
论文专题讲解:SpatialVLA:3D 空间表征接入 VLA
这页先按“论文证据节点”读:先问它解决哪一个瓶颈,再看核心图表、实验 setting 和不能外推的边界。背景概念先回 论文专题讲解 和 具身智能。
前置:不必先读完所有相关论文,但要知道本篇的输入、训练/推理路径和评测口径分别对应什么。
主线关系:读完后把结论回填到「具身智能」路线里,判断它改变的是机制、成本、数据配方、评测口径,还是仍停留在前沿假设。
- 论文:
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models - 链接:arXiv:2501.15830
- 项目页:spatialvla.github.io
- 关键词:Ego3D Position Encoding、Adaptive Action Grids、spatial action tokens、cross-embodiment VLA
SpatialVLA 适合放在具身智能专题里的原因很明确:它不是单纯把 VLM 做大,而是问 VLA 最根本的空间问题:不同机器人相机安装不同、动作空间不同,模型怎样学到可迁移的 3D 空间动作知识?
论文位置
很多 VLA 方法把图像 token、语言 token 和动作 token 接起来,但 RGB 图像本身是 2D 投影。对抓取、放置、插入、避障来说,模型需要知道物体在 3D 空间里在哪里,动作又要把末端执行器带到哪里。
SpatialVLA 的方案是两边一起改:
- 输入侧加入
Ego3D Position Encoding; - 输出侧用
Adaptive Action Grids把连续动作离散成空间 action tokens。
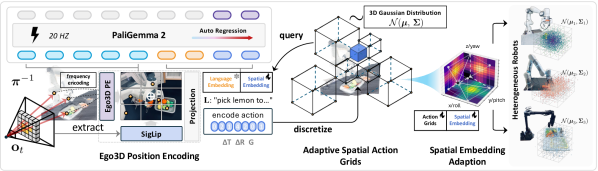
Figure source: SpatialVLA, Figure 1. 原论文图意:SpatialVLA 在视觉语言模型上加入 Ego3D position encoding 和 adaptive action grids,把 3D 空间上下文和动作 token 接入 VLA。
输入输出:输入是视觉语言观测、空间表征和动作网格,输出是 VLA 控制动作。
效率机制:把 3D 空间先验显式接入动作预测,降低纯图像 token 学空间关系的负担。
对主线意义:它连接 VLA 动作接口和具身几何状态。
不能证明什么:空间表征收益不能证明跨机器人平台或长时安全任务通用。
Ego3D Position Encoding
Ego3D 的直觉是:不要先追求全局世界坐标一致,而是在每个相机自己的 egocentric coordinate system 里恢复 3D 位置。这样可以减轻不同机器人相机外参不一致的问题。
流程可以写成:
1 | RGB image |
论文使用 ZoeDepth 估计 depth,再用相机内参反投影得到像素的 3D position。注意这里仍然需要 intrinsics,但不依赖跨机器人统一的 camera extrinsics。这一点和具身智能里的相机标定章节正好衔接:内参用于像素到相机坐标反投影,外参则在跨机器人泛化时往往难以统一。
更具体地说,如果像素坐标是 ,深度估计为 ,相机内参为 ,那么每个像素可被反投影到相机坐标系:
这里 是相机自身坐标系中的 3D 点; 给出从相机中心穿过该像素的射线方向; 决定沿射线走多远。SpatialVLA 再把这个 3D 位置做 sinusoidal encoding,经 MLP 投到和视觉 token 同维度的 embedding,并与 SigLIP 视觉 token 相加:
这条公式的关键不是数学复杂,而是接口清楚: 负责 2D 语义,例如杯子、盘子、抽屉; 负责相机坐标里的距离、方位和高度。模型不用猜“哪个像素更近、哪个物体在前方”,这些几何关系已经被写进 token。
