
量化:QLoRA 与量化训练
QLoRA 的重要性,不在于它发明了 LoRA,也不在于它第一次做量化,而在于它把两件事组合起来,形成了一个非常实用的工程结论:
大模型不必全量微调,也不必全精度驻留,依然能在单机或少量卡上完成高质量适配。
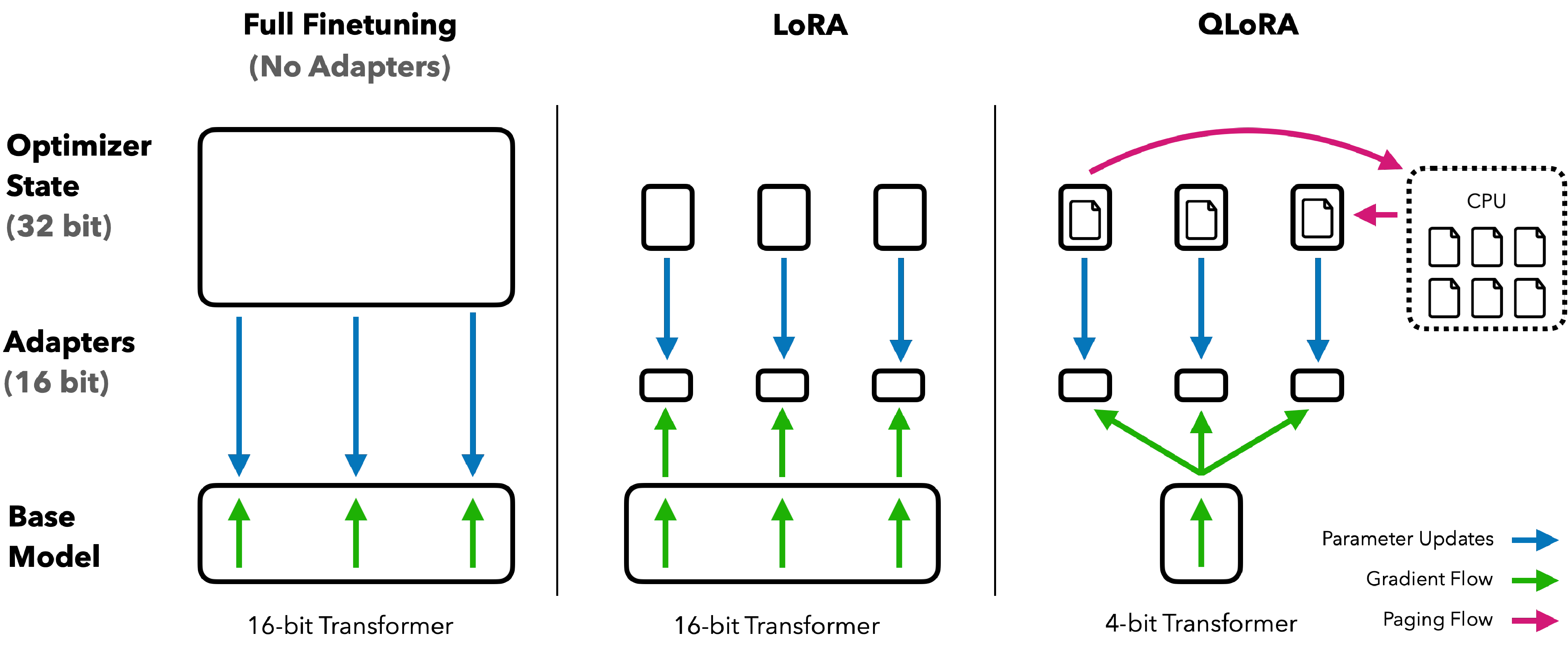
图源:QLoRA: Efficient Finetuning of Quantized LLMs,Figure 1。原论文图意:对比普通 32-bit/16-bit 微调、LoRA 与 QLoRA 的显存组织;QLoRA 将冻结底座量化存储,只训练 adapter,并通过分页机制缓解显存峰值。
全量微调要给底座权重、梯度和优化器状态都付钱;普通 LoRA 已经只训练 adapter,但底座通常仍以较高精度驻留;QLoRA 再把冻结底座压到 4bit,并让 optimizer 主要服务 LoRA 参数。它适合低资源任务适配,但不是低比特全量训练,也不保证最终 serving 一定最快。
QLoRA 的关键组合是:主模型用低比特存着省显存,只训练很小的 LoRA 增量。它适合任务适配,不等于低比特全量训练,也不等于部署一定最快。
不改整台机器,只在关键位置加一个小外挂,就能让它适配新任务。LoRA 是小外挂,量化底座是把大机器压缩存放,QLoRA 则是让两者一起工作。
1. 从全量微调到参数高效微调
若一个线性层权重为:
全量微调意味着更新整个 。
LoRA 的做法是只学习一个低秩增量:
其中:
也就是说,原本要学 个参数,现在只学:
当 很小时,这个规模会小很多。
1.1 LoRA 的直觉
它在假设:
很多下游适配并不需要把整个大矩阵重写,只需要在一个较低维的更新子空间里调整方向。
这也是为什么 LoRA 常被描述成:保留底座知识,学习一个小型任务特定偏移,用很少的可训练参数完成行为改写。
2. QLoRA 比普通 LoRA 多做了什么
普通 LoRA 仍要求底座模型权重以较高精度驻留。
QLoRA 的关键变化是:底座权重量化存储,前向时反量化参与计算,训练时冻结底座,只更新 LoRA 参数。
可写成:
其中 表示量化后的冻结底座。
训练时不会更新 ,梯度只流向 。
3. 为什么这样能省显存
训练显存主要来自模型权重、激活、梯度和优化器状态。QLoRA 同时在三处省钱:底座权重低比特存储,冻结底座后无需底座梯度,优化器状态也只为 LoRA 参数分配。
因此相较全量微调,显存下降非常明显。
3.1 一个粗略的参数量直觉
若有一个 的线性层,原始参数量约为:
若 LoRA rank 为 ,则增量参数为:
这比全量层参数小两个数量级以上。
一个直观例子:像给旧楼加外挂电梯
全量微调像把整栋楼拆了重建。
LoRA 更像保留原楼,只在关键结构旁边加一个小但有效的外挂部件。
QLoRA 则进一步把原楼里不常变动的大块结构做了压缩存放,维修时只动外挂部分。
4. QLoRA 里的量化通常长什么样
QLoRA 的经典实现并不是随便拿个 INT4 就够了,而是围绕训练可用性做了专门设计。最常被提到的要点有:
4.1 4-bit 权重量化
底座权重通常以 4-bit 形式存储,以显著压缩权重显存。
4.2 训练时高精计算
虽然权重以低比特存储,但前向矩阵乘法仍会在更高精度下完成累加。
这让模型保留足够数值稳定性。
4.3 只训 adapter
冻结底座后,训练图中只有 LoRA 分支需要梯度和优化器状态。
4.4 分页优化器
