
量化:QLoRA:低显存微调,不是把模型“训练成 4bit”
QLoRA 很容易被一句话误导:用 4bit 训练大模型。更准确的说法是:冻结的底座模型用 4bit 存储,训练时只更新一小组 LoRA adapter;梯度穿过量化底座流向 adapter,但底座权重本身不做全量更新。
这篇只回答一个问题:QLoRA 为什么能显著省显存,同时又和 PTQ、QAT、全量低比特训练不是一回事?
先把显存账拆开
全量微调最贵的不是模型文件本身,而是训练状态。一个可训练参数通常还会带来梯度、optimizer state、激活保存和通信开销。LoRA 先把“可训练参数”缩小;QLoRA 再把“冻结底座的常驻存储”压低。
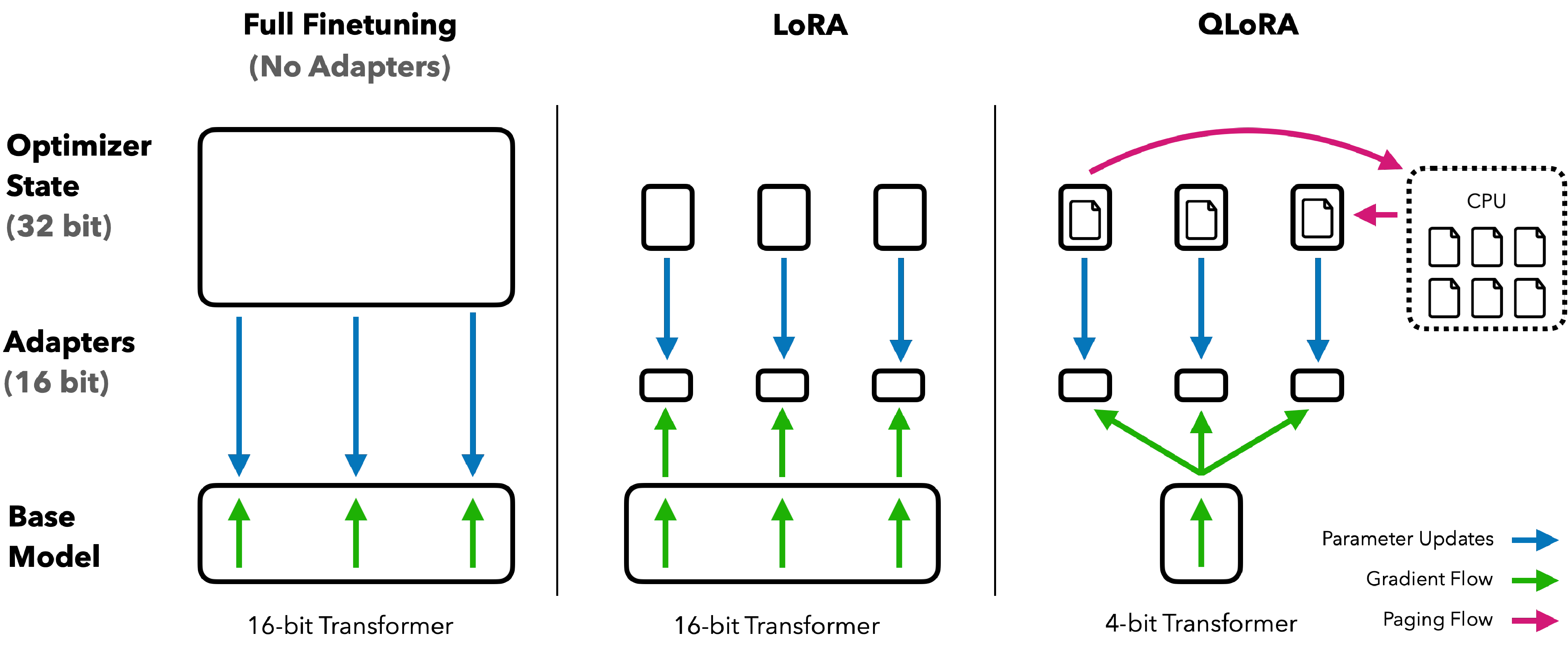
图源:QLoRA: Efficient Finetuning of Quantized LLMs,Figure 1。原图表达:对比 32-bit/16-bit 全量微调、LoRA 与 QLoRA 的显存组织;QLoRA 将冻结底座量化存储,只训练 adapter,并用 paged optimizer 缓解峰值。本站读法:看哪些参数“会训练”,哪些只是“低比特常驻”。
这张图最关键的不是 4bit 标签,而是 optimizer 主要服务少量 adapter。底座模型仍参与前向和反向的计算图,但它是冻结的;训练压力最终落到 LoRA 矩阵上。
LoRA 先解决“更新太大”的问题
全量微调会直接更新某个权重矩阵 。LoRA 假设下游任务需要的变化可以用低秩增量表示:
其中:
这里 ,, 是 rank。读这两行公式时,重点是 不再是完整大矩阵,而是两个小矩阵相乘得到的低秩更新。
如果 ,全量矩阵约有 个参数。若 ,LoRA 只有 个参数。参数少了,梯度和 optimizer state 也跟着少,这就是 LoRA 的第一层节省。
实际实现常写成:
是缩放因子。rank 决定 adapter 能表达多复杂的变化, 决定这份变化打到原模型上的强度。rank 太小会学不动复杂任务,rank 太大又会增加显存、过拟合和多 adapter 服务成本。
QLoRA 再解决“冻结底座太占显存”的问题
QLoRA 在 LoRA 之上做了一步:把冻结底座量化存储。
训练时的有效权重可以理解成:
这里 是量化后的冻结底座, 是可训练 adapter。读这行式子时要分清两件事:底座低比特是为了省常驻显存;adapter 仍用较高精度训练,以学习任务变化。
很多实现会在计算时把 4bit 权重反量化到 BF16/FP16 参与 matmul。也就是说,QLoRA 不等于所有运算都在 4bit 上完成。它主要省的是冻结底座的存储和全量 optimizer 状态,而不是保证每个 kernel 都是低比特训练 kernel。
NF4、double quantization、paged optimizer 各自解决什么
QLoRA 论文的三个关键词常被混在一起,其实它们管不同的显存账。
| 组件 | 解决的问题 | 直觉 |
|---|---|---|
| NF4 | 4bit 格式怎样更适合近似正态的权重分布 | 给常见权重值更多有效刻度 |
| Double quantization | scale 等量化常数也占空间 | 再压缩量化元数据 |
