
训练:Megatron、DeepSpeed 与 FSDP:训练栈选型先拆账
大模型训练栈很容易被问成“Megatron、DeepSpeed、FSDP 谁更好”。这个问题本身就偏了。它们解决的不是同一层问题:Megatron-style parallelism 主要切 Transformer 层内计算和并行拓扑;ZeRO / FSDP 主要切数据并行里重复保存的训练状态;DeepSpeed 更像运行时和内存优化平台;checkpoint、导出和实验治理决定训练资产能不能进入后训练、评测和推理。
这页只回答一个问题:当模型单机放不下或跑不满时,应该怎样判断要切计算、切状态、切层、切序列、切专家,还是先修数据和 checkpoint。
先问哪张账爆了
一次训练 step 里,不同瓶颈来自不同对象。
| 账本 | 里面有什么 | 常见工具 |
|---|---|---|
| 计算账 | MLP、attention、vocab projection 的 GEMM 和 attention | Megatron TP、FlashAttention、Transformer Engine、CUTLASS / Triton |
| 状态账 | parameters、gradients、optimizer states、master weights | ZeRO、FSDP、distributed optimizer、offload |
| 激活账 | forward saved tensors、长序列 attention、micro-batch activations | activation checkpointing、sequence / context parallel、pipeline schedule |
| 通信账 | all-reduce、all-gather、reduce-scatter、all-to-all、p2p | rank mapping、communication overlap、NCCL tuning |
| 资产账 | checkpoint、RNG、data progress、topology、config、export format | sharded checkpoint、manifest、portable weights、实验平台 |
看到 OOM 或吞吐低时,先问是哪张账爆了。optimizer state 爆掉,ZeRO / FSDP 比张量并行更直接;单层矩阵太宽,Megatron TP 更直接;层数太深,PP 和 micro-batch 调度更直接;长上下文激活爆掉,CP / SP、FlashAttention 和 activation checkpointing 更直接;数据喂不满,换训练框架不会解决根因。
这也是 Megatron 和 ZeRO 适合成对读的原因。Megatron-LM 问的是“一个 Transformer layer 怎么被多卡共同计算”;ZeRO 问的是“为什么 data-parallel ranks 不该每张卡都长期保存同一份 optimizer states、gradients 和 parameters”。现代训练栈通常不是二选一,而是把这些账叠起来。
Megatron 切的是 Transformer 层内计算
Megatron-LM 的 tensor parallelism 不只是“把参数平均切开”。它的关键是选择同步点,让非线性和 attention 尽量在本地完成,只在必要位置通信。
