
论文专题讲解:VGGT:一次前向推理恢复相机、深度、点云与轨迹
这页先按“论文证据节点”读:先问它解决哪一个瓶颈,再看核心图表、实验 setting 和不能外推的边界。背景概念先回 论文专题讲解 和 具身智能。
前置:不必先读完所有相关论文,但要知道本篇的输入、训练/推理路径和评测口径分别对应什么。
主线关系:读完后把结论回填到「具身智能」路线里,判断它改变的是机制、成本、数据配方、评测口径,还是仍停留在前沿假设。
- 论文:
VGGT: Visual Geometry Grounded Transformer - 系统:
VGGT - 链接:arXiv:2503.11651
- 项目页:vgg-t.github.io
- 代码与模型:facebookresearch/vggt
- 关键词:feed-forward 3D geometry、camera pose、depth map、point map、point tracking、DINOv2、DPT、alternating attention、multi-task learning
VGGT 放在具身智能专题里,是因为它把机器人视觉里几件经常分开的事接到同一个 feed-forward 模型里:相机参数、深度图、point map 和 3D point tracks。它不直接输出动作,但它能把多张 RGB 图像快速变成几何状态,为导航、抓取、视角规划、重建、VLA 状态编码和世界模型提供可消费的 3D 表示。
这篇论文的核心不是“再做一个 SfM / MVS 模块”,而是把传统上依赖匹配、几何优化、bundle adjustment 和任务专用后处理的视觉几何问题,改写成一个大 Transformer 的多任务监督问题。输入可以是一张、几张,甚至上百张图;输出一次前向给出 cameras、depth maps、point maps 和 tracking features。
它的效率贡献是什么
| 维度 | 贡献 |
|---|---|
| 节省的成本 | 不把相机位姿、深度、点云和 track 拆成多条优化管线;核心预测可在一次 feed-forward 中完成,10 frames 约 0.2s,100 frames backbone 约 3.12s |
| 核心机制 | DINOv2 patchify、camera/register tokens、Alternating-Attention、DPT dense heads、camera head、CoTracker-style tracking head、多任务 loss |
| 对具身主线的意义 | 给机器人提供快速 3D scene state:相机在哪里、每个像素多远、点云如何对齐、关键点在多帧中怎么对应 |
| 主要风险 | 仍是离线或准在线几何感知模块,不直接解决动作、接触动力学和安全控制;对 fisheye / panorama、极端旋转、大幅非刚体形变仍有限 |
| 应接到本站哪里 | 相机、深度与机器人视觉、Depth Anything 3、资产到轨迹:感知、抓取与数据管线 |
论文位置
传统视觉几何通常是“模块化 + 优化”:
1 | feature matching |
VGGT 反过来问:如果我们有足够多带 3D annotation 的数据,能不能让一个大模型直接学会这些互相关联的几何量?
它的回答是可以,而且不需要很强的手工 3D inductive bias。模型接收同一场景的 张 RGB 图像:
然后为每一帧输出:
其中 是 camera parameters, 是 depth map, 是 point map, 是用于 point tracking 的 dense feature grid。

图源:VGGT,Figure 1。原论文图意:VGGT 接收多张图像,一次前向预测 cameras、point maps、depth maps 和 tracks;图中展示了输入帧、重建点云、相机视锥、track 和 depth maps。
输入输出:输入是一组图像,输出是相机、深度、点云和轨迹等 3D 几何状态。
效率机制:用 feed-forward 几何模型减少传统 SfM/优化式重建的系统成本。
对主线意义:它是具身世界模型感知状态层的候选底座。
不能证明什么:几何一次前向不能证明物体动力学、风险规划或闭环控制。
总体架构
论文 Figure 2 可以看成 VGGT 的系统图。
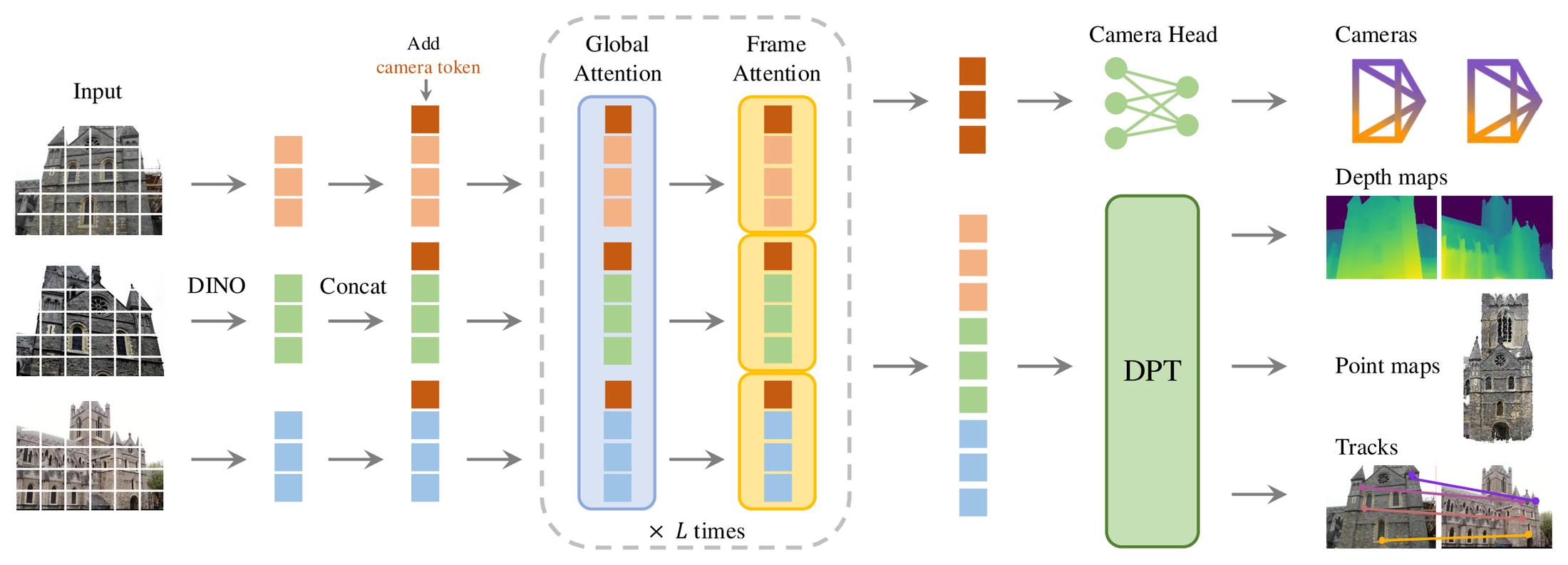
