
论文专题讲解:ZeRO:数据并行真正浪费的是训练状态副本
论文题名: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models。
作者: Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase、Yuxiong He。
机构: 未在公开元数据中稳定解析;以 arXiv/PDF 或官方页 affiliation block 为准。
时间 / 主题: 2019-10;高效训练。
arXiv / 官方报告: arXiv:1910.02054;官方材料:www.microsoft.com/en-us/research/publication/zero-memory-optimizations-toward-training-trillion-parameter-models/。
GitHub / 项目: GitHub:未找到官方链接;项目页:www.microsoft.com/en-us/research/publication/zero-memory-optimizations-toward-training-trillion-parameter-models/。
元数据来源与核验口径: 来源:arXiv;官方 / 项目材料;Checked Date:2026-06-15;Repro Status:Paper / official materials reviewed, independent reproduction not claimed。
ZeRO 要解决的问题不是“模型太大”这么笼统,而是更精确的一笔显存账:普通 data parallel 让每张 GPU 都保存完整 parameters、gradients 和 optimizer states。GPU 数量增加后,计算吞吐和全局 batch 可以变大,但单卡上那份训练状态没有变小。于是训练大模型时,你经常不是被 fp16 权重本身卡住,而是被 Adam 状态、梯度、master weights、激活和临时 buffer 一起挤爆。
ZeRO 的核心思想很朴素:既然 data-parallel ranks 训练的是同一个模型,就不应该让每张卡长期保存同一份训练状态;把 optimizer states、gradients、parameters 分阶段切到不同 ranks,需要时再通信取回。
先拆显存:model states 和 residual states
ZeRO 论文把训练显存分成两类。第一类是 model states:参数、梯度和优化器状态。它们的大小主要跟参数量 成正比。第二类是 residual states:activations、temporary buffers、memory fragmentation 等。它们通常跟 batch size、sequence length、layer 数、通信实现和 allocator 行为有关。
很多 OOM 排查会直接说“模型放不下”,但这句话不够精确。一个 1.5B 参数模型的 fp16 权重只有约 3GB;可是训练时还要保存梯度、fp32 master weights、Adam 一阶矩、Adam 二阶矩,激活和各种通信 buffer 也要占空间。ZeRO-DP 主要处理 model states 的冗余,ZeRO-R 才进一步处理 residual memory。
