
论文专题讲解:Video Prediction Policy:预测视觉表征训练机器人策略
这页先按“论文证据节点”读:先问它解决哪一个瓶颈,再看核心图表、实验 setting 和不能外推的边界。背景概念先回 论文专题讲解 和 具身智能。
前置:不必先读完所有相关论文,但要知道本篇的输入、训练/推理路径和评测口径分别对应什么。
主线关系:读完后把结论回填到「具身智能」路线里,判断它改变的是机制、成本、数据配方、评测口径,还是仍停留在前沿假设。
- 论文:
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations - 链接:arXiv:2412.14803
- 代码:roboterax/video-prediction-policy
- 关键词:predictive visual representations、text-guided video prediction、inverse dynamics、CALVIN、MetaWorld、real-world robots
VPP 的核心观点很漂亮:很多视觉策略只编码当前图像,而视频扩散模型内部包含“未来会怎样”的预测表征。把这些 predictive visual representations 拿来当 policy 的视觉条件,可以让机器人从视频模型的动态先验中受益。
证据等级与外推边界
VPP 的证据结构比较清楚:核心 claim 由 CALVIN / MetaWorld benchmark、真实机器人实验和表征可视化共同支撑;效率 claim 主要来自“single forward step 取中间表征”,而不是完整系统吞吐表。因此它适合作为“预测表征能帮 policy”的证据,不适合直接当成“完整视频 rollout world model 已经足够便宜”的证据。
flowchart LR
A["Text-guided video prediction"] --> B["Intermediate predictive representation"]
B --> C["Inverse dynamics policy"]
C --> D["CALVIN / MetaWorld"]
C --> E["Real robot tasks"]
B --> F["One-step encoder cost"]
D --> G["Evidence: benchmark"]
E --> H["Evidence: closed-loop"]
F --> I["Evidence: efficiency direction"]
| 论文结论 | 证据来源 | 证据等级 | 可外推到世界模型高效训练 | 不能直接外推 |
|---|---|---|---|---|
| 预测视觉表征比静态表征更适合策略 | CALVIN、MetaWorld、真实机器人结果 | Benchmark + Closed-loop | 世界模型中间 latent 可以作为 policy state,而不必每次生成完整未来视频 | 不能证明所有 video latent 都天然对动作有用 |
| one-step TVP 表征已经包含运动趋势 | one-step prediction 可视化和 policy 性能 | Qualitative + Benchmark | 训练时可把“未来感”压进状态表示,降低完整视频生成成本 | 不能把模糊 one-step 图像当作可靠物理仿真 |
| 互联网人类/机器人操作视频能补动态先验 | 数据规模、采样比例和下游结果 | Dataset evidence + Benchmark | 世界模型数据引擎应混合人类视频、机器人视频和目标任务轨迹 | 不能说明无动作标注视频足以学习动作因果性 |
| inverse dynamics 能把预测表征接到动作 | diffusion action model 和机器人实验 | Benchmark + Closed-loop | 可借鉴“视频预测表征 + 动作解码器”的模块分工 | 不能替代 action-conditioned rollout 和反事实动作评测 |
| 真实机器人验证覆盖多平台任务 | Panda、xArm + XHand 任务集合 | Closed-loop signal | 论文不是纯仿真结果,适合作为具身表征迁移参考 | 不能外推到开放家庭长时任务和安全拒绝执行 |
对本站主线,VPP 最值得吸收的是:世界模型训练不一定每一步都生成清晰视频;有时只需要一个含未来动态的 latent state,再由 policy 或 action head 使用它。它最需要补的证据是动作反事实:同一历史下改变候选动作时,中间表征是否足够区分未来后果。
论文位置