很多实现会配合 paged optimizer,尽量减少优化器状态峰值对显存的冲击。
5. 为什么量化底座后还能训练
关键点在于:量化主要影响底座表示精度,但底座仍保留了大部分预训练能力,LoRA 参数负责补偿任务适配所需的小范围修正。
训练时前向可理解为:
虽然 不是全精度,但只要量化误差没大到破坏基础语义结构,LoRA 仍有机会在其上“微调方向”。
5.1 隐含假设是什么
从优化角度看,QLoRA 隐含的假设是:
高质量适配所需的参数更新,落在一个相对低维的子空间里;而底座即使被量化,也仍保留足够多的基础能力供这个低维更新去利用。
6. QLoRA 为什么通常还能保持不错效果
因为许多下游适配任务并不需要彻底改写底座知识,而是改写输出风格、学习新领域术语分布、适配任务模板、注入少量任务特定能力,或调整拒答、格式和工具调用习惯。
这些变化在很多情况下都可以由低秩增量近似表达。
一个更务实的理解
QLoRA 更像“偏转模型”,而不是“重塑模型”。
如果底座本来就大致会做这件事,QLoRA 往往很有效;
如果底座本来几乎不会,QLoRA 就容易碰上上限。
7. target modules 为什么很关键
LoRA 并非插哪都一样。
常见 target modules 包括 attention 的 、MLP 的上投影和下投影,有时也会包括 embedding 或输出头。一般来说,只插 attention 更省参数,attention + MLP 表达能力更强;插得越广,容量越大,但训练和部署复杂度也更高。
7.1 一个常见经验
如果任务主要是在“行为与风格”层面偏转,attention 模块常已足够有效;
如果任务需要更强的领域改写或结构化输出能力,MLP 模块的 adapter 往往也值得加。
8. Rank、alpha 和 dropout 在控制什么
8.1 Rank
控制低秩更新的容量。
越大,模型可学习的适配方向越多,但显存和训练成本也会上升。
8.2 LoRA alpha
常用于对增量分支做缩放,让训练初期更稳定。
8.3 LoRA dropout
可视作对 adapter 分支的正则,尤其在小数据集场景里有帮助。
8.4 一个实践上的判断
若 太低,常见现象是输出格式先学会、浅层风格改变明显,但深层任务能力起不来。
若 提升后收益已经趋缓,再继续增大往往就不是最划算的方向。
9. 什么时候 QLoRA 最合适
9.1 领域适配
例如医疗问答、法律检索问答、金融报告总结和企业私域知识助手。
这些任务通常更依赖“语言分布和任务模板适配”,而不是重学整个世界知识。
9.2 风格或对话格式适配
例如客服语气、JSON 格式输出、更严谨的拒答风格和更稳定的工具调用 schema。
9.3 算力预算有限
当你不能做多卡全量微调时,QLoRA 往往是最现实路线之一。
9.4 数据规模有限
当下游数据只有几千到几十万条时,做一个轻量 adapter 往往比全量大改更稳。
10. 三个具体例子
10.1 医疗问答助手
你有一个通用 7B 模型,但想适配医疗术语、门诊问答格式和更保守的风险提示。
QLoRA 很适合,因为底座已有通用语言能力,你只需要把它往医学分布上推。
10.2 企业代码助手
底座模型已经会通用编程,但你想让它熟悉公司内部 API、按团队代码风格生成,并输出更规范的注释。
这类任务通常也适合 LoRA/QLoRA,而不是全量重训。
10.3 文档结构化抽取
如果目标是把合同、发票、报表转成固定 JSON schema,QLoRA 常能以较小成本完成风格和格式适配。