图源:VGGT,Architecture Overview。原论文图意:输入图像先经 DINO patchify 成 tokens,再加入 camera token,经过交替的 global attention 与 frame attention;camera head 输出相机,DPT head 输出 depth maps、point maps 和 tracking features。
左边每张图像先被 DINOv2 切成 image tokens。每一帧还会额外加入 camera token 和 register tokens。中间的核心不是 cross-attention,而是交替使用两种 self-attention:global self-attention 让不同视角交换信息,frame-wise self-attention 让每帧内部的结构和尺度更稳定。
右侧输出分成两类:camera token 进入 camera head,预测 extrinsics / intrinsics;image tokens 进入 DPT head,预测 dense depth、point map 和 tracking features。tracking 本身交给一个 CoTracker2-style head,用 VGGT 输出的 dense tracking features 做匹配。
输入和输出怎么定义
VGGT 预测的是一组 over-complete 3D attributes。它们之间有几何关系,但论文刻意让模型都显式预测,因为多任务训练能让表征更强。
| Output | Shape / Parametrization | Meaning |
|---|---|---|
| camera parameters | rotation quaternion、translation、field of view;principal point 默认在图像中心 | |
| depth map | 每个像素从第 个相机看到的 depth | |
| point map | 每个像素对应的 3D scene point | |
| tracking features | 给 tracking head 使用的 dense feature grid |
一个容易混的点是 coordinate frame。VGGT 像 DUSt3R 一样使用 viewpoint-invariant point maps: 里的 3D 点都表示在第一帧相机坐标系中。第一帧就是 world reference frame,因此第一帧 extrinsics 固定为 identity:
这对具身系统很重要。模型不是每张图各自输出一团局部点云,而是把所有帧的几何都拉回同一个参考坐标系,后续才能做点云融合、轨迹跟踪、视角规划或地图更新。
Alternating-Attention 为什么关键
如果所有 tokens 都做全局 self-attention,模型能跨视角交换信息,但计算和激活分布都更难稳定。如果只在每帧内部看,模型又缺少多视角几何关系。VGGT 的折中是 Alternating-Attention:
| Attention type | Scope | Role |
|---|---|---|
| frame-wise self-attention | tokens within each frame | 稳定单帧内部结构、局部几何和 per-frame activation |
| global self-attention | tokens across all frames | 建立跨视角匹配、相机关系、全局 scene geometry |
默认模型有 24 个 attention blocks,每个 block 包含 frame-wise 与 global attention。附录给了更具体的实现:
| Setting | Value |
|---|---|
| Feature dimension | 1024 |
| Attention heads | 16 |
| Attention implementation | torch.nn.MultiheadAttention with flash attention |
| Stabilization | QKNorm, LayerScale |
| LayerScale init | 0.01 |
| Tokenizer | DINOv2 + positional embedding |
| Dense head features | DINO/DPT features from blocks 4, 11, 17, 23 |
| Total parameters | approximately 1.2B |
Table 8 is redrawn below with the original English fields.
