
论文专题讲解:GR-2:Web 视频知识迁移到机器人
这页先按“论文证据节点”读:先问它解决哪一个瓶颈,再看核心图表、实验 setting 和不能外推的边界。背景概念先回 论文专题讲解 和 具身智能。
前置:不必先读完所有相关论文,但要知道本篇的输入、训练/推理路径和评测口径分别对应什么。
主线关系:读完后把结论回填到「具身智能」路线里,判断它改变的是机制、成本、数据配方、评测口径,还是仍停留在前沿假设。
- 论文:
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation - 链接:arXiv:2410.06158
- 关键词:video-language-action model、future video prediction、trajectory prediction、web-scale video pre-training、whole-body control
GR-2 的核心价值在于把“互联网视频里的动态先验”正式放进机器人策略训练:先在大规模人类活动视频上学习未来视频预测,再用少量真实机器人轨迹微调,让模型同时预测未来视频和机器人动作轨迹。
如果说 RT-1 证明 Transformer policy 可以吃真实机器人轨迹,GR-2 更像下一步:没有动作标注的普通视频,也能通过未来预测给机器人提供世界动态知识。
论文位置
传统 VLA 直接学:
GR-2 多走一步:让模型先通过视频预训练学“接下来会发生什么”,再在机器人数据上把未来视频和动作轨迹绑起来。论文 Figure 1 很好地展示了这条线。
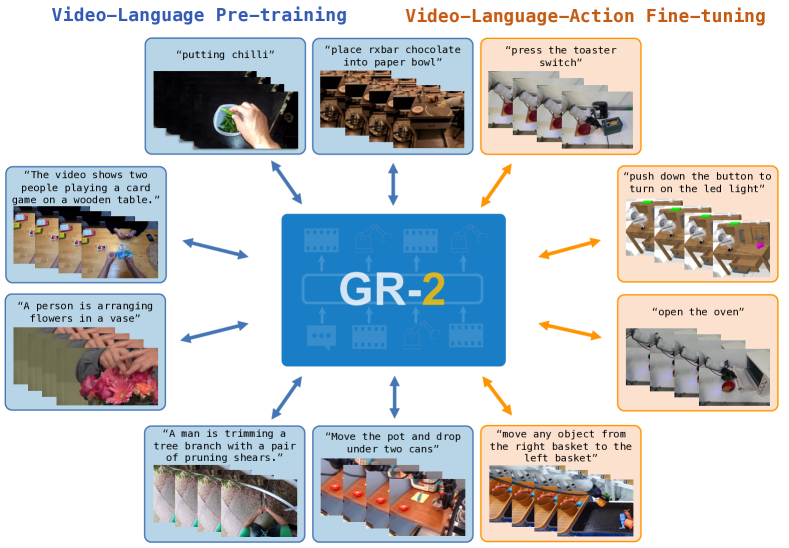
Figure source: GR-2, Figure 1. 原论文图意:GR-2 先在大规模视频数据上预训练,学习未来视频预测,再通过真实机器人轨迹微调,输出机器人动作轨迹并部署到真实机器人操作。
输入输出:输入是 web 视频、语言、机器人状态和真实轨迹,输出是未来视频与机器人动作轨迹。
效率机制:用大规模无动作视频学习动态先验,再用机器人数据对齐动作。
对主线意义:它说明普通视频可作为具身世界动态的预训练来源。
不能证明什么:视频预训练收益不能证明跨平台机器人和长时家庭任务都可靠。
这篇论文最适合放在具身智能专题里,因为它回答的是一个非常实际的问题:机器人数据很贵,能不能让无动作标注的视频数据也参与学习?