为什么 mixed precision Adam 是
以 mixed precision Adam 为例,单个参数的训练状态可以粗略拆成:
| 状态 | dtype | 每参数字节 |
|---|---|---|
| fp16 parameter | fp16 | 2 |
| fp16 gradient | fp16 | 2 |
| fp32 master parameter | fp32 | 4 |
| Adam first moment | fp32 | 4 |
| Adam second moment | fp32 | 4 |
所以普通 data parallel 里,每张 GPU 的 model states 约是:
这里的 是参数个数,不是字节数。若 ,那么仅 model states 就约 24GB,还没算 activations、workspace、fragmentation 和通信 buffer。这个数字解释了为什么“大模型训练显存”不能只看模型权重文件大小。
ZeRO-DP:三阶段分别切掉什么冗余
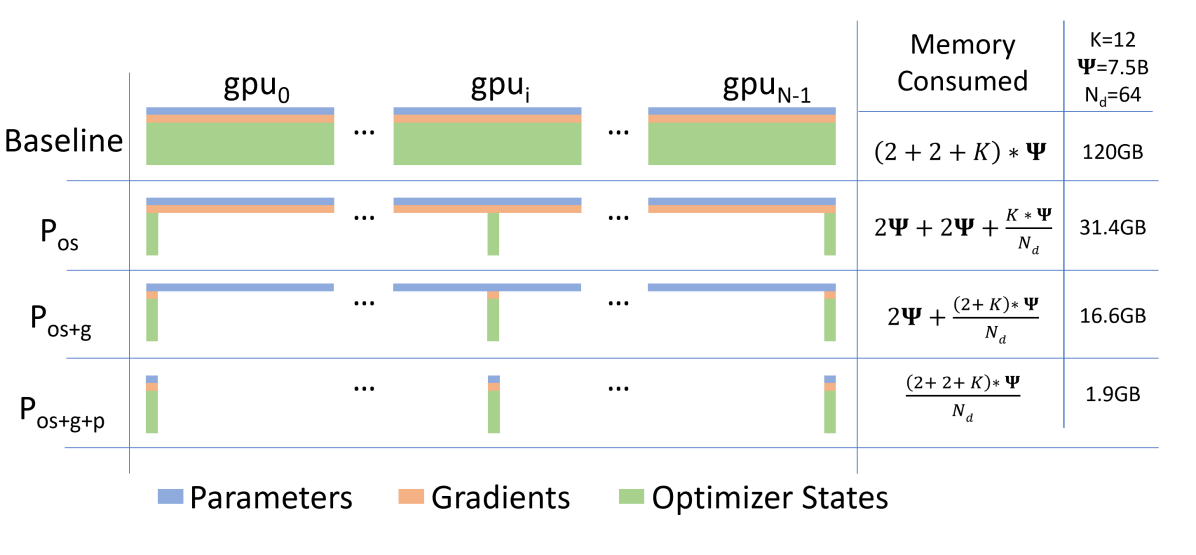
图源:ZeRO: Memory Optimizations Toward Training Trillion Parameter Models,Figure 1。原图表达 ZeRO-DP 三阶段依次分片 optimizer states、gradients、parameters,并比较每卡 model-state 显存。本站读法是先看“长期常驻对象”:Stage 1 切 optimizer,Stage 2 继续切 gradients,Stage 3 连 parameters 也按需切。
设数据并行度为 ,Adam optimizer states 约 bytes,fp16 gradients 约 ,fp16 parameters 约 。忽略小的 metadata 和临时 buffer 后,三个阶段的单卡 model-state 显存可以这样读:
这些式子最重要的不是精确到每个 runtime buffer,而是看懂“谁被分片、谁还常驻”。ZeRO-1 仍然让每张卡保存完整参数和梯度,只把 Adam 状态切开;ZeRO-2 让梯度也按 optimizer shard 对齐;ZeRO-3 则让参数本身不再长期完整复制。
Stage 1:optimizer state sharding
普通 DP 中,每张卡都拿到完整梯度,然后每张卡都更新完整模型参数,因此每张卡都需要完整 Adam states。ZeRO-1 改变的是“谁负责更新哪一片参数”:每个 rank 只保存自己那片参数对应的 fp32 master weight、momentum 和 variance。梯度同步后,每个 rank 只更新自己的 partition,再把更新后的参数结果广播或同步给其他 ranks。
这一步通常性价比很高,因为 Adam states 很大,而参数计算路径还相对接近普通 DP。它适合 optimizer states 是主要瓶颈、但还不想引入更复杂 parameter all-gather 生命周期的场景。