GR-2 是“视频预训练 + 机器人轨迹微调”;DreamZero 是“joint video-action prediction”;VPP 介于两者之间:它先训练文本引导的视频预测模型,然后用视频模型的中间表征训练逆动力学 policy。
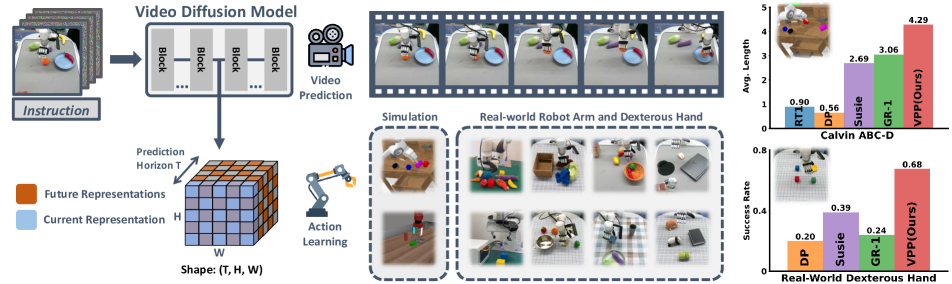
Figure source: Video Prediction Policy, Figure 1. 原论文图意:视频 diffusion model 内部表征同时包含当前信息和未来预测信息;VPP 基于这些表征在多个 benchmark 上提升机器人策略表现。
输入输出:输入是 text-guided video prediction 的中间表征和机器人观测,输出是 policy 动作。
效率机制:复用预测表征而非完整生成视频,降低把动态先验接入策略的成本。
对主线意义:它说明“未来 latent”可以直接服务 VLA policy。
不能证明什么:预测表征提升不能证明显式世界模型或反事实动作规划已成立。
两阶段训练
论文流程很清晰:
1 | Stage 1: train Text-guided Video Prediction (TVP) |
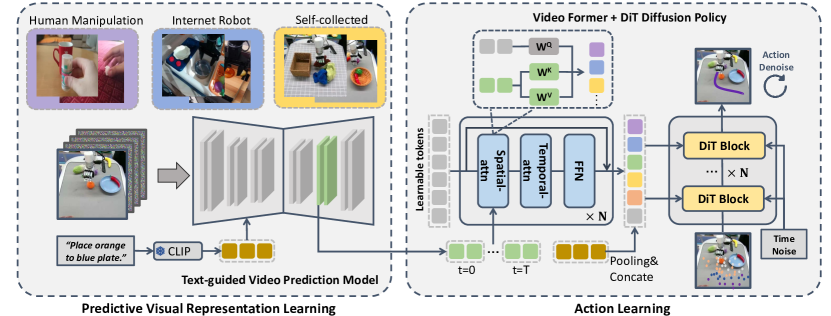
Figure source: Video Prediction Policy, Figure 3. 原论文图意:VPP 先从预训练视频 foundation model 出发训练 text-guided video prediction model,再基于 TVP 内部预测表征学习机器人动作。
Stage 1:Text-guided Video Prediction
VPP 的第一阶段不是直接训练机器人策略,而是把预训练视频扩散模型调成一个文本条件未来预测模型。给定当前/历史视频帧 和语言 ,TVP 学习预测未来帧:
在扩散模型里,它实际学习的是去噪目标。若 是未来视频 latent, 是加噪后的 latent,模型学习预测噪声或速度:
这里最重要的是条件:模型不只是做通用视频生成,而是在操作视频和机器人数据上学习“给定任务语言和当前观测,未来该往哪个方向演化”。这就是 predictive visual representation 的来源。
Stage 2:Inverse Dynamics Policy
第二阶段把 TVP 当成 future-aware encoder。VPP 从视频扩散模型中取中间表征 ,再训练一个动作扩散/DiT 策略:
这可以看成 implicit inverse dynamics:TVP 内部表征暗示“未来视觉会怎样变”,policy 学“要让未来这样变,现在该怎么动”。注意它不是显式规划器,没有枚举候选动作并 rollout;它把未来预测压缩进视觉表征,再用动作模型直接解码。
为什么用中间表征,而不是完整生成视频
论文的关键工程选择是:VPP 把视频 diffusion model 主要当作 vision encoder,而不是完整 denoiser。它只做 single forward step,得到并不清晰但含有未来运动趋势的中间表征。
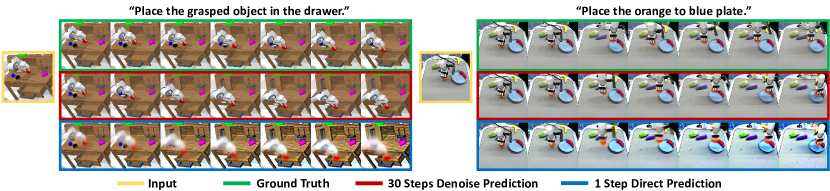
Figure source: Video Prediction Policy, Figure 5. 原论文图意:比较 ground-truth video、完整 denoised video 和 one-step forward predictions;one-step 纹理不清晰,但已经包含物理演化信息。
这个选择非常具身:机器人 policy 不需要每次生成好看的未来视频,它需要低延迟、对动作有用的表示。中间表征比完整视频便宜,也比普通静态视觉 encoder 更有动态信息。
这张图要反着读:one-step prediction 画面模糊,正是它的工程价值。若策略每个控制周期都要完整 denoise 出高清视频,延迟会压垮 closed-loop 控制;VPP 只取 single forward step 的内部表示,让纹理不完整但运动方向、物体接触趋势和目标变化已经进入 latent。它支撑的是“预测表征可用”,不是“单步图像可当真实模拟器”。
数据与训练细节
VPP 的 TVP 训练数据包括:
| Data source | Scale / role |
|---|---|
| Something-Something-V2 human manipulation | 193,690 human manipulation trajectories |
| Internet robotic manipulation datasets | 179,074 high-quality trajectories |
| CALVIN ABC | downstream long-horizon robot data |