| ETH3D Dataset | Acc. | Comp. | Overall |
|---|---|---|---|
| Cross-Attention | 1.287 | 0.835 | 1.061 |
| Global Self-Attention Only | 1.032 | 0.621 | 0.827 |
| Alternating-Attention | 0.901 | 0.518 | 0.709 |
表源:VGGT,Table 8。原论文表格要点:在 ETH3D point map estimation 上,Alternating-Attention 明显优于 Cross-Attention 和只用 Global Self-Attention 的变体。
这张表说明 VGGT 不是单纯“堆大 Transformer”。跨帧全局建模必须和单帧内部归一、结构整理交替发生,几何预测才稳。
Prediction Heads
VGGT 的 heads 分得很明确。
Camera head
每帧都有 camera token。camera head 读取输出 camera tokens,经过 4 个额外 self-attention layers 和一个 linear layer,预测 。
第一帧使用不同的 learnable camera/register tokens,让模型知道“这一帧是 reference frame”。其他帧使用另一套 learnable tokens。这样既保留 permutation equivariance,又能固定世界坐标。
Dense DPT heads
输出 image tokens 进入 DPT layer,转成 dense feature maps ,再用 convolution 输出:
- depth maps ;
- point maps ;
- tracking features ;
- depth / point-map uncertainty maps 。
uncertainty maps 不只是可视化 confidence,它们直接进入训练 loss,用于 aleatoric-uncertainty weighting。
Tracking head
VGGT 的 transformer 不直接输出最终 tracks,而是输出 dense tracking features 。tracking head 使用 CoTracker2 architecture:给定 query point,先在 query frame 的 feature map 上 bilinear sampling,再和其他帧 feature maps 做 correlation,最后通过 self-attention layers 输出对应点。它不假设输入帧有时间顺序,因此不仅可用于视频,也可用于无序图像集合。

图源:VGGT,Additional Visualizations of Point Map Estimation。原论文图意:VGGT 在不同输入帧数和不同场景上预测 point maps,并用 camera frustums 展示估计相机位姿。
训练目标
VGGT 是端到端多任务训练。总 loss 是:
论文发现 camera、depth、point-map 三个 loss 的范围相近,不需要相互加权;tracking loss 权重设为:
| Loss | Supervision | Detail |
|---|---|---|
| camera parameters | Huber loss on predicted and GT | |
| depth maps | aleatoric-uncertainty weighted depth residual + gradient term | |
| point maps | analogous uncertainty weighted point residual + gradient term | |
| keypoint correspondences | 2D point distance across frames + visibility BCE |
depth loss 不是只比较深度值,还加了 gradient-based term:
point map loss 同理:
这个设计和 Depth Anything V2 的 gradient matching 思路有点呼应:如果只学数值,不学局部梯度,深度和点云边界会更容易糊;但 VGGT 这里还把 uncertainty 学进来,让模型能表达哪些位置更不可靠。
Ground Truth Coordinate Normalization
3D 重建天然有尺度和坐标系歧义。同一组图像可以对应无数个整体平移、旋转、缩放后的 3D 解。VGGT 的做法是:
- 所有 GT quantities 先表达在第一帧相机坐标系;
- 计算 point map 里所有 3D points 到原点的平均欧氏距离;
- 用这个 scale 归一化 camera translations、point maps 和 depth maps;
- 不对模型输出做同样的显式归一化,而是让模型从训练数据中学习这个规范。
论文特别提到,像 DUSt3R 那样也对 network predictions 做 normalization 并不是必要条件,反而可能引入训练不稳定。
训练配方
VGGT 的训练细节值得单独拎出来,因为它的能力很大程度来自多数据、多任务和大模型训练的组合。
| Setting | Value |
|---|---|
| Optimizer | AdamW |
| Iterations | 160K |
| LR schedule | cosine |
| Peak LR | 0.0002 |
| Warmup | 8K iterations |
| Frames per scene | 2-24 |
| Total frames per batch | 48 |