Stage 2:gradient partitioning
ZeRO-2 继续问:既然每个 rank 只更新 optimizer state 的一片,那它真的需要长期保存完整梯度吗?答案是不需要。梯度可以通过 reduce-scatter 直接规约到对应 partition,而不是 all-reduce 后让每张卡都拿到一整份梯度。
从工程角度看,Stage 2 的关键是把“梯度同步”改写成“同步并分发”。这样 optimizer partition 和 gradient partition 对齐,显存进一步下降。代价是通信 bucket、reduce-scatter、overlap window 和 gradient accumulation 的实现细节变得更重要。
Stage 3:parameter partitioning
ZeRO-3 最激进:参数也不再完整常驻每张卡。forward 或 backward 需要某一层参数时,runtime all-gather 这一层或这一组参数;计算完成后,参数可以释放或重新分片。这样单卡 model states 可以接近随 缩小。
这也是 Stage 3 的复杂性来源。参数生命周期不再是“训练开始加载一次,整个 step 常驻”,而是“按计算顺序 gather、使用、释放、反向再 gather”。这会影响通信重叠、module wrapping、checkpoint 保存、state dict 导出、offload 策略和故障恢复。ZeRO-3 省显存最强,但它把系统压力转移到带宽、调度和状态管理。
ZeRO-R:模型状态不是全部显存
如果只记住 ZeRO-1/2/3,会漏掉论文另一半:ZeRO-R。ZeRO-DP 减少的是 model states 冗余;ZeRO-R 处理 residual states,包括 activation checkpoint partitioning、constant-size buffers 和 memory defragmentation。
Activation checkpointing 用重计算换显存,但在 model parallel 或 data parallel 组合下,activation checkpoint 本身也可能出现冗余。partitioned activation checkpointing 会把 checkpointed activations 分片,需要时再恢复。Constant-size buffers 处理的是通信和临时算子 buffer 随模型规模膨胀的问题。Memory defragmentation 关注长生命周期 tensor 和短生命周期 tensor 混在一起导致大块连续显存不可用的问题。
这个区分很实用:如果 OOM 来自 Adam states,ZeRO-1/2 可能直接有效;如果来自长序列 activations,activation checkpointing、sequence/context parallel 或 attention kernel 更直接;如果来自 allocator fragmentation,换 ZeRO stage 也未必治本。