以 MLP 为例,普通 Transformer MLP 可以写成:
这里 表示输入 hidden states, 表示升维矩阵, 表示降维矩阵。Megatron 的做法是:第一层按列切 ,第二层按行切 。
每个 tensor-parallel rank 只算自己那片 hidden expansion:
GeLU 可以本地做,因为每个 rank 拿到的是完整输入 和自己负责的中间通道。第二层按行切后,每个 rank 生成一部分输出贡献:
最后这个求和需要 all-reduce。这就是 Megatron TP 的核心直觉:不要在 GeLU 之前或每个小操作之后都同步,而是把通信压到结构上必要的位置。
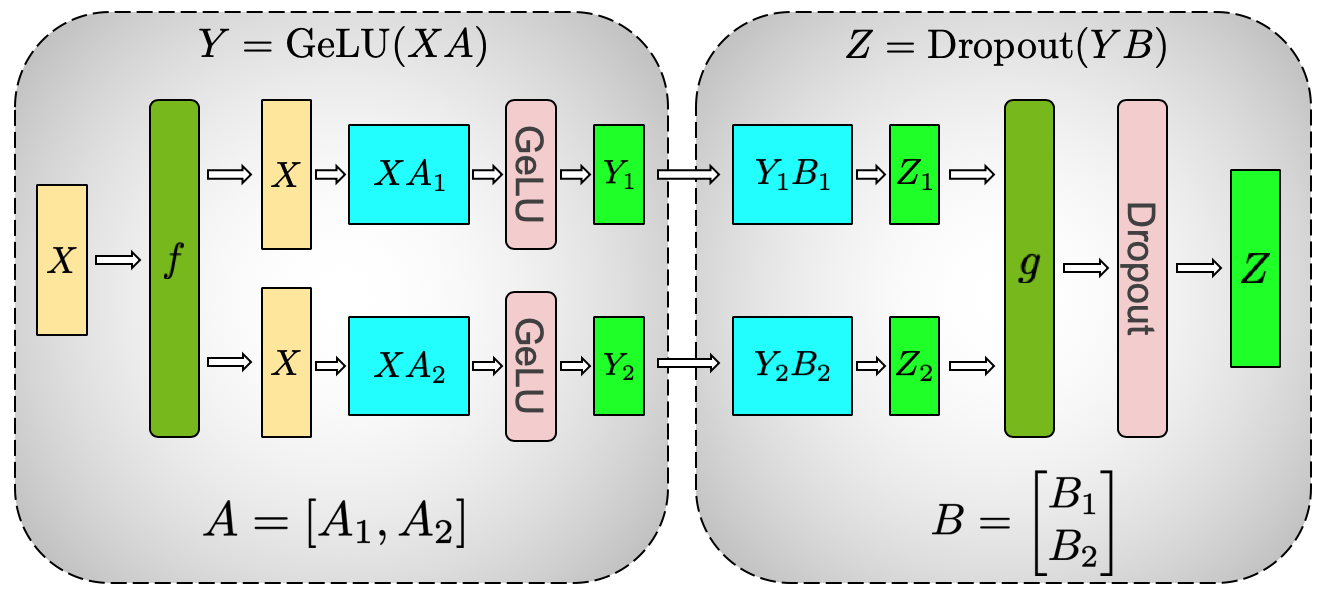
图源:Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism,Figure 3a。本站用这张图说明 MLP 中第一层 column parallel、第二层 row parallel,以及 GeLU 本地执行、输出处 all-reduce 的通信位置;没有用 image2 或其他生成式工具作图。
Attention 也类似。多头 attention 天然可以按 heads 切分:不同 rank 负责不同 heads 的 Q / K / V projection 和 attention,最后在 output projection 之后同步。词表投影和 cross entropy 也可以走 vocab parallel,避免把巨大 logits 全量 gather 到每张卡。
Megatron 的价值因此不只是一个论文技巧,而是一套“Transformer 构件 + 并行线性层 + 并行 attention + pipeline / context / expert parallel + 通信重叠”的训练骨架。NVIDIA Megatron Core 文档把这些构件模块化,说明它已经从研究代码变成更接近训练基础设施的组件库。
TP、PP、DP、CP、EP 不是同一种切法
大规模训练常把 world size 写成多个并行维度的乘积:
这里 表示数据并行副本数, 表示张量并行切分数, 表示流水线 stage 数, 表示上下文并行切分数, 表示专家并行切分数。这个式子不是为了凑符号,而是提醒:每个维度都对应不同通信模式。
| 维度 | 切了什么 | 主要通信 | 常见放置 |
|---|---|---|---|
| DP | 数据 batch 副本 | gradient all-reduce / reduce-scatter | 最外层扩展 |
| TP | 单层矩阵、attention heads、vocab | 层内 all-reduce / all-gather | 节点内 NVLink 域优先 |
| PP | Transformer layers | stage 间 activation / grad 传输 | 可跨节点,但要控 bubble |
| CP / SP | 序列或上下文维度 | attention 相关通信 | 长上下文训练 |
| EP | MoE experts | token dispatch / combine all-to-all | 依赖专家放置和负载均衡 |
高频通信越多,越应该放在更近的拓扑域内。TP 通常最怕跨节点;EP 的 all-to-all 会被专家放置和 token 分布影响;PP 的难点是 bubble 和 micro-batch;CP 的难点是长上下文 attention kernel、序列切分和通信重叠是否能一起成立。