跨机器人数据里,第三人称相机、腕部相机、外参标定和工作空间都不统一。若强行把所有观测拉到一个全局坐标系,标定误差和平台差异会先污染输入。Ego3D 的保守选择是只使用相机内参和单目深度,把空间关系表达在每个相机自己的坐标系里;它降低了跨 embodiment 对齐成本,但也意味着模型仍依赖深度估计质量和当前视角可见性。
Adaptive Action Grids
动作侧,SpatialVLA 不直接预测连续 ,而是根据数据集中动作分布,把 translation / rotation movement 离散成 adaptive spatial grids。
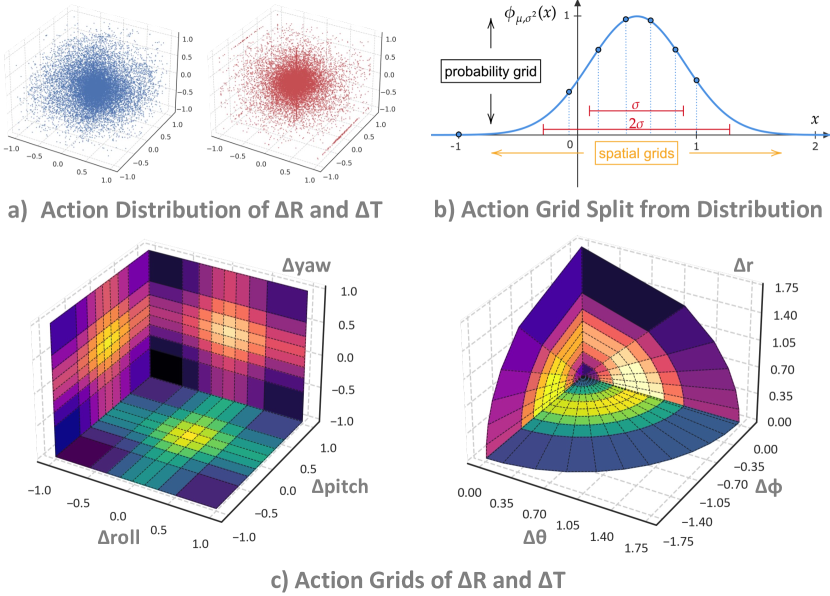
Figure source: SpatialVLA, Figure 2. 原论文图意:Adaptive action grids 先统计 translation 和 rotation action movement 的分布,再根据 Gaussian fitting 对每个动作变量划分等概率区间,形成空间动作 token。
| Design | Why it matters |
|---|---|
Normalize action variables to [-1, 1] |
消除不同机器人动作尺度差异 |
| Fit Gaussian distribution over action movement | 让网格跟真实动作分布对齐 |
| Split grids with equal probability | 高频动作区域更细,低频区域更粗 |
| Generate only 3 tokens per step | 比 RT-1 / RT-2 / OpenVLA 常见 7-token 动作更轻 |
| Re-discretize for new robots | 方便 post-training 适配新 embodiment |
这条路线的关键不是“离散化一定比连续动作好”,而是让动作 token 与物理空间统计对齐,减少跨 embodiment 动作空间错位。
论文把单臂动作拆成 translation、rotation 和 gripper 三块。translation 不是直接对 每一维均匀切桶,而是先把平移运动转成近似“方向 + 距离”的空间网格;rotation 也用同样的分布自适应思想;gripper 仍是开/合离散 token。一个动作步最终只需要预测 3 个空间动作 token:
设某个动作变量归一化后为 ,论文会在数据集上拟合高斯分布 ,再把区间切成 个等概率桶:
这和普通 uniform bins 的区别非常大:高频小动作附近会得到更细的分辨率,罕见大动作区域会更粗。对机器人控制来说,这很合理,因为真实策略的大量动作是小幅调整,少量动作才是大范围移动。如果把所有区间均匀切开,模型会浪费很多 token 容量在低频区域。
Post-training:为什么要重新离散化
SpatialVLA 的 post-training 不是只做 LoRA 或全参微调。新机器人或新任务的数据分布往往改变动作尺度和方向统计,所以论文会在新数据上重新拟合高斯分布,生成新的 action grids。新网格 token 的 embedding 不是随机初始化,而是从预训练网格附近的 token 通过 trilinear interpolation 得到:
其中 是新网格第 个 token 的初始 embedding, 是它在旧网格里的邻近 token, 由网格中心距离归一化得到。读法很简单:新机器人说“我的小幅向前动作长这样”,模型就把旧机器人上相近空间动作的知识搬过来,再用少量数据继续调。
训练数据和评测设置