实验图应该看规模、吞吐和显存三件事
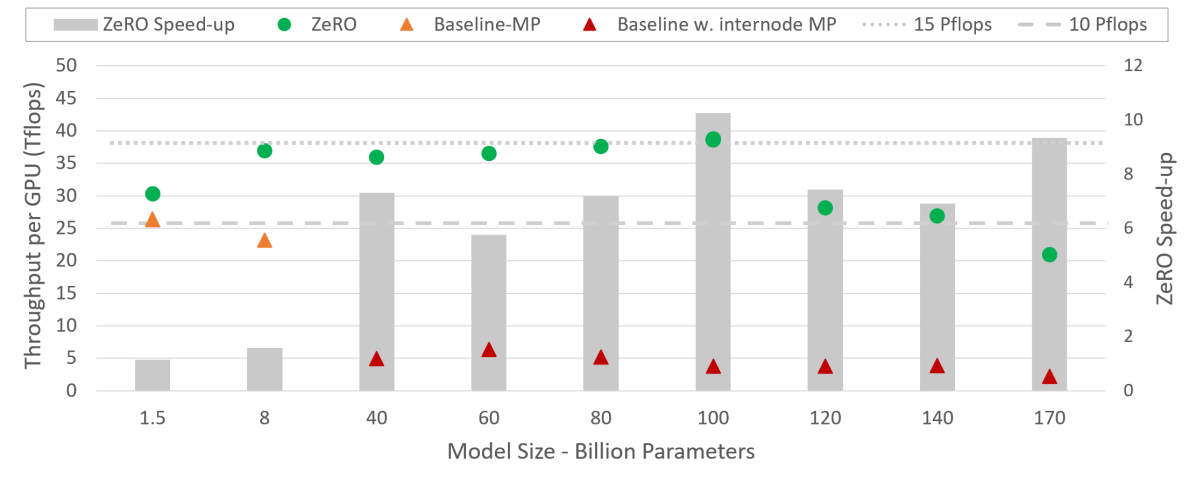
图源:ZeRO,Figure 2。原图展示 ZeRO 相比 baseline 的吞吐提升。本站读法是不要把它当“省显存等于更快”的通用结论,而要看省下的显存是否转成更大的 batch、更少 OOM 和更好的硬件利用。
ZeRO 的实验不是为了证明某个 NLP benchmark 准确率更高,而是证明在给定硬件下能训练更大的模型,并且保持可接受吞吐。系统论文里的核心证据通常是三类:最大可训练模型规模、吞吐/扩展效率、峰值显存。
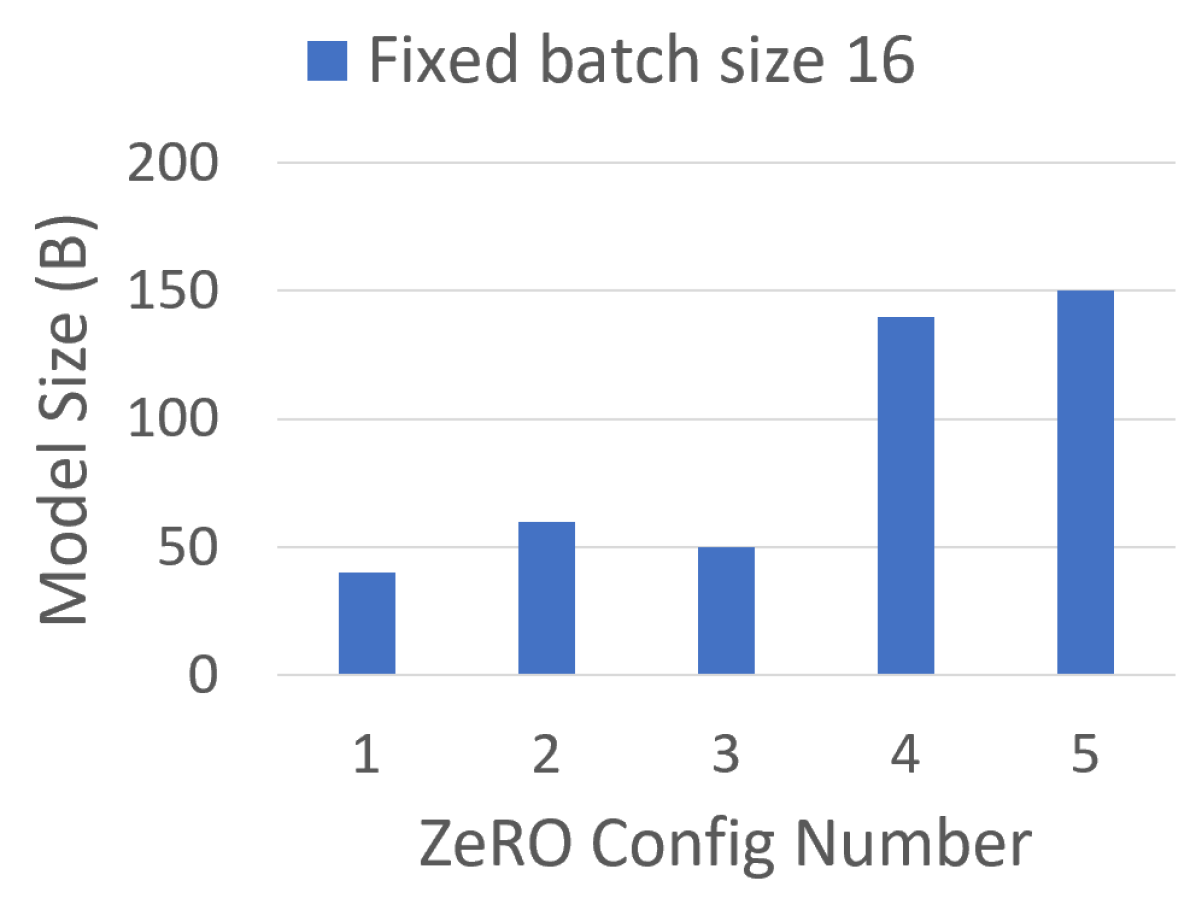
图源:ZeRO,Figure 6。原图比较不同设置下可训练的最大模型规模。本站读法是看“容量边界”如何随状态分片移动:ZeRO 的价值首先是把以前放不下的模型放进训练系统。
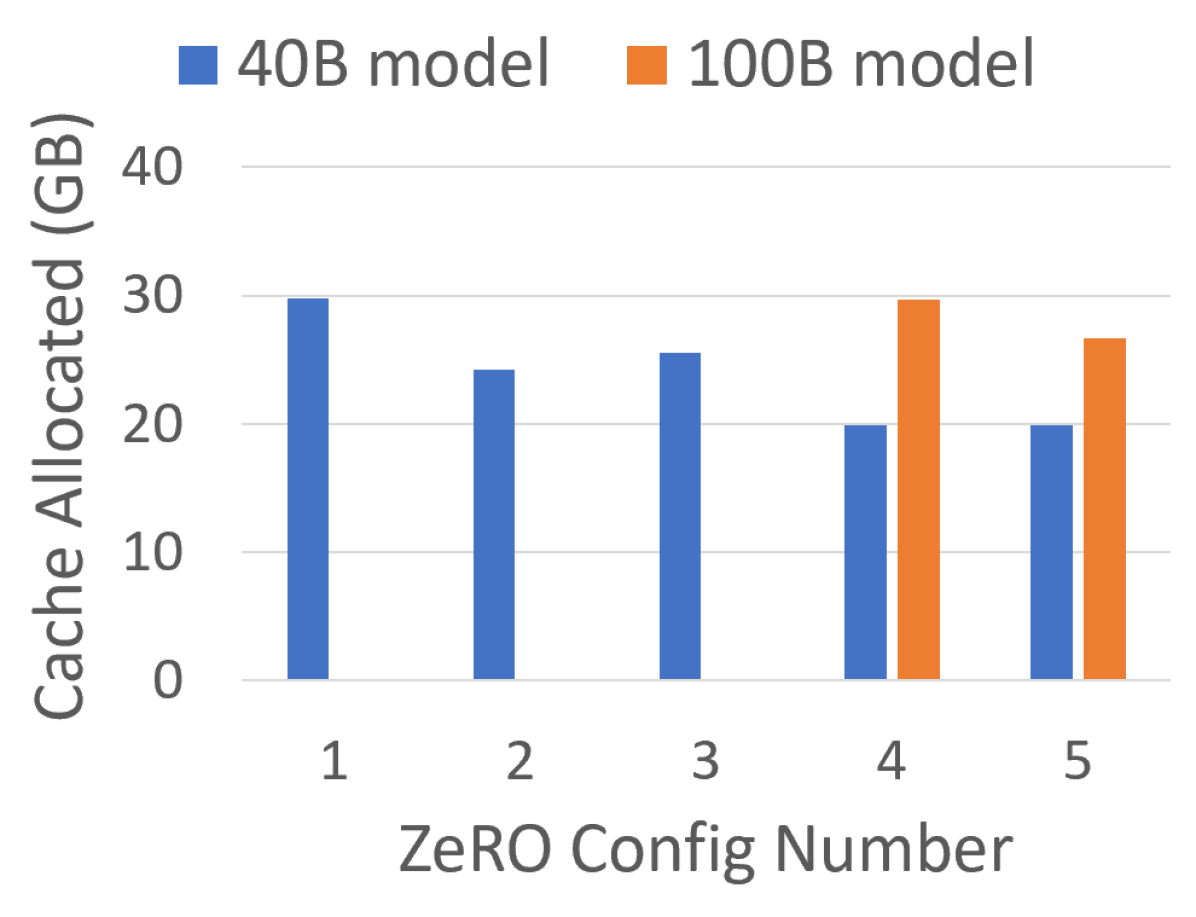
图源:ZeRO,Figure 7。原图展示最大显存分配变化。本站读法是把显存降低和上面的模型规模图连起来:只报省显存不够,还要说明省下的空间是否换来了更大模型、更大 batch 或更稳的训练。
读数边界。 ZeRO 的 throughput speedup 和 scaling efficiency 不能脱离当时的 V100/DGX-2H 集群、batch size、通信拓扑和模型并行组合来外推。它证明的是“减少状态冗余可以把显存转成更大模型或更好吞吐”,不是证明任意 ZeRO stage 在任意网络、任意序列长度下都会更快;但它提出的状态分片账本仍然是现代 DeepSpeed、FSDP 和大模型训练栈的核心语言。
ZeRO、FSDP、TP/PP 不是同一层工具
Megatron-style tensor parallelism 主要切单层计算:比如把 MLP GEMM、attention heads 或 vocab projection 分到多张 GPU。Pipeline parallelism 主要切层,把不同层放到不同 stage。ZeRO/FSDP 主要切 data-parallel 副本里的训练状态,减少每个 DP rank 保存的冗余。
这几个工具经常组合,但它们回答的问题不同:
| 主瓶颈 | 更直接的工具 |
|---|---|
| Adam states / gradients / parameter replica 放不下 | ZeRO / FSDP |
| 单层矩阵太大或单层计算要多卡协同 | Tensor parallelism |
| 层数太深、单卡放不下完整网络 | Pipeline parallelism |
| 长序列 activation 或 attention 成本爆炸 | Activation checkpointing、sequence/context parallel、FlashAttention |
| CPU/NVMe 总内存够但 GPU 不够 | ZeRO-Offload / ZeRO-Infinity,但要付带宽和延迟成本 |
