
量化:PTQ、GPTQ、AWQ 与 SmoothQuant
量化的目标不是“把模型数字变小”这么简单,而是在尽量不损坏输出质量的前提下,把权重和激活压到更低比特,从而降低显存占用、带宽压力、推理成本和部署门槛。
这一页主要讲后训练量化路线,也就是模型已经训练完,不想再做昂贵重训时,如何尽量稳地压缩。
量化不是把所有数字粗暴变小,而是把误差放到模型不敏感的位置。真正要看的是输出是否还稳定、runtime 是否真的加速、长尾任务是否没有明显退化。
如果把城市地图压缩成低清版,公园草坪少几条纹理没关系,但医院入口、桥、地铁站位置不能错。量化也是这样:有些权重可以粗一点,有些通道和层必须保护。
1. 量化的统一形式
最基本的线性量化可写成:
反量化为:
其中 是 scale, 是 zero-point, 由 bit 数决定。
若使用对称量化,通常 。
若是 4bit 对称量化,整数范围常为:
2. 真正的问题不是量化权重,而是量化后的乘法是否还“像原来”
对一个线性层:
量化后变成:
我们真正想控制的是输出误差:
如果只看单个权重误差 ,可能会误导。
因为某个权重虽误差大,但若它对应的输入激活几乎总是很小,对最终输出未必有大影响。
这也是为什么现代量化方法越来越关注激活分布、通道敏感性、Hessian 或二阶近似,以及校准集上的真实输出误差。
3. PTQ 的核心矛盾
后训练量化的基本约束是不能重新做大规模训练、最多只能用一小批校准数据,同时还希望尽量不掉点。
于是问题可写成:
这里 很小,因此所有方法都在想办法:
如何用极少数据,尽可能估计“哪些权重或通道最不能乱动”。
一个直观例子:客服模型上线
假设你有个 13B 客服模型,原本在 FP16 下答复质量稳定。
你把它压成 4bit 后,如果没有校准,常见闲聊可能仍然正常,但一到长表格、时间线推理、法律条款抽取就开始乱。
原因常常不是“模型整体坏了”,而是少数关键层在校准不足时被量化得太狠。
4. PTQ 的几个基本设计点
4.1 权重量化还是激活量化
W-only 量化只量化权重,部署简单,质量通常更稳;W+A 量化同时量化激活,硬件收益更大,但更容易掉点。
对 LLM 来说,很多实际方案先上权重量化,因为权重静态、容易离线处理,而激活动态变化大、更难稳定。
4.2 Per-tensor、Per-channel、Per-group
如果整块矩阵只用一个 scale,简单但粗糙。
更细的方案是每通道一个 scale,或每组若干列一个 scale。
量化单元越细,精度通常越好,但元数据和 kernel 实现更复杂。
4.3 校准集该怎么选
校准集最好能覆盖真实部署分布。
例如代码模型的校准集若全是短自然语言,量化后往往在真实代码任务上掉得更厉害。
5. GPTQ:用二阶近似做“误差补偿”
GPTQ 的核心思想是:
量化某一列权重后,不是简单接受误差,而是尽量把误差往后续尚未量化的参数中吸收。
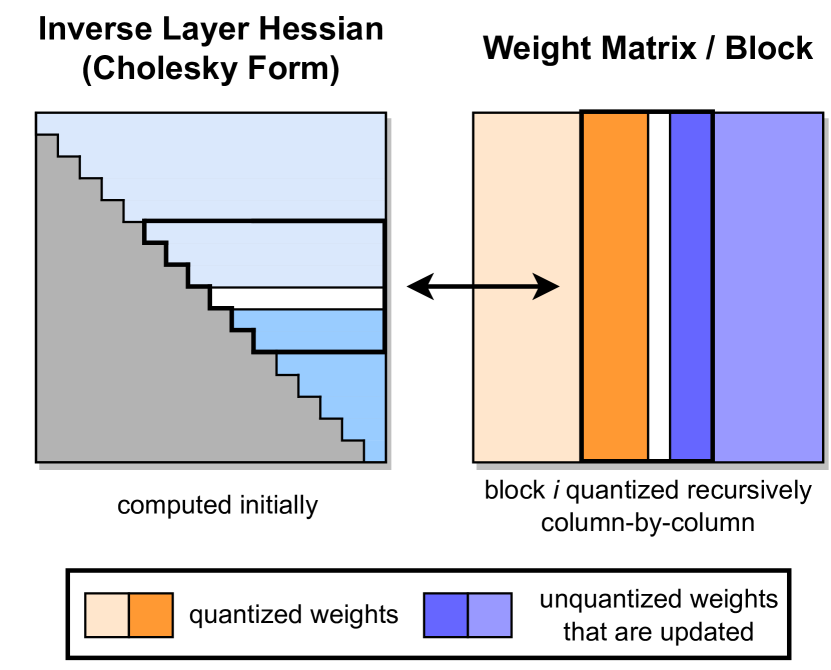
图源:GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers,Figure 2。原论文图意:左侧是层内 inverse Hessian 的 Cholesky 形式,右侧是按列递归量化的权重块;已量化列固定,未量化列会根据量化误差被更新补偿。
如果某个方向的输出对权重扰动非常敏感,那么那里的量化误差就更贵。GPTQ 用校准数据估计层内二阶信息,并在按列量化时把误差分摊给还没量化的列。可以把它理解成“不是每列各压各的”,而是边压边修正,让后面的列吸收前面造成的输出偏差。
可把局部目标近似写成:
其中 是由校准数据诱导出的近似 Hessian 或输入相关二阶矩阵。