模型结构
GR-2 是一个 GPT-style visual manipulation policy,输入语言指令、历史环境观测和机器人状态,输出未来动作轨迹。
| Component | GR-2 choice | Why it matters |
|---|---|---|
| Model size | 230M parameters, 95M trainable | 模型不大,重点在训练配方和数据迁移 |
| Language encoder | frozen text encoder | 保持语言表征稳定 |
| Visual encoder | frozen VQGAN encoder | 把视频帧压成离散/latent 表示 |
| Robot state encoder | learnable linear layer | 编码 EEF position / angle 和 gripper state |
| Pre-training head | VQGAN decoder for future video frames | 让模型从普通视频中学动态先验 |
| Fine-tuning head | conditional VAE for future video and action | 把视频预测和动作轨迹预测对齐 |
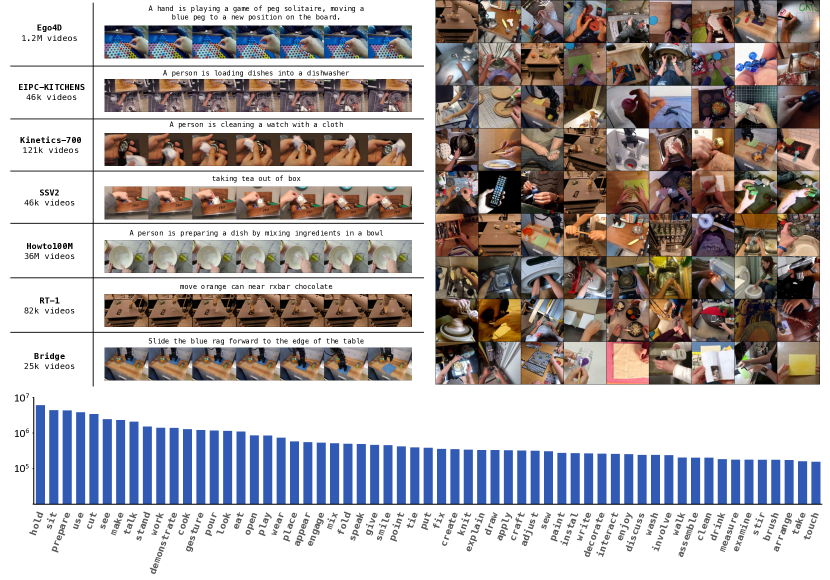
Figure source: GR-2, Figure 2. 原论文图意:展示 GR-2 使用的大规模视频预训练数据分布,以及从 web-scale 视频到机器人操作数据的训练路线。
输入输出接口
GR-2 可以写成一个条件生成模型。给定语言 、历史图像观测 、机器人状态 ,模型同时预测未来视频 token 和未来动作轨迹:
这里 是未来视觉轨迹, 是一段 Cartesian action trajectory,而不是单步电机命令。论文把这个接口做成 GPT-style sequence modeling:语言 token、图像 latent token、状态 token 和动作/视频目标被组织到同一个自回归序列里。它的直觉很像“先想象画面会怎么变,再让动作轨迹追随这个画面变化”。
如果只监督动作,模型从机器人数据里学到的是“当前图像到控制量”的映射;如果同时预测未来视频,模型必须解释动作会怎样改变场景。GR-2 的未来视频头不只是为了可视化,它给共享 trunk 提供了密集的动态监督,让无动作标注的 web video 也能参与预训练。
训练路线
论文的训练可以分成三段:
1 | web-scale video pre-training |
1. Web-scale video pre-training
GR-2 使用约 38M video clips 和 50B tokens 做预训练。通用视频数据覆盖家庭、户外、工作场所、休闲等日常活动;常见数据源包括 HowTo100M、Ego4D、Something-Something V2、EPIC-KITCHENS、Kinetics-700。
训练目标是:给定文本描述和当前视频帧,预测后续视频帧。这一步没有机器人动作,但能让模型获得大量动态知识:物体如何移动、手如何操作物体、容器如何开合、液体/工具/桌面场景如何变化。
从损失角度看,预训练主要优化未来视频 token 的似然:
注意 不是原始 RGB,而是 frozen VQGAN encoder 产生的视觉 token。这样做的好处是把像素空间的高频细节压掉,让模型主要在 token 序列上学习可预测的动态。代价是:预训练学到的是观察到的视觉变化,不天然知道“哪个动作导致了这个变化”。动作因果关系仍要靠机器人轨迹微调补齐。
2. Robot trajectory fine-tuning