FSDP 和 ZeRO-3 思想相近,都是 full sharding、按需 gather、用完释放,但生态气质不同:DeepSpeed 更像训练 runtime 和配置化系统,FSDP 更贴近 PyTorch 原生 module wrapping 与 state dict 生态。选择哪一个,不应只看“谁更省显存”,还要看模型改造、checkpoint、导出、调试和团队维护成本。
Stage 选择要从显存账本倒推
ZeRO 的三阶段经常被误读成“数字越大越先进”。更稳的做法是先拆 OOM 来源,再选最小够用的 stage。
| 场景 | 优先考虑 | 原因 |
|---|---|---|
| Adam states 占大头,参数和激活还放得下 | ZeRO-1 | 优化器状态最大,改动相对轻 |
| 梯度也占明显空间,通信拓扑支持 reduce-scatter | ZeRO-2 | optimizer + gradient shard 能进一步降低常驻显存 |
| 参数副本本身放不下,或需要更大模型 | ZeRO-3 / FSDP full shard | 参数按需 all-gather,容量收益最大 |
| 激活随 sequence length 爆炸 | checkpointing / sequence parallel / FlashAttention | ZeRO-DP 不直接解决 activation 主导的 OOM |
| GPU 总显存不足但 CPU/NVMe 空间足 | offload / ZeRO-Infinity | 用带宽和延迟换容量,训练吞吐要重新测 |
这个表的实用点是避免过度上 Stage 3。Stage 3 能省最多显存,但它把参数生命周期交给 runtime,容易让通信、checkpoint、debug 和导出复杂度上升。如果 ZeRO-1 已经让 batch 和模型装下,并且吞吐更稳,就没有必要为了“配置更高级”而上 Stage 3。
Checkpoint 和恢复是系统级证据
论文强调的是训练容量和吞吐,但在真实工程里,ZeRO 是否可用还取决于 checkpoint。普通 data parallel 保存一份完整参数和优化器状态;ZeRO sharding 后,参数、梯度和 optimizer states 分布在不同 ranks。保存时要决定:是保存分片 state,还是 gather 成完整 state dict;恢复时要决定:world size 变化能否重分片,optimizer states 能否对齐。
这会影响三个流程。
第一,故障恢复。大规模训练必然会遇到节点失败,如果 checkpoint 只在某些 rank 上不完整保存,恢复流程必须知道每个 shard 的来源和版本。第二,后训练和评测。SFT、RLHF、量化或推理导出通常需要完整权重,ZeRO-3/FSDP 训练产物要能可靠转换。第三,实验复现。切分策略、通信 bucket、offload、mixed precision 和 optimizer states 都会影响恢复后是否继续同一条训练曲线。
因此,ZeRO 页面的工程验收不应只写“显存降了”。还要补四项:能否从 checkpoint 恢复同一 world size;能否恢复到不同 world size;能否导出完整权重给推理;恢复后 loss 是否连续。缺其中一项,训练跑通也不等于系统可维护。