| MetaWorld | 50 tasks, oracle trajectories |
| Real-world robot datasets | Panda arm and xArm + XHand tasks |
论文记录 TVP 训练约 two days on eight NVIDIA A100 GPUs。动作策略阶段再用 TVP 的中间预测表征训练 diffusion action model。
英文原表中 Table 9 给出 dataset scales and sample ratios;这里不逐项全文搬表,但保留一个工程重点:VPP 不是把所有数据均匀混合,而是根据数据规模和质量设置采样概率。
几个训练细节对复用很关键:
| Detail | Why it matters |
|---|---|
| Stable Video Diffusion initialization | 让 TVP 从已有视频动态先验出发,而不是从机器人小数据冷启动 |
| CLIP text features | 语言条件进入视频预测,避免只学无条件未来 |
| Human manipulation + robot video mixture | 人类视频补丰富动态,机器人视频补相机和任务分布 |
| Single forward representation | 控制侧只取中间表征,不承担完整视频生成延迟 |
| Diffusion inverse dynamics policy | 用生成式动作头处理多模态动作分布 |
这也解释了为什么 VPP 和 GR-2 相似但不一样:GR-2 同时生成未来视频和动作轨迹,VPP 则更激进地把视频生成压成“取中间表示”,让部署时不必真的生成完整未来。
实验结果
VPP 在 CALVIN 和 MetaWorld 上验证了 predictive visual representations 的价值。
| Benchmark | Setup | Main claim |
|---|---|---|
| CALVIN | ABC→D, five chained tasks | VPP improves average task completion length |
| MetaWorld | 50 tasks with language-conditioned policy | VPP improves average success rate over strong baselines |
| Real-world Panda | 30+ tasks, 6 skills, about 2000 trajectories | predictive representations transfer to real robot |
| xArm + XHand | 100+ tasks, 13 skills, about 4000 trajectories | dexterous manipulation and tool-use settings |
Table 1 from the paper can be redrawn as follows, keeping the original English fields:
| Category | Method | Annotated Data | 1 | 2 | 3 | 4 | 5 | Avg. Len ↑ |
|---|---|---|---|---|---|---|---|---|
| Direct Action Learning Method | RT-1 | 100%ABC | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 |
| Direct Action Learning Method | Diffusion Policy | 100%ABC | 0.402 | 0.123 | 0.026 | 0.008 | 0.00 | 0.56 |
| Direct Action Learning Method | Robo-Flamingo | 100%ABC | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.47 |
| Future Prediction Related Method | Uni-Pi | 100%ABC | 0.560 | 0.160 | 0.080 | 0.080 | 0.040 | 0.92 |
| Future Prediction Related Method | MDT | 100%ABC | 0.631 | 0.429 | 0.247 | 0.151 | 0.091 | 1.55 |