11. QLoRA 什么时候会吃力
11.1 任务需要大幅改变底座能力边界
如果底座本身就不会某类推理或知识,LoRA 很难凭空创造完整能力。
11.2 域偏移太大
例如从通用聊天模型硬适配到强专业数学证明、复杂代码修复、特殊多模态控制。
这时低秩增量容量可能不够。
11.3 底座量化过激
若底座量化误差太大,LoRA 可能是在一块已经严重变形的基座上补丁,补不回来。
11.4 Rank 太小
若 太低,模型只能学极少的适配方向。
11.5 数据质量差
QLoRA 很适合快速适配,但也因此更容易把脏数据、格式噪声和错误风格直接写进 adapter。
12. QLoRA 不是“免费午餐”
尽管它很省资源,但仍要付出代价:训练速度未必比全精度少很多,kernel 和量化实现更复杂,合并权重与导出部署要注意兼容性,线上如果同时挂多个 adapter,还要考虑路由和缓存管理。最终部署时还要决定是继续保留 LoRA 分支在线叠加,还是合并后再量化导出。
不同部署路径的效果和成本可能不同。
13. QLoRA 与其他量化训练路线的区别
把它和 QAT、全量低比特训练区分开很重要:
13.1 和 QAT 的区别
QAT 主要是在训练时让模型适应低比特推理环境,通常目标是“训练出一个可直接低比特部署的模型”。
QLoRA 的主目标则是“在低显存下完成参数高效微调”。
13.2 和全量低比特训练的区别
QLoRA 不更新底座;
全量低比特训练则仍试图更新大量甚至全部权重,成本和风险都更高。
13.3 和普通 LoRA 的区别
普通 LoRA 把重点放在参数少;
QLoRA 则同时把重点放在底座常驻显存少。
14. 一个实用判断框架
如果你面对的是较强底座、有限下游数据、有限预算和快速适配目标,QLoRA 往往是首选。如果任务需要大幅重塑能力边界、和底座差得很远,或者对峰值效果要求极高,就要认真评估全量微调或更大规模后训练。
14.1 训练前最好先问自己四个问题
先问底座模型本来会不会这类任务,这次适配主要改风格、改知识分布还是改能力边界,线上最终是合并部署还是多 adapter 路由,目标瓶颈是显存、训练时间还是峰值效果。这几个问题通常比盲目调 rank 更重要。
15. 总结
QLoRA 的本质,是把“冻结量化底座”和“低秩增量学习”结合起来,让大模型适配从高成本工程降成可普及流程。
它最适合做的是“在一个已够强的底座上,低成本地偏转行为和分布”,而不是彻底重塑模型。理解这一点,就能更准确地知道它为什么强,也知道它在哪些任务上不该被神化。
工程收束
QLoRA 的价值不只是省显存,还在于适配器训练、量化状态、恢复链路和资产迁移是否能接上。验收时要同时看数值回归、任务桶表现、训练恢复、optimizer / scale 状态、adapter 合并、推理转换和高精度回退;只看显存下降,很容易低估后续评测、导出和服务迁移成本。
- Title: 量化:QLoRA 与量化训练
- Author: Charles
- Created at : 2026-01-16 09:00:00
- Updated at : 2026-01-16 09:00:00
- Link: https://charles2530.github.io/2026/01/16/ai-files-quantization-qlora-and-quantized-training/
- License: This work is licensed under CC BY-NC-SA 4.0.