直觉上,如果某个方向上的曲率大,说明那里的误差更“贵”,GPTQ 会尽量避免在这些方向上犯大错。
列级量化的直觉
把矩阵 视作一列一列处理:
当量化第 列后,会根据误差残差修正剩余列。
这有点像做高斯消元式的误差传递。
GPTQ 适合什么
GPTQ 适合大模型离线权重量化、不想重训、但能接受较复杂离线预处理的场景。
GPTQ 的现实感受
它常像在说:
“我知道你必须把这列压成 4bit,但至少让我聪明地决定怎么压,以及把误差甩给谁。”
6. AWQ:权重是否重要,要看激活怎么打到它
AWQ 的关键观察是:
决定输出误差的不是权重本身大小,而是“权重与激活共同作用”。
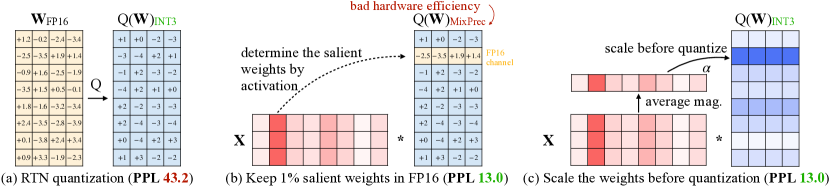
图源:AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration,Figure 1。原论文图意:普通 RTN 量化会明显升高困惑度;保留少量 activation-salient weights 或在量化前按激活幅度缩放权重,可以显著恢复质量。
同一个权重误差,如果乘上的激活很小,输出影响也可能很小;如果乘上的激活经常很大,就会被放大成明显输出偏差。AWQ 因此用校准激活去找真正影响输出的通道或权重,再通过缩放和保护让这些位置别被 4bit 误差打坏。
若某通道激活常很大,那么该通道对应权重的小误差也会被放大。
因此 AWQ 更关注:
虽然不同实现细节不同,但总体思想都是找出少量高敏感权重或通道,并通过缩放与保护策略减少其量化伤害。
一个直观例子:会议纪要模型
假设模型在处理长会议纪要时,某些注意力输出通道经常承载“说话人切换”“时间顺序”“结论句”这类重要信息。
如果这些通道的激活峰值大,那么同样 4bit 误差落在它们上面,比落在普通通道上更致命。
AWQ 的价值就在于:
它不把所有权重一视同仁。
7. SmoothQuant:不是只压权重,还要“驯服”激活离群值
在很多 LLM 中,激活分布比权重更难量化,因为会出现少数特别大的 outlier。
SmoothQuant 的核心技巧是引入一个对角缩放矩阵 ,把激活尺度一部分搬运到权重中:
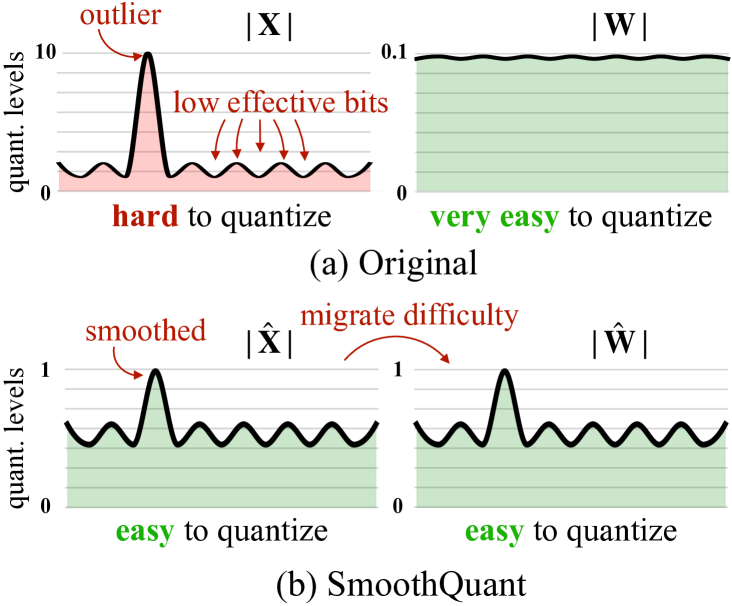
图源:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models,Figure 2。原论文图意:原始激活 含有 outlier,导致有效量化 bit 变少;SmoothQuant 将一部分难度从 activation 迁移到 weight,让两侧都更容易量化。
SmoothQuant 利用线性层里的等价变换 :输出数学上不变,但数值难度从激活侧搬到权重侧。因为权重是静态的、离线可处理,激活是动态的、线上会随输入变化,所以把难量化的激活尖峰转移一部分到权重里,通常比直接硬量化 activation 更稳。
设 ,则可以通过调节各维 ,让新激活 更平滑,让新权重 稍微更难但总体更适合量化。这本质上是在做数值重分配:原本“激活太尖,权重很温和”,调整后变成“激活没那么尖,权重稍微变难一点”。
只要总体更平衡,低比特量化就更稳。
一个生动例子:搬货而不是减货
SmoothQuant 像是搬仓库。
原本一辆车上堆了太多重货,另一辆车很轻。你不是把货扔掉,而是把一部分重货搬过去,让两辆车都处在可承受范围内。
8. 这几个方法的关系
可以把它们粗略看成几种视角:PTQ 定义“不重训如何直接量化”的总问题,GPTQ 从二阶近似和离线误差补偿出发,AWQ 从激活敏感性出发保护重要通道,SmoothQuant 则通过重参数化缓解激活 outlier。它们并不完全互斥,而是回答不同子问题。
