索。
- 站内下一步:论文精读专题。
- 站内下一步:论文专题写作规范。
- 站内下一步:外部精读来源台账。
- Title: 论文专题讲解:GR-2:Web 视频知识怎样迁移到机器人操作
- Author: Charles
- Created at : 2025-09-26 09:00:00
- Updated at : 2025-09-26 09:00:00
- Link: https://charles2530.github.io/2025/09/26/ai-files-paper-deep-dives-embodied-ai-gr2/
- License: This work is licensed under CC BY-NC-SA 4.0.