机器人微调阶段同时学习 future video generation 和 action prediction。论文强调一个经验:预测动作轨迹比预测单步动作更好,轨迹更平滑,也更容易由控制器实时执行。
机器人数据包括:
| Dataset / setting | Scale | Role |
|---|---|---|
| Tabletop manipulation | 105 tasks, about 40K trajectories | 8 skills: picking, placing, uncapping, capping, opening, closing, pressing, pouring |
| Data-scarce setting | about 1/8 data, roughly 5K trajectories | 测少样本机器人数据下的视频预训练是否有帮助 |
| End-to-end bin picking | about 94K pick-and-place trajectories, 55 training objects | 测 clutter、unseen objects 和连续 picking |
| CALVIN ABC-D | 20K+ demonstrations, 34 tasks | 测语言条件长任务序列 |

Figure source: GR-2, Figure 4. 原论文图意:展示 105 个桌面任务和 8 类操作技能,说明 GR-2 的真实机器人训练覆盖了多个操作原语。
机器人微调时,损失可以理解为两条监督相加:
其中 监督未来一段末端执行器轨迹和夹爪状态, 控制动作监督相对视频监督的权重。这个分工很关键:future video 让 trunk 保持动态预测能力,action loss 把“画面变化”对齐到机器人可执行控制。若只保留视频预测,模型可以会想象但不会控制;若只保留动作预测,又失去 web video 预训练带来的动态先验。
单步动作容易变成局部纠偏:每一帧只看下一瞬间怎么动,长期轨迹可能抖。GR-2 预测的是未来一段 Cartesian 轨迹,控制器再做平滑和约束投影。对桌面操作来说,这等于让模型输出“接下来一小段运动意图”,而不是把每个 20ms 的低层控制都交给大模型。
3. Data augmentation
为了缓解机器人数据稀缺,论文使用物体替换和背景替换增强:扩散模型在指定区域插入新对象,SAM 提取背景区域,再用视频生成模型在保持机器人运动的同时生成增强视频。
这一步很有工程启发:如果模型要泛化到未见背景、未见环境和未见物体,数据增强必须尽量保持动作与机器人运动一致,不能只做静态图像扰动。
增强数据的读法要保守:它能扩展视觉外观分布,但不能凭空生成可靠的新接触动力学。如果替换出的物体形状、质量、抓取点和真实控制动作不匹配,动作监督会变噪。因此 GR-2 的增强更适合支撑“背景、外观、物体类别”泛化,而不是证明新技能已经被合成出来。
真实机器人系统
GR-2 使用 7-DoF Kinova Gen3 + Robotiq 2F-85 gripper。观测来自两个相机:
| Camera | Role |
|---|---|
| Static head camera | 提供工作空间全局视角 |
| Wrist camera | 提供夹爪与环境交互的近距离视角 |
模型预测 Cartesian space 轨迹。生成轨迹先经过优化提高平滑度和连续性,再由 WBC 把 Cartesian 轨迹转成低层 joint actions,并以约 200Hz 在真实机器人上执行。
这个细节说明:VLA 输出不是电机命令。论文里的控制系统把碰撞约束和可操作性放进优化框架,真正执行的是控制器投影后的低层动作。