| Paged optimizer | 长序列或大 batch 会产生显存峰值 | 让 optimizer state 峰值更平滑 |
NF4 的意义在于:权重分布通常不是均匀铺满整数范围,而是大量集中在 0 附近。普通 INT4 的格子未必最适合这种分布;NF4 用更适合正态权重的码本来减少表示损失。Double quantization 则提醒你,量化不只存低比特权重,还要存 scale/zero 等元数据;模型越大,元数据也值得压缩。
QLoRA、PTQ、QAT 的边界
| 方法 | 主要目的 | 训练什么 | 典型风险 |
|---|---|---|---|
| PTQ / GPTQ / AWQ | 训练后压缩部署 | 通常不训练原模型 | 任务掉点、校准集不代表线上、kernel 不支持 |
| QLoRA | 低显存微调 | 冻结量化底座,只训练 adapter | adapter 容量不足、量化底座已受损、数据质量差 |
| QAT | 让模型训练时适应量化误差 | 训练全模型或部分模块 | 成本高、稳定性难、流程复杂 |
| 全量低比特训练 | 从训练过程就使用低精度数值系统 | 大量参数和状态 | 数值范围、scale、梯度稳定、kernel 长跑可靠性 |
QLoRA 解决的是“我显存不够,但想微调”。PTQ 解决的是“我模型训好了,想部署更省”。QAT 解决的是“我希望模型在训练中适应量化误差”。这三者可以组合,但不能互相替代。
为什么量化底座后 adapter 仍能学
QLoRA 能工作的前提有四个。
| 前提 | 含义 |
|---|---|
| 量化没有摧毁底座能力 | 4bit 近似仍保留模型的大部分语义和推理能力 |
| 下游变化可低秩表达 | 任务主要是风格、格式、领域知识表达或轻量对齐 |
| adapter 插入位置覆盖关键路径 | attention、MLP、projector 或 head 选得合理 |
| compute dtype 保护关键计算 | 训练计算不完全被 4bit 噪声支配 |
如果任务只是企业术语、文档抽取、客服风格、代码 API 适配,QLoRA 往往够用。如果任务要求模型学会全新的跨模态结构、动作控制、复杂长程规划,adapter 可能不够,量化底座误差也可能被放大。
target modules 是真正的工程开关
LoRA adapter 插在哪里,决定它能改哪些能力。
| 目标模块 | 它影响什么 | 什么时候重要 |
|---|---|---|
q_proj/k_proj/v_proj/o_proj |
attention 读写和信息混合 | 语言、代码、长上下文常见 |
up_proj/down_proj/gate_proj |
MLP 变换和非线性特征 | 风格、领域表达、复杂任务常见 |
| embedding / lm head | 词表和输出分布 | 新词、结构化输出、特殊 token |
| multimodal projector | 视觉/音频到语言空间对齐 | VLM、OCR、图表理解 |
| action / risk head | 动作分布和安全判断 | VLA、机器人、控制任务 |