| Image / depth / point resize | longer side 518 pixels |
| Crop | shorter dimension 168-518 pixels, multiple of 14, around principal point |
| Augmentation | aggressive color augmentation per frame, color jittering, Gaussian blur, grayscale |
| Precision | bfloat16 |
| Memory saving | gradient checkpointing |
| Gradient clipping | norm 1.0 |
| Hardware | 64 A100 GPUs |
| Training time | 9 days |
训练 batch 的构造是:先随机选一个 training dataset,再从其中均匀采样一个 scene。每个 dataset 的权重大致相近但不完全相同,接近 DUSt3R 的做法。训练时排除少于 24 frames 的 sequences。
track supervision 不是凭空来的。论文用 depth maps unproject 到 3D,再 reproject 到目标帧,只保留 reprojected depths 和 target depth maps 一致的 correspondences。和 query frame 相似度太低的帧会从 batch sampling 排除;如果极少数情况下没有 valid correspondences,则跳过 tracking loss。
训练数据
论文没有给出逐项数据规模表,但列出了训练数据来源,覆盖真实室内、户外、合成、视频、object-centric 和 egocentric / digital twin 等场景。
| Dataset / Source | Role in VGGT training |
|---|---|
| Co3Dv2 | object-centric multi-view scenes |
| BlendMVS | multi-view stereo scenes |
| DL3DV | large-scale dynamic / real-world 3D scenes |
| MegaDepth | internet photo tourism / SfM geometry |
| Kubric | synthetic scenes and tracks |
| WildRGB | RGB-D / wild scene supervision |
| ScanNet | indoor RGB-D scenes |
| HyperSim | synthetic indoor scenes |
| Mapillary | street-level outdoor imagery |
| Habitat | simulated embodied environments |
| Replica | indoor 3D reconstruction scenes |
| MVS-Synth | synthetic multi-view stereo |
| PointOdyssey | long-range point tracking / dynamic scenes |
| Virtual KITTI | synthetic driving scenes |
| Aria Synthetic Environments | egocentric synthetic environments |
| Aria Digital Twin | egocentric digital twin data |
| synthetic artist-created assets similar to Objaverse | object / asset-centric synthetic 3D supervision |
这些数据的 3D annotations 来自 direct sensor capture、synthetic engines 或 SfM。对具身系统来说,这很关键:模型不是只在 phototourism 上学 camera,也不是只在 RGB-D 室内学 depth,而是把多个几何任务和多种数据来源统一到同一个训练接口里。
Multi-task 为什么有用
VGGT 的一个关键判断是:即使 camera、depth、point map 之间可以通过几何公式互相推导,也应该在训练时都显式预测。因为这些任务提供的梯度不同,会共同塑造更好的 scene representation。
Table 9 is redrawn below with the original English fields.
| w. | w. | w. | Acc. | Comp. | Overall |
|---|---|---|---|---|---|
| ✗ | ✓ | ✓ | 1.042 | 0.627 | 0.834 |
| ✓ | ✗ | ✓ | 0.920 | 0.534 | 0.727 |
| ✓ | ✓ | ✗ | 0.976 | 0.603 | 0.790 |
| ✓ | ✓ | ✓ | 0.901 | 0.518 | 0.709 |
表源:VGGT,Table 9。原论文表格要点:camera、depth、track 同时训练时,ETH3D point map estimation 最好;去掉任一任务都会伤害最终 point map accuracy。
这张表可以直接类比机器人多任务感知。相机、深度、点云和 correspondence 不应该被看作互不相干的 head;它们是同一个 3D scene belief 的不同投影。
核心结果
Camera pose
Table 1 is redrawn below with the original English fields.