Megatron 2021 的大规模训练论文重点就在这里:tensor、pipeline、data parallelism 可以组合,但朴素组合会因为跨节点通信和设备等待而扩展不佳。训练栈的工程价值,不是“开更多并行开关”,而是让 rank mapping、通信域、micro-batch、checkpoint 和恢复语义彼此一致。
ZeRO / FSDP 切的是数据并行状态
普通 data parallel 每张卡都有完整模型副本,反向后同步梯度。它简单,但会重复保存 parameters、gradients 和 optimizer states。对 mixed precision Adam,ZeRO 论文给出一笔经典账:
这里 表示参数量对应的字节基准。一个 1.5B 参数模型的 FP16 权重约 3GB,但训练态模型状态至少约 24GB,还没算 activation、通信 buffer、临时 workspace 和 fragmentation。
ZeRO / FSDP 的核心就是减少 DP ranks 间的重复常驻状态。
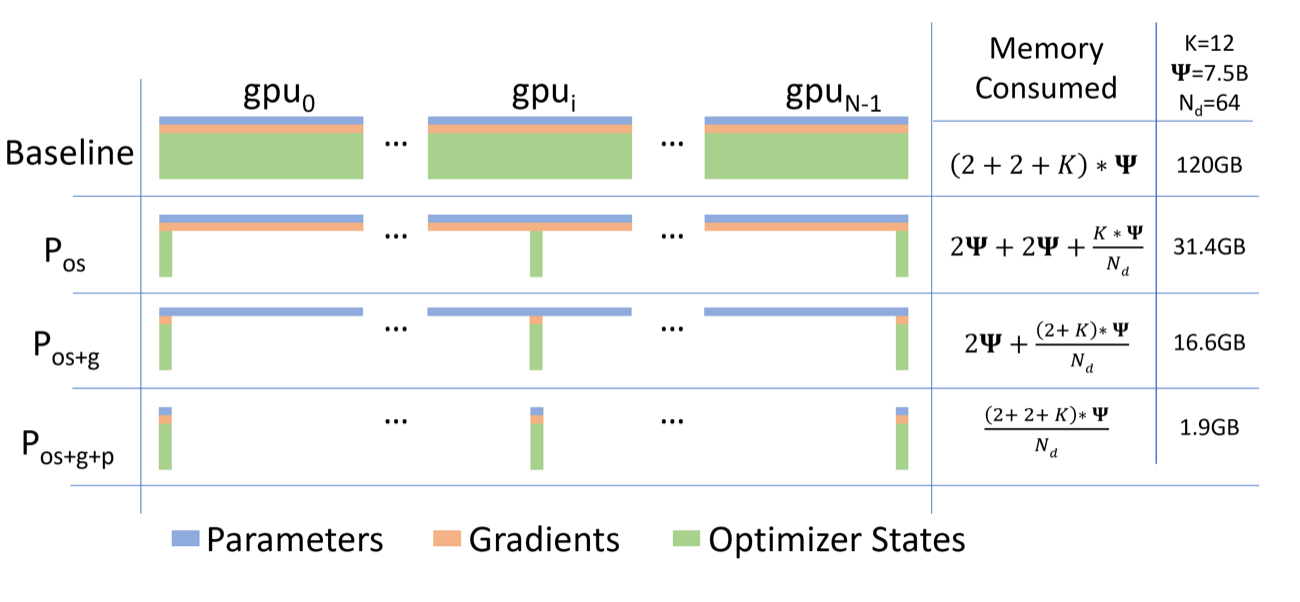
图源:ZeRO: Memory Optimizations Toward Training Trillion Parameter Models,Figure 1。本站用这张图说明 ZeRO Stage 1 切 optimizer states,Stage 2 继续切 gradients,Stage 3 连 parameters 也按需分片;没有用 image2 或其他生成式工具作图。
三阶段可以这样读:
| 方法 | 长期不再完整复制什么 | 新增代价 |
|---|---|---|
| ZeRO-1 | optimizer states | optimizer partition 和更新后的参数同步 |
| ZeRO-2 | optimizer states + gradients | reduce-scatter、梯度分片管理 |
| ZeRO-3 / full sharding | optimizer states + gradients + parameters | forward / backward 按需 all-gather 参数、reshard、复杂 checkpoint |
FSDP 与 ZeRO-3 的思想接近:按 module 或参数组分片,计算前 all-gather 需要的参数,计算后 reshard。差异主要在工程生态。DeepSpeed / ZeRO 更像配置化训练运行时,offload、ZeRO stage、pipeline engine 和异步 I/O 配套成熟;FSDP 更贴近 PyTorch 原生 distributed stack,state dict、module wrapping、编译生态和自定义模型集成更自然。
所以不要把 DeepSpeed 和 FSDP 简化成“谁更省显存”。真正要比较的是:wrap 粒度谁来管,通信重叠谁来管,state dict 怎么导出,checkpoint 能否跨 topology 恢复,低精度 scale 和 optimizer state 如何保存,团队愿不愿意依赖特定 runtime。
DeepSpeed 是运行时和内存平台