target modules 选得太少,adapter 学不动;选得太多,显存、过拟合和服务端 adapter 管理成本上升。多模态和 VLA 场景尤其要小心:只给语言层打 LoRA,可能修不好视觉 connector 或动作头的问题。
一个训练决策例子
假设要把 7B 通用模型适配到医疗文档问答。
第一步不要直接拉高 rank,而是先确认 4bit 底座在医疗验证集上没有明显基础掉点。如果量化后原模型已经把术语、小数、长病历摘要搞坏,adapter 要先补量化损伤,再学新任务,训练会很吃力。
第二步选择 target modules。普通问答可以先覆盖 attention 和 MLP;如果任务包含 OCR 表格或多模态病历,要检查 projector 和视觉相关层是否也需要 adapter 或更高精度。
第三步记录并分桶评测:通用问答、医疗术语、拒答安全、长病历摘要、字段级抽取、药品剂量、小数点和跨页引用。QLoRA 训练 loss 下降,不代表高风险字段就安全。
第四步明确部署形态。线上是加载 4bit base + adapter,还是 merge adapter 后再量化?runtime 是否支持对应量化格式、adapter 并发、KV cache 和 batch 合并?训练省显存,不自动等于部署省延迟。
外部精读
- QLoRA 论文:理解 NF4、double quantization 和 paged optimizer。
- LoRA 论文:理解低秩适配为什么能减少可训练参数。
- Hugging Face Quantization Concepts:部署量化概念和方法边界。
- bitsandbytes 文档:QLoRA 常用实现路径和配置入口。
读完以后怎么判断
QLoRA 的核心不是“4bit 训练”,而是“4bit 冻结底座 + 高效 adapter 训练”。LoRA 先减少可训练更新的维度,QLoRA 再压低底座常驻显存,NF4/double quant/paged optimizer 分别处理权重格式、元数据和峰值显存。判断 QLoRA 是否适合一个任务,不要只看能否跑起来,而要看量化底座是否还可靠、adapter 是否覆盖关键模块、数据是否足够干净,以及部署 runtime 是否真的支持目标形态。
相关阅读与下一步
- 外部材料:Hugging Face Quantization 概念指南。
- 外部材料:GPTQ 论文。
- 外部材料:AWQ 论文。
- 站内下一步:量化专题。
- 站内下一步:PTQ / GPTQ / AWQ / SmoothQuant。
- 站内下一步:量化评测与部署清单。
- Title: 量化:QLoRA:低显存微调,不是把模型“训练成 4bit”
- Author: Charles
- Created at : 2025-12-17 09:00:00
- Updated at : 2025-12-17 09:00:00
- Link: https://charles2530.github.io/2025/12/17/ai-files-quantization-qlora-and-quantized-training/
- License: This work is licensed under CC BY-NC-SA 4.0.