| Methods | Re10K (unseen) AUC@30 | CO3Dv2 AUC@30 | Time |
|---|---|---|---|
| Colmap+SPSG | 45.2 | 25.3 | ~15s |
| PixSfM | 49.4 | 30.1 | >20s |
| PoseDiff | 48.0 | 66.5 | ~7s |
| DUSt3R | 67.7 | 76.7 | ~7s |
| MASt3R | 76.4 | 81.8 | ~9s |
| VGGSfM v2 | 78.9 | 83.4 | ~10s |
| MV-DUSt3R | 71.3 | 69.5 | ~0.6s |
| CUT3R | 75.3 | 82.8 | ~0.6s |
| FLARE | 78.8 | 83.3 | ~0.5s |
| Fast3R | 72.7 | 82.5 | ~0.2s |
| Ours (Feed-Forward) | 85.3 | 88.2 | ~0.2s |
| Ours (with BA) | 93.5 | 91.8 | ~1.8s |
表源:VGGT,Table 1。原论文表格要点:在 10 random frames 的 camera pose estimation 上,VGGT feed-forward 已经强于多种优化型或并发 feed-forward 方法;加 BA 后精度继续上升但仍明显快于传统 pipeline。
注意这里 Re10K 是 unseen。VGGT 没在 RealEstate10K 上训练,却在这个测试上有明显优势,这说明它学到的不是某个 dataset 的 camera 模板,而是更通用的多视角几何表征。
Dense MVS
Table 2 is redrawn below with the original English fields.
| Known GT camera | Method | Acc. | Comp. | Overall |
|---|---|---|---|---|
| ✓ | Gipuma | 0.283 | 0.873 | 0.578 |
| ✓ | MVSNet | 0.396 | 0.527 | 0.462 |
| ✓ | CIDER | 0.417 | 0.437 | 0.427 |
| ✓ | PatchmatchNet | 0.427 | 0.377 | 0.417 |
| ✓ | MASt3R | 0.403 | 0.344 | 0.374 |
| ✓ | GeoMVSNet | 0.331 | 0.259 | 0.295 |
| ✗ | DUSt3R | 2.677 | 0.805 | 1.741 |
| ✗ | Ours | 0.389 | 0.374 | 0.382 |
表源:VGGT,Table 2。原论文表格要点:在 DTU Dense MVS 上,VGGT 不使用 GT camera,仍大幅超过同样无 GT camera 的 DUSt3R,并接近部分使用 GT camera 的 MVS 方法。
Point map
Table 3 is redrawn below with the original English fields.
| Methods | Acc. | Comp. | Overall | Time |
|---|---|---|---|---|
| DUSt3R | 1.167 | 0.842 | 1.005 | ~7s |
| MASt3R | 0.968 | 0.684 | 0.826 | ~9s |
| Ours (Point) | 0.901 | 0.518 | 0.709 | ~0.2s |
| Ours (Depth + Cam) | 0.873 | 0.482 | 0.677 | ~0.2s |
表源:VGGT,Table 3。原论文表格要点:在 ETH3D point map estimation 上,VGGT feed-forward 速度远快于 DUSt3R / MASt3R;并且用 depth + camera 构造点云比直接 point map head 更准。
这个结果很有意思。虽然 VGGT 训练时显式预测 point map,但推理时组合 independent depth maps 和 camera parameters 反而更准。这也解释了为什么 over-complete outputs 有价值:不同 head 可以互相校验,工程上也可以选更可靠的组合。