Offload 不是免费扩显存
ZeRO-Offload 和后续 ZeRO-Infinity 很容易让人兴奋:把 optimizer states、parameters 或 activations 放到 CPU/NVMe,看起来 GPU 显存立刻变大。但 offload 的本质是把容量瓶颈转成带宽和延迟瓶颈。每次 forward/backward 需要的参数和 optimizer update 需要的数据,都要在 PCIe、NVLink、CPU memory 或 NVMe 之间移动。
适合 offload 的情况通常是:模型太大,不 offload 根本不能跑;训练吞吐不是第一优先级;或者有足够好的 overlap,让数据搬运被计算遮住。不适合的情况是:模型本来能放下,只是想追求更高吞吐;网络或 PCIe 已经是瓶颈;step time 对延迟敏感;checkpoint 和恢复流程还没打通。
读 ZeRO 系列时可以把这当成一个统一原则:显存优化从来不是单目标优化。每省下一份常驻状态,都可能增加通信、重计算、调度或 I/O。系统论文的好处是把这笔账显式化,而不是让训练 OOM 变成玄学。
一个训练显存排查模板
把 ZeRO 用好,最好先写一张显存账,而不是先改配置。一个最小排查模板可以这样列:
| 项 | 估算方法 | 可能动作 |
|---|---|---|
| Parameters | 参数量 × dtype bytes | 模型切分、ZeRO-3、FSDP |
| Gradients | 参数量 × grad dtype bytes | ZeRO-2、gradient accumulation 调整 |
| Optimizer states | Adam 约 8-12 bytes / param,取决于 master weight | ZeRO-1、optimizer offload |
| Activations | batch × sequence × layers × hidden 相关 | activation checkpointing、sequence parallel |
| Temporary buffers | attention/GEMM/通信 workspace | kernel、bucket、allocator 调整 |
| Fragmentation | reserved 和 allocated 差距 | defragmentation、固定 buffer、重启进程验证 |
这个模板能解释一个常见现象:同样是 OOM,短序列大模型和长序列中模型的解法完全不同。前者可能被 optimizer states 和 parameter replica 卡住,ZeRO-1/2/3 很直接;后者可能被 activation 和 attention workspace 卡住,单纯上 ZeRO stage 只能缓一部分。
因此,ZeRO 的工程使用顺序应是:先用 profiler 或框架日志区分 allocated、reserved、optimizer、activation;再选最低复杂度的 stage;最后用吞吐和 checkpoint 恢复确认没有把问题转移到通信或 I/O。这个顺序比“直接复制别人 DeepSpeed config”更可靠。