| Future Prediction Related Method | Susie | 100%ABC | 0.870 | 0.690 | 0.490 | 0.380 | 0.260 | 2.69 |
| Future Prediction Related Method | GR-1 | 100%ABC | 0.854 | 0.712 | 0.596 | 0.497 | 0.401 | 3.06 |
| 3D Method | 3D Diffuser Actor | 100%ABC | 0.938 | 0.803 | 0.662 | 0.533 | 0.412 | 3.35 |
| Ours | VPP (ours) | 100%ABC | 0.957 | 0.912 | 0.863 | 0.810 | 0.750 | 4.29 |
| Data Efficiency | MDT | 10%ABC | 0.408 | 0.131 | 0.034 | 0.008 | 0.001 | 0.58 |
| Data Efficiency | GR-1 | 10%ABC | 0.672 | 0.371 | 0.198 | 0.108 | 0.069 | 1.41 |
| Data Efficiency | VPP (ours) | 10%ABC | 0.878 | 0.746 | 0.632 | 0.540 | 0.453 | 3.25 |
表源:Video Prediction Policy,Table 1。原表含义:CALVIN ABC→D zero-shot long-horizon evaluation,1 到 5 表示连续完成第 1 到第 5 个任务的比例,Avg. Len 是平均完成链长。最值得注意的是,VPP 不用 depth / point cloud,仍把平均链长从 3D Diffuser Actor 的 3.35 推到 4.29;只用 10%ABC 标注数据时也达到 3.25。
CALVIN 不是单任务成功率,而是连续 5 个语言任务的链式完成。1 到 5 的数字越往右越难,因为前一步失败会阻断后续任务。VPP 最突出的不是第一个任务 0.957,而是第 5 个任务仍有 0.750,说明预测表征对状态保持和长链执行有帮助。10%ABC 设置更关键:只用十分之一标注数据时,VPP 的 Avg. Len=3.25 接近强 3D baseline 的完整数据表现,说明动态先验确实缓解了机器人标注稀缺。

Figure source: Video Prediction Policy, Figure 7. 原论文图意:展示 Panda arm 和 xArm + 12-DoF XHand 两个真实硬件平台及任务可视化。
真实机器人结果的读法要分平台。Panda arm 覆盖 30+ tasks、6 skills、约 2000 trajectories,主要验证普通机械臂桌面操作;xArm + XHand 覆盖 100+ tasks、13 skills、约 4000 trajectories,强调灵巧手、工具和更复杂接触。论文摘要报告复杂真实灵巧操作成功率相对提升约 31.6%,这说明 predictive representation 不只在仿真里有效,但仍属于受控任务集合,而不是开放家庭环境。
论文还可视化了 predictive representations:

Figure source: Video Prediction Policy, Figure 12. 原论文图意:绿色是真实未来,红色是预测未来,蓝色是 predictive representations 的可视化;即便细节不精确,运动趋势已经出现。
这张图是 VPP 的机制诊断。绿色真实未来、红色预测未来和蓝色表征可视化不是为了证明图像生成很漂亮,而是说明中间 representation 已经朝未来物体运动、手部接触或目标状态变化聚焦。如果蓝色区域只响应当前静态纹理,它就和普通视觉 encoder 没太大区别;如果它开始响应即将发生变化的区域,才说明 TVP 给 policy 提供了未来感。
Ablation:预测表征到底贡献在哪里
VPP 的实验可以压成三个对照问题:
| Question | Evidence | Takeaway |
|---|---|---|
| 只用静态视觉 encoder 够不够 | CALVIN / MetaWorld 与 RT-1、Diffusion Policy、Robo-Flamingo 等对比 | 静态表征能识别物体,但对长链状态变化和动作趋势不够 |
| 显式未来预测是否有用 | Uni-Pi、Susie、GR-1 等 future-prediction 方法对照 | 未来预测类方法整体更强,VPP 进一步把中间表征直接接入 policy |
| 需要完整生成视频吗 | one-step representation 与完整 denoising 可视化 | policy 需要低延迟 future-aware latent,不需要每步生成清晰视频 |