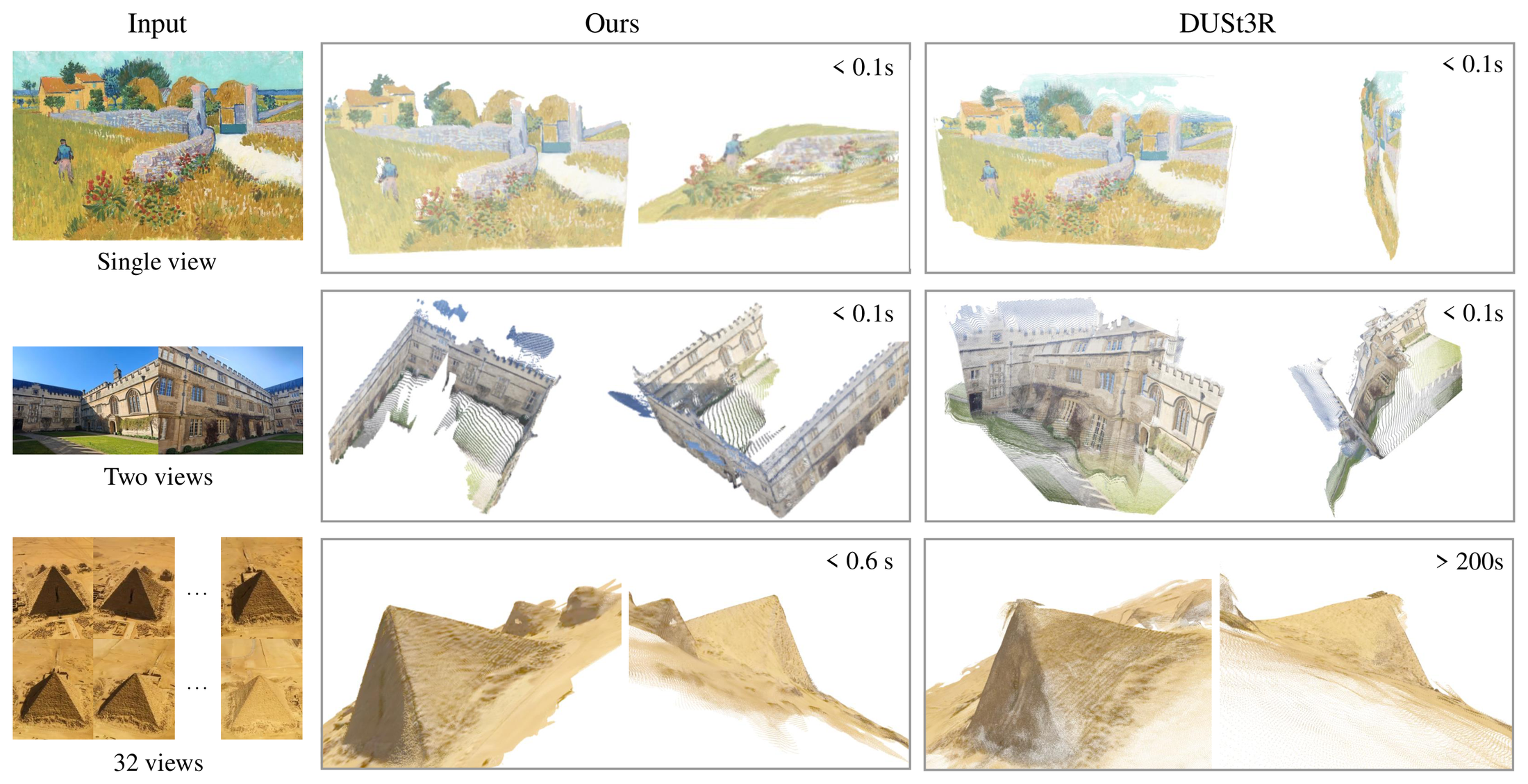
图源:VGGT,Qualitative comparison figure。原论文图意:VGGT 在 in-the-wild images 上比 DUSt3R 更稳,包括油画平面、无重叠双图场景和重复纹理场景;DUSt3R 在超过 32 frames 时还会出现内存限制。
Runtime and memory
Table 7 is redrawn below with the original English fields.
| Input Frames | 1 | 2 | 4 | 8 | 10 | 20 | 50 | 100 | 200 |
|---|---|---|---|---|---|---|---|---|---|
| Time (s) | 0.04 | 0.05 | 0.07 | 0.11 | 0.14 | 0.31 | 1.04 | 3.12 | 8.75 |
| Mem. (GB) | 1.88 | 2.07 | 2.45 | 3.23 | 3.63 | 5.58 | 11.41 | 21.15 | 40.63 |
表源:VGGT,Runtime and peak GPU memory usage table。原论文表格要点:在单张 H100、336 x 518 图像分辨率下,backbone 可处理从 1 到 200 frames 的输入;frame 数越大,global attention 使显存增长明显。
论文还补充:camera head 很轻,通常只占 feature backbone runtime 约 5%、GPU memory 约 2%;每个 DPT head 平均每帧约 0.03s 和 0.2GB。也就是说,真正的大头是跨帧 feature backbone。
下游:VGGT 作为 feature backbone
VGGT 不只作为几何预测器,还能作为下游任务的 feature backbone。
在 dynamic point tracking 上,论文把 CoTracker2 的 backbone 替换为 VGGT 的 pretrained feature backbone,然后在 Kubric 上 fine-tune 整个 tracker。结果显示 TAP-Vid 上有明显提升。
| Method | Kinetics AJ | Kinetics | Kinetics OA | RGB-S AJ | RGB-S | RGB-S OA | DAVIS AJ | DAVIS | DAVIS OA |
|---|---|---|---|---|---|---|---|---|---|
| TAPTR | 49.0 | 64.4 | 85.2 | 60.8 | 76.2 | 87.0 | 63.0 | 76.1 | 91.1 |
| LocoTrack | 52.9 | 66.8 | 85.3 | 69.7 | 83.2 | 89.5 | 62.9 | 75.3 | 87.2 |
| BootsTAPIR | 54.6 | 68.4 | 86.5 | 70.8 | 83.0 | 89.9 | 61.4 | 73.6 | 88.7 |
| CoTracker | 49.6 | 64.3 | 83.3 | 67.4 | 78.9 | 85.2 | 61.8 | 76.1 | 88.3 |
| CoTracker + Ours | 57.2 | 69.0 | 88.9 | 72.1 | 84.0 | 91.6 | 64.7 | 77.5 | 91.4 |
表源:VGGT,Dynamic Point Tracking Results on TAP-Vid。原论文表格要点:用 VGGT pretrained features 替换 CoTracker backbone 后,Kinetics、RGB-S、DAVIS 三个 benchmark 上多项指标达到最好。

图源:VGGT,Visualization of Rigid and Dynamic Point Tracking。原论文图意:上半部分展示 VGGT tracking module 在无序静态图像集合中输出 keypoint tracks;下半部分展示用 VGGT backbone 增强动态点跟踪器。