论文先在约 1.1M real-world robot dataset 上预训练,数据混合由 OXE 和 RH20T 子集组成,并参考 OpenVLA 的 mixture weight 做修改。

Figure source: SpatialVLA, Figure 3. 原论文图意:评测覆盖 7 robot learning scenarios、24 real-robot tasks 和 3 simulation environments,关注 zero-shot control、new setup adaptation 和 spatial understanding。
论文附录还给出了 dataset mixture 可视化:
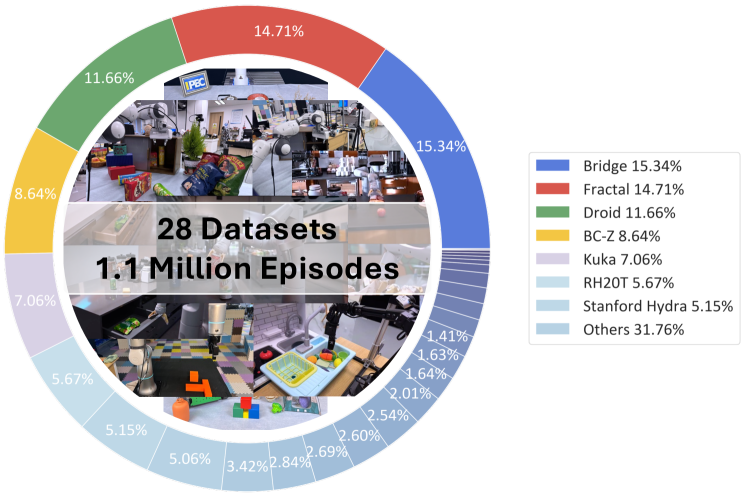
Figure source: SpatialVLA, Figure 8. 原论文图意:展示 SpatialVLA 训练数据混合的来源分布。
训练和部署条件也值得读细一点:SpatialVLA 使用 Paligemma2 系列 VLM 作为底座,在 64 A100 GPUs 上预训练约 10 days,batch size 为 2048。输入侧只条件于一个第三人称相机和一张当前图像来构造 Ego3D 表征;输出侧预测未来 action chunk,论文描述为 12 个 spatial action tokens,再执行 ensemble 后进入下一次预测。部署时,论文报告单张 RTX 4090 约 8.5GB 显存、约 20Hz,这使它更像实时控制策略,而不是离线规划器。
zero-shot 在这里不是开放世界任意任务,而是预训练数据分布附近的机器人/任务设置上直接部署;fine-tuning 则是在 Fractal、BridgeData V2、LIBERO 或 Franka 目标数据上继续适配。读结果时要区分 SimplerEnv、真实 WidowX、LIBERO 仿真和真实 Franka,它们不是同一种 closed-loop 证据。
实验结论
SpatialVLA 的评测不是只看一个 benchmark,而是分三类:
- zero-shot control:SimplerEnv 和 real-world WidowX;
- new setup adaptation:LIBERO 和 Franka 新设置;
- spatial understanding:需要空间关系理解的真实任务和 LIBERO-Spatial。
Table III from the paper can be redrawn as follows, keeping the original English fields:
| Method | LIBERO-Spatial SR ↑ | LIBERO-Spatial Rank ↓ | LIBERO-Object SR ↑ | LIBERO-Object Rank ↓ | LIBERO-Goal SR ↑ | LIBERO-Goal Rank ↓ | LIBERO-Long SR ↑ | LIBERO-Long Rank ↓ | Average SR ↑ | Average Rank ↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| Diffusion Policy from scratch | 78.3 ± 1.1% | 5 | 92.5 ± 0.7% | 1 | 68.3 ± 1.2% | 5 | 50.5 ± 1.3% | 5 | 72.4 ± 0.7% | 5 |
| Octo fine-tuned | 78.9 ± 1.0% | 4 | 85.7 ± 0.9% | 4 | 84.6 ± 0.9% | 1 | 51.1 ± 1.3% | 4 | 75.1 ± 0.6% | 3 |