实验结果
GR-2 的实验覆盖多任务学习、bin picking 和 CALVIN。
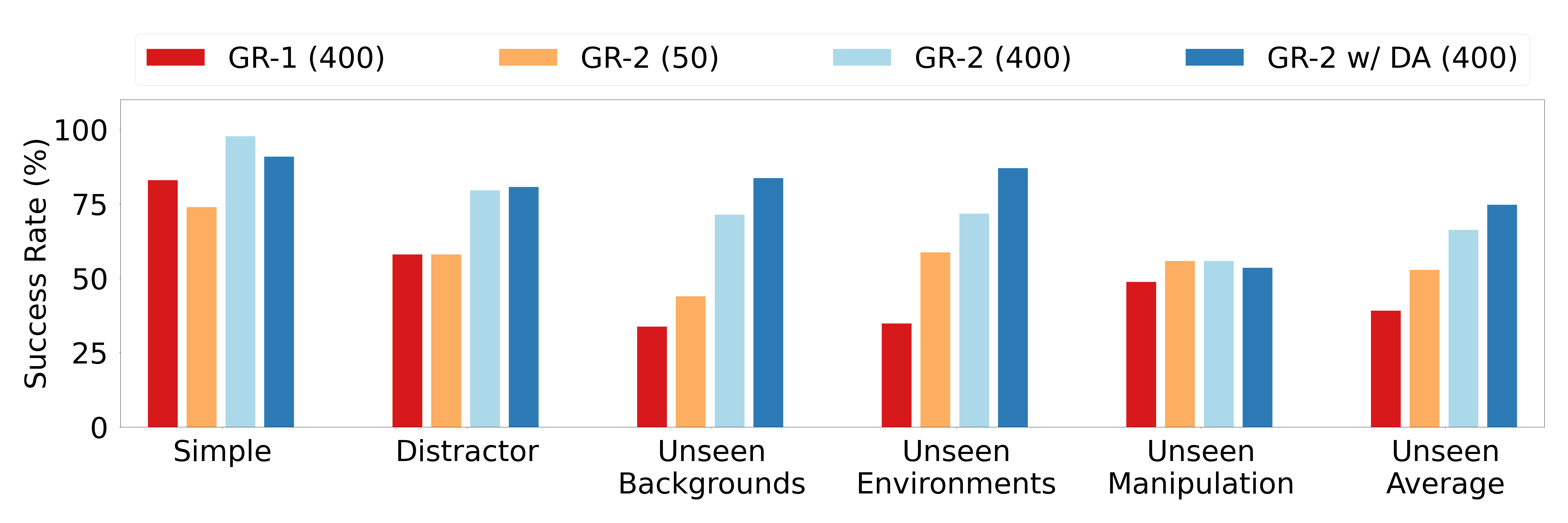
Figure source: GR-2, Figure 6. 原论文图意:展示多任务真实机器人评测,比较 Simple、Distractor、Unseen Backgrounds、Unseen Environments 和 Unseen Manipulation 等设置下的成功率。
论文的核心结论不是“某个任务分数更高”,而是三件事:
- web-scale video pre-training 可以迁移到真实机器人操作;
- 在机器人数据稀缺时,视频预训练带来的收益更明显;
- 轨迹预测比单步 action prediction 更适合平滑执行和实时控制。
这组真实机器人结果把泛化难度拆成五层:Simple 是训练分布附近任务;Distractor 检查多物体干扰;Unseen Backgrounds 和 Unseen Environments 检查视觉域迁移;Unseen Manipulation 才是真正难的未见物体/未见技能组合。GR-2 在前四类更强,说明 web video 和数据增强主要帮视觉与动态泛化;Unseen Manipulation 仍明显更难,论文也把失败归因到新形状物体抓取失败和指令中未见物体选择错误。

Figure source: GR-2, Figure 7. 原论文图意:展示 end-to-end bin picking 的源篮、目标篮、seen / unseen objects 和 cluttered settings。
bin picking 是这篇论文里最接近工业场景的一组实验。设置中有源篮和目标篮,指令固定为把右篮任意物体搬到左篮;训练数据约 94K 条 pick-and-place 轨迹、55 个训练物体。评测时共有 122 个物体,其中 67 个训练未见;还把初始物体数量从 5-9 提高到 12-17 构成 cluttered setting。论文报告 GR-2 平均成功率从 GR-1 的 33.3% 提升到 79.0%,并且 unseen / cluttered 条件和 seen 条件差距较小。
bin picking 的强证据是 closed-loop 真实机器人搬运,尤其覆盖透明、反光、柔性等视觉困难物体;但任务指令很简单,目标篮固定,不能外推成长时任务规划或复杂语言理解。它证明的是“动态视频预训练 + 轨迹策略”能改善物体搬运泛化,而不是完整家庭机器人能力。
在 CALVIN 上,GR-2 需要在 ABC-D split 中连续执行 5 个语言任务。这类评测比单步抓取更接近长时程具身系统。
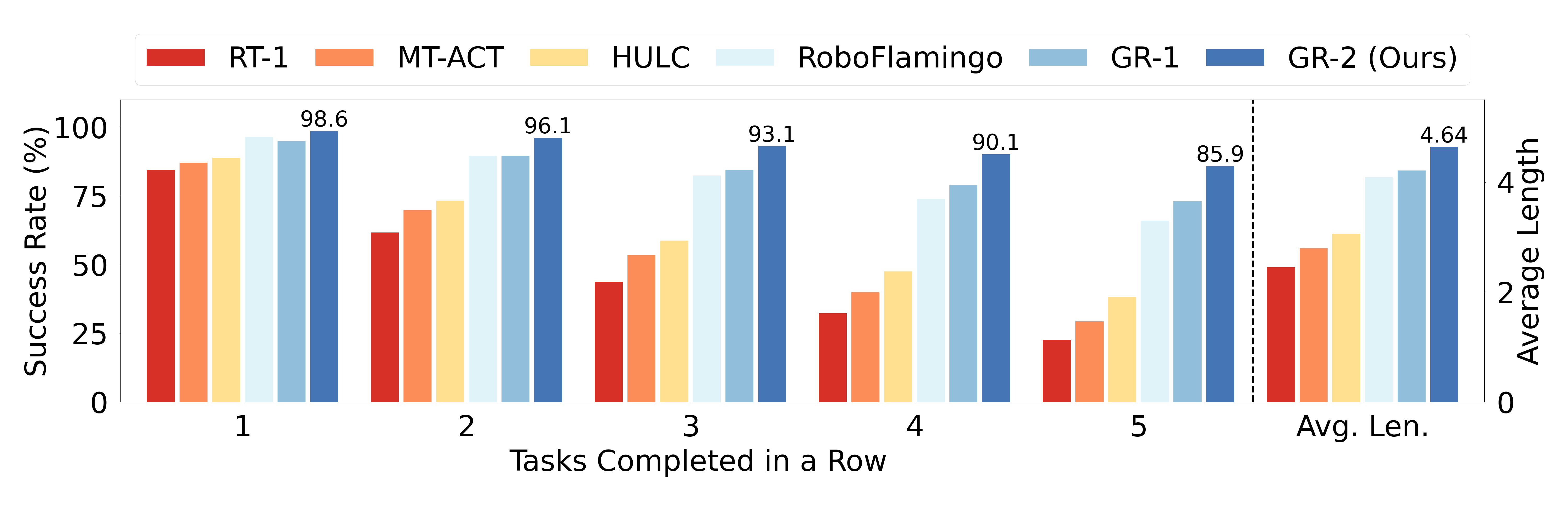
Figure source: GR-2, Figure 10. 原论文图意:展示 CALVIN ABC-D 上完成 1 到 5 个连续任务的成功率和 average length。
CALVIN 的意义在于长链语言条件控制。评测使用 ABCD-D split,约 20K+ demonstrations、34 个任务,每个 episode 要连续执行 5 条语言指令,并在 1000 条 instruction chains 上统计完成第 1 到第 5 个任务的比例。论文报告 GR-2 相比 GR-1 把 1-task success 从 94.9% 提到 98.6%,5-task success 从 73.1% 提到 85.9%,average length 从 4.21 提到 4.64。