为什么 ZeRO 仍然是现代训练栈的基础语言
今天很多团队直接使用 FSDP、DeepSpeed ZeRO、Megatron-DeepSpeed 或自研分布式训练框架,不一定手写 ZeRO 论文里的实现。但论文提出的“训练状态冗余”语言仍然是沟通基础:参数、梯度、优化器状态、激活、临时 buffer 到底谁被复制,谁被分片,谁被重算,谁被 offload。
这种语言能帮助团队避免把不同技术混在一起。Tensor parallel 解决单层计算切分,pipeline parallel 解决层切分,sequence parallel 解决序列维度激活和通信,ZeRO/FSDP 解决 data parallel 副本冗余。真正的大模型训练通常是这些工具叠加,调参时必须知道每一层工具在动哪一份内存和哪一段通信。
阅读结论
ZeRO 最值得带走的是一套显存账本,而不是一个配置名。普通 data parallel 浪费的是完整复制的 model states;mixed precision Adam 的常驻状态约 ;ZeRO-1/2/3 分别切 optimizer states、gradients 和 parameters;ZeRO-R 继续处理 activations、temporary buffers 和 fragmentation。
上线到真实训练栈时,先问五个问题:OOM 来自哪类显存?省下显存是否会被通信吃掉?checkpoint 是否能保存和恢复分片状态?导出到后训练/推理是否有明确格式?当前硬件拓扑是否支撑 Stage 3 的 all-gather 和 overlap?这些问题答清楚,ZeRO 才是训练系统设计,而不是一个救火开关。
外部精读
- ZeRO paper
- Microsoft Research: ZeRO publication page
- DeepSpeed ZeRO tutorial
- DeepSpeed ZeRO documentation
- PyTorch FSDP documentation
- Datawhale: VRAM Calculation and ZeRO
相关阅读与下一步
- 外部材料:论文标题 arXiv 检索。
- 外部材料:Semantic Scholar 标题检索。
- 外部材料:Papers with Code 检索。
- 站内下一步:论文精读专题。
- 站内下一步:论文专题写作规范。
- 站内下一步:外部精读来源台账。
- Title: 论文专题讲解:ZeRO:数据并行真正浪费的是训练状态副本
- Author: Charles
- Created at : 2025-10-17 09:00:00
- Updated at : 2025-10-17 09:00:00
- Link: https://charles2530.github.io/2025/10/17/ai-files-paper-deep-dives-foundations-zero/
- License: This work is licensed under CC BY-NC-SA 4.0.