和 DA3、DUSt3R、MASt3R 的关系
VGGT 很容易和 Depth Anything 3 放在一起读,但两者的哲学不同。
| Dimension | VGGT | DA3 |
|---|---|---|
| Main target | cameras + depth maps + point maps + 3D point tracks | depth + ray + optional camera / 3D fusion |
| Architecture style | large feed-forward transformer with over-complete heads | single pretrained DINOv2 backbone + cross-view attention + Dual-DPT |
| Training emphasis | multi-task 3D attributes and tracking features | depth-ray representation and teacher-student depth supervision |
| Strength | direct all-in-one 3D attributes, fast geometry pipeline replacement | depth/ray target更简洁,强调任意视角 visual space 和可融合几何 |
| Risk | 多 head 输出之间可能需要工程选择和一致性检查 | 不直接覆盖 VGGT 那种 point tracking / over-complete heads |
DUSt3R / MASt3R 则是 VGGT 的直接前置线。它们证明 point maps 是很强的中间表示,但常需要 pairwise processing、global alignment 或更重的后处理。VGGT 的突破点是把多视角集合直接放进一个 Transformer,通过 global attention 一次处理多帧,尽量减少测试时优化。
具身系统里怎么用
在机器人里,VGGT 最适合作为“快速几何状态生成器”。
| 用法 | 推荐程度 | 原因 |
|---|---|---|
| 多视角相机/视频转点云和粗地图 | 高 | 一次前向得到 camera + depth / point maps,可作为 SLAM / reconstruction / planner 的 warm start |
| VLA / 世界模型前的 3D state encoder | 高 | 把 RGB history 转成 camera、depth、track 和点云,减少纯像素表征的几何盲点 |
| 视角规划和主动感知 | 中高 | camera pose 与 point map 能帮助判断哪里没看见、哪里遮挡、下一视角应去哪 |
| 抓取前几何预处理 | 中 | 可提供物体粗 3D 形状和深度,但抓取还要结合尺度校准、接触模型和夹爪约束 |
| 安全距离、碰撞制动 | 低 | 这类闭环仍需要可靠标定、实时传感器和安全冗余,不能只信 feed-forward 几何 |
一句话总结:VGGT 把“看多张图恢复 3D”这件事从传统优化管线变成了大模型前向推理问题。对具身智能来说,它的价值不是替代控制器,而是把相机、深度、点和 track 变成一个更快、更统一的感知接口。
- 回到论文总入口:论文专题讲解,用同一套 claim / 图表 / 边界口径横向比较。
- 把本篇结论接回主题:具身智能。
- 按导航顺序继续:Depth Anything 3:3D 几何底座。
参考资料
- Title: 论文专题讲解:VGGT:一次前向推理恢复相机、深度、点云与轨迹
- Author: Charles
- Created at : 2025-10-18 09:00:00
- Updated at : 2025-10-18 09:00:00
- Link: https://charles2530.github.io/2025/10/18/ai-files-paper-deep-dives-embodied-ai-vggt/
- License: This work is licensed under CC BY-NC-SA 4.0.