这说明视频预测预训练不只提升单步抓取,也能改善连续任务里的状态保持。但 CALVIN 仍是仿真 benchmark,且环境和任务库固定;它不能替代真实厨房/家庭长时任务,也不能证明模型有失败恢复和无效指令拒绝能力。
Scaling 与视频生成诊断
论文还做了 model size scaling:GR-2-S、GR-2-B、GR-2-L、GR-2-XL 的 trainable parameters 分别约为 30M、95M、312M、719M。随着模型变大,视频生成 validation loss 下降,真实机器人子集评测成功率也上升。
这组实验的价值在于把“视频预测质量”和“动作成功率”拉到同一条曲线上。它支持的结论是:更强的视频动态模型可以转成更好的策略表征。它不支持的结论是:只要无限扩模型就能解决机器人泛化;未见操作和长时恢复仍需要任务数据、控制器、状态估计和安全机制。
训练细节要点
| Detail | GR-2 choice | Why it matters |
|---|---|---|
| Pre-training scale | 38M video clips, 50B tokens | 让模型从无动作标注视频中学习动态先验 |
| Robot data scarcity | 5K trajectories for 100+ tasks in scarce setting | 检验小样本机器人迁移 |
| Full tabletop data | 40K trajectories, 105 tasks | 覆盖 8 类技能和多任务泛化 |
| Bin picking data | 94K trajectories, 55 objects | 验证 clutter 和 unseen object generalization |
| Action output | Cartesian trajectory, not single action | 平滑、可优化、易接 WBC |
| Low-level execution | WBC at 200Hz | 把高层轨迹投影到可执行 joint actions |
| Cameras | static head + wrist camera | 兼顾全局语义和局部接触 |
局限
GR-2 还不是今天意义上的大 VLA。它的模型规模较小,任务主要集中在桌面操作和 bin picking,开放家庭长任务、无效指令拒绝、跨 embodiment scaling、动作块 flow matching 等问题还没有完全展开。
但它在具身智能论文谱系里很重要,因为它清楚地证明了一点:视频预测不是只为了生成好看的未来,它可以作为机器人策略的动态知识来源。
GR-2 的关键证据链是 web-scale future video pretraining 到机器人轨迹微调再到 WBC 执行。方法上视频预测提供动态先验,实验上 CALVIN、桌面和 bin picking 说明迁移收益;真正落地还要补开放长任务、失败恢复和安全控制。
参考链接
- 回到论文总入口:论文专题讲解,用同一套 claim / 图表 / 边界口径横向比较。
- 把本篇结论接回主题:具身智能。
- 按导航顺序继续:VPP:预测表征训练策略。
- Title: 论文专题讲解:GR-2:Web 视频知识迁移到机器人
- Author: Charles
- Created at : 2025-10-01 09:00:00
- Updated at : 2025-10-01 09:00:00
- Link: https://charles2530.github.io/2025/10/01/ai-files-paper-deep-dives-embodied-ai-gr2/
- License: This work is licensed under CC BY-NC-SA 4.0.