| OpenVLA fine-tuned | 84.7 ± 0.9% | 2 | 88.4 ± 0.8% | 3 | 79.2 ± 1.0% | 2 | 53.7 ± 1.3% | 3 | 76.5 ± 0.6% | 2 |
| TraceVLA fine-tuned | 84.6 ± 0.2% | 3 | 85.2 ± 0.4% | 5 | 75.1 ± 0.3% | 4 | 54.1 ± 1.0% | 2 | 74.8 ± 0.5% | 4 |
| SpatialVLA fine-tuned | 88.2 ± 0.5% | 1 | 89.9 ± 0.7% | 2 | 78.6 ± 0.6% | 3 | 55.5 ± 1.0% | 1 | 78.1 ± 0.7% | 1 |
表源:SpatialVLA,Table III。原表含义:LIBERO Simulation Benchmark Results,汇报四个 task suites 的 success rate 和 rank,并对三次随机种子、500 trials 求均值。关键点是 SpatialVLA 的平均成功率最高,尤其在 LIBERO-Spatial 和 LIBERO-Long 上排名第一;这比单纯“加深度”更具体地说明 3D spatial encoding 对空间关系和长链任务都有帮助。
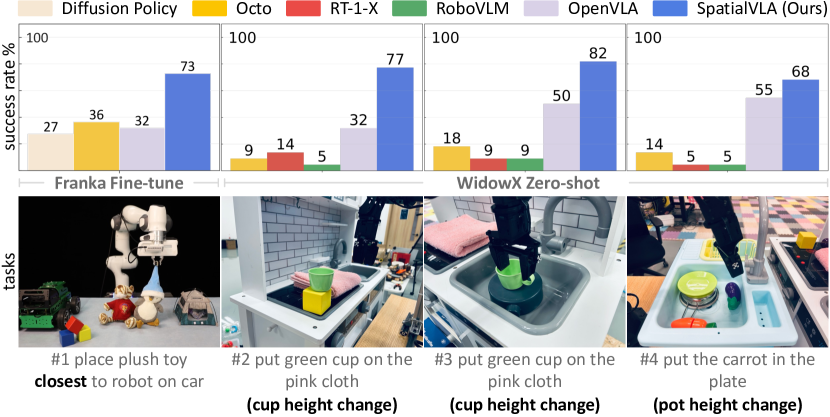
Figure source: SpatialVLA, Figure 6. 原论文图意:展示 SpatialVLA 在空间提示和复杂空间布局任务上的评测,说明 Ego3D position encoding 对 spatial understanding 有帮助。
Figure 6 不是普通成功率展示,而是在问模型是否真的利用了几何关系。Franka 任务要求理解 closest to robot 这类空间提示;WidowX 任务加入高度、位置和动态扰动;LIBERO-Spatial 则系统改变物体布局。SpatialVLA 在 Franka 空间提示任务达到约 73%,LIBERO-Spatial 达到 88.2%,而缺少深度/3D 输入的策略在复杂空间变化下更容易低于 50%。这支撑的是“3D 表征能改善空间布局泛化”,不是“所有机器人几何问题都解决”。
论文里几个关键结论:
| Question | Reported takeaway |
|---|---|
| Does 3D spatial input help? | Ego3D improves spatial prompt following and object-layout tasks |
| Does adaptive action tokenization help? | Spatial action grids improve transfer and action representation |
| Can it adapt to new robots? | Re-discretizing spatial grids helps new robot setup adaptation |
| Is LoRA useful? | In small-data LIBERO tasks, LoRA fine-tuning outperforms full fine-tuning |
消融实验:真正支撑方法的三根钉子
附录提到的训练消融很实用:pre-training ablations 在 Google Fractal + BridgeData V2 mixture 上从 scratch 训练,使用 8 A100 GPUs、batch size 128、120K steps。这些消融不是装饰,它们分别验证动作 token、网格分辨率和 3D encoding。
| Ablation | 论文中最有用的读数 | 结论 |
|---|---|---|