最重要的消融结论是:VPP 的收益来自“视频预测模型的内部表示”,不是来自额外深度、点云或真实 3D 几何。它说明 future-aware latent 可以补足静态视觉,但也留下一个问题:这个 latent 是否能处理反事实动作,例如同一状态下往左推和往右推会导致不同未来?原论文主要证明表征有用,还没有完全证明它是 action-conditioned simulator。
训练细节要点
| Detail | VPP choice | Why it matters |
|---|---|---|
| Video backbone | Stable Video Diffusion + CLIP text features | 从视频 foundation model 继承动态先验 |
| TVP objective | text-guided video prediction | 让模型按语言预测操作未来 |
| Policy input | intermediate predictive representation | 避免完整视频生成成本 |
| Inference | single forward step as encoder | 低延迟,适合控制 |
| Action model | diffusion inverse dynamics | 从预测表征生成动作 |
| Training compute | two days on 8 A100 for TVP | 说明路线相对可复现 |
| Real robots | Panda 30+ tasks / xArm + XHand 100+ tasks | 验证不是只在仿真有效 |
和 GR-2、DreamZero 的区别
| Dimension | GR-2 | VPP | DreamZero |
|---|---|---|---|
| Video role | pre-training and future video prediction | predictive representation encoder | joint video-action generation |
| Action learning | robot trajectory fine-tuning | inverse dynamics from TVP features | action latent co-denoising |
| Deployment | trajectory + WBC | policy from visual representation | WAM as closed-loop policy |
| Main insight | web video helps robot manipulation | future-aware visual features help policy | world-action model can be zero-shot policy |
VPP 的独特位置在于:它不要求每次部署都生成高质量未来视频,也不把视频和动作完全合并到一个大生成器里,而是把视频模型内部的“未来感”抽出来给策略用。
局限
VPP 的表征依赖 TVP 的预测质量。若 TVP 在新场景里预测错误动态,policy 也会被误导。另外,它的真实机器人数据仍以可控平台和任务集合为主,开放家庭长时任务、无效指令拒绝、跨房间记忆等问题还需要其他机制。
VPP 的方法证据是用视频预测表征服务策略,而不是把未来帧当最终产品;实验要看 one-step prediction、real robot 和 predictive representation 消融。它支持“动态预测能改进控制表征”,但长期接触、恢复和多任务泛化仍需真机闭环。
参考链接
- 回到论文总入口:论文专题讲解,用同一套 claim / 图表 / 边界口径横向比较。
- 把本篇结论接回主题:具身智能。
- 按导航顺序继续:SpatialVLA:3D 表征接入 VLA。
- Title: 论文专题讲解:Video Prediction Policy:预测视觉表征训练机器人策略
- Author: Charles
- Created at : 2025-10-11 09:00:00
- Updated at : 2025-10-11 09:00:00
- Link: https://charles2530.github.io/2025/10/11/ai-files-paper-deep-dives-embodied-ai-video-prediction-policy/
- License: This work is licensed under CC BY-NC-SA 4.0.