9. 什么时候选哪种
9.1 只做权重量化,想快速部署
优先考虑 GPTQ 或 AWQ,前者更偏二阶补偿,后者更偏激活敏感通道保护。
9.2 想继续向激活量化推进
重点看 SmoothQuant,因为很多时候真正卡住 INT8/INT4 激活部署的不是权重,而是激活 outlier。
9.3 模型已经很大,长上下文服务压力大
这时不能只看权重量化,还要联动看 KV cache、激活精度和 kernel 支持,否则你可能把权重压小了,但整机显存还是被 cache 吃满。
10. 三个部署案例
10.1 13B 客服模型
目标是单机部署、回答长度中等,且质量要求高于极限压缩。常见策略是先上 AWQ 或 GPTQ 的 4bit 权重量化,同时保持关键激活仍用较高精度。
10.2 RAG 文档问答模型
目标是服务长上下文和重 prefill,请求吞吐同时受显存与 cache 限制。常见策略是把权重量化和 KV cache 优化一起考虑;若激活量化不稳,宁可保守一点,也不要让长文档任务崩。
10.3 边端代码助手
目标是适应极小显存和受限设备带宽。常见策略是采用更激进的低比特权重量化,但要接受某些复杂推理任务退化更明显。
11. 常见失败模式
11.1 校准集太短、太简单
模型在长推理、代码、多轮对话上掉点严重。
11.2 只看困惑度,不看真实任务
有时 PPL 只略升,但工具使用、结构化抽取、长上下文对齐明显变差。
11.3 量化配置和 kernel 不匹配
理论上很优的分组方案,实际硬件上反而跑不快。
11.4 权重压下去了,系统瓶颈却转移了
例如权重变小后,KV cache、数据搬运、调度才成了主瓶颈。
12. 工程建议
一个更稳的量化流程通常是:先明确目标是省显存、提吞吐还是边端落地,再做 W-only 量化建立基线;随后用贴近真实流量的校准集评估,再决定是否引入激活量化或更激进比特数,最后用真实任务指标而不是单一 PPL 做验收。
13. 总结
后训练量化真正难的地方,不在“把 16bit 变成 4bit”,而在“哪些误差能忍,哪些误差绝对不能犯”。
GPTQ 用二阶近似回答这个问题,AWQ 用激活敏感性回答这个问题,SmoothQuant 则从激活 outlier 的角度重新整理数值分布。
它们共同指向一个结论:量化不是粗暴压缩,而是一次受约束的误差重分配。
快速代码示例
1 | import torch |
这段代码实现了按输出通道的 INT8 量化:先用每通道最大绝对值求 scale,再量化到 int8 并反量化得到 w_hat。它可以直观看到量化误差来源,是理解 GPTQ/AWQ 权重重建思想的基础。
工程收束
PTQ、GPTQ、AWQ 与 SmoothQuant 的差异不只是公式不同,更在于它们如何把精度损失转移到校准数据、离群值治理、scale、runtime 和硬件路径里。选型时先确定目标场景和硬件边界,再决定量化对象,并同时验证平均质量、任务桶、TTFT、TPOT、cache 占用、编译启动成本、shadow 和回退路径。
- Title: 量化:PTQ、GPTQ、AWQ 与 SmoothQuant
- Author: Charles
- Created at : 2026-01-12 09:00:00
- Updated at : 2026-01-12 09:00:00
- Link: https://charles2530.github.io/2026/01/12/ai-files-quantization-ptq-gptq-awq-smoothquant/
- License: This work is licensed under CC BY-NC-SA 4.0.