linear 256 bins vs adaptive grids |
Google Robot 上 variant aggregation / visual matching 大幅下降,论文报告 adaptive grids 分别带来约 +36.5% / +42.1% 提升 |
动作空间不能只按 RT 系列的逐维均匀 token 化;空间动作统计本身是知识 |
| uniform distribution vs fitted Gaussian | uniform grid 在多个任务上弱于数据分布初始化 | 等概率桶让 token 容量集中到高频动作区域,比平均铺开更适合模仿学习 |
| grid resolution | 8194 resolution 比 1026 resolution 在 Move Near、Put Eggplant 等任务上明显更稳 |
分辨率太低会让模型倾向小动作、慢动作;太高则要付出 token/样本效率成本 |
| w/o Ego3D | variant aggregation 从 81.6%/79.2% 降到 68.9%/66.7% |
3D 位置编码主要提升场景变化、纹理/光照变化和相机姿态变化下的稳健性 |
| spatial embedding adaptation | LIBERO 四个 suite 相对 LoRA 继续提升约 +4.6%、+5.1%、+2.2%、+5.4% |
新机器人小数据适配时,重离散化动作网格比只调语言/视觉参数更贴近控制问题 |
这里最有意思的反直觉点是:linear 256 bins 有时能得到更低的 L1 loss,但 closed-loop 成功率更差。这提醒我们,动作误差的平均距离不等于任务成功;一个物理动作 token 是否落在可执行、可迁移的空间动作簇里,往往比连续误差小一点更重要。
对具身智能的启发
SpatialVLA 提醒我们:VLA 的泛化问题不只是语言模型大小问题。跨机器人泛化至少有三层错位:
- 观测错位:相机位置、视角、内外参不同;
- 动作错位:自由度、控制器、工作空间不同;
- 数据错位:任务分布、采集协议和动作统计不同。
Ego3D 和 adaptive action grids 分别处理前两层。它不是最终答案,但给后续 VLA 设计一个明确方向:把 3D 空间和动作坐标系当成模型接口的一部分,而不是后处理细节。
局限
SpatialVLA 仍然依赖深度估计质量。单目深度在透明、反光、低纹理或尺度异常物体上会偏;长时任务也不是它的主要强项。论文里 LIBERO-Long 表现仍受限,说明空间表示能补几何,但不能自动解决长时记忆和任务规划。
SpatialVLA 的复用点在显式空间动作接口:方法要抓空间网格、动作 token 和数据混合;实验要看 spatial understanding、真实任务设置和不同动作表示消融。它适合补 VLA 的几何短板,但不能替代深度传感、控制器和碰撞检查。
参考链接
- 回到论文总入口:论文专题讲解,用同一套 claim / 图表 / 边界口径横向比较。
- 把本篇结论接回主题:具身智能。
- 按导航顺序继续:Depth Anything:大规模无标注单目深度。
- Title: 论文专题讲解:SpatialVLA:3D 空间表征接入 VLA
- Author: Charles
- Created at : 2025-10-08 09:00:00
- Updated at : 2025-10-08 09:00:00
- Link: https://charles2530.github.io/2025/10/08/ai-files-paper-deep-dives-embodied-ai-spatialvla/
- License: This work is licensed under CC BY-NC-SA 4.0.