DeepSpeed 经常和 Megatron 一起出现,因为它们不在同一层。Megatron 更像模型并行和 Transformer 训练构件;DeepSpeed 更像训练 runtime,负责 ZeRO、offload、pipeline、I/O、配置和运行时能力。
Megatron + DeepSpeed 的组合常见于这种场景:Megatron 负责 TP / PP / 模型构件,DeepSpeed 负责 ZeRO 分片、offload 或训练引擎。它不是简单“两个框架叠加”,而是把模型并行和状态分片接到同一训练生命周期里。
这个组合也会让复杂度上升。参数生命周期、optimizer ownership、checkpoint shard 格式、rank mapping、pipeline schedule、ZeRO stage、activation checkpointing、FP8 / AMP 状态都要统一。训练能跑一个 step,并不等于 checkpoint 能恢复,也不等于产物能导出到 SFT 或推理。
组合训练栈时先按瓶颈选工具
更稳的选型顺序是按瓶颈,而不是按框架名。
| 症状 | 更可能优先处理 |
|---|---|
| optimizer state 和梯度副本放不下 | ZeRO / FSDP、低精度 optimizer、offload |
| 单层 hidden size、attention heads、vocab projection 太大 | Megatron TP、vocab parallel、parallel cross entropy |
| 模型层数太深,单卡或单节点放不下 | PP、stage 切分、micro-batch、1F1B / interleaved schedule |
| 序列长度太长,activation 或 attention 爆显存 | CP / SP、activation checkpointing、FlashAttention 变体 |
| MoE all-to-all 和专家负载成为主瓶颈 | EP、专家放置、capacity factor、dispatch / combine kernel |
| 数据加载、packing 或 tokenizer 喂不满 | 数据系统、prefetch、packing、shuffle / resume |
| 故障恢复和导出经常出问题 | checkpoint manifest、state dict 策略、portable weights |
一个可维护训练栈通常有清晰边界:
1 | model definition |
如果这些边界混在一个脚本里,短期能跑,长期会很难换框架、改并行度、做后训练、迁移 checkpoint 或排查故障。
Checkpoint 是训练栈的一等接口
训练栈的成熟度很大程度体现在 checkpoint。大规模训练 checkpoint 不是一个权重文件,而是一组可恢复资产:模型参数、optimizer states、scheduler、loss scaler、RNG、sampler / packing 进度、consumed tokens、parallel topology、shard manifest、tokenizer、数据版本、代码版本和关键配置。
不同训练栈对 checkpoint 的语义不同:
| 形态 | 用途 | 风险 |
|---|---|---|
| sharded training checkpoint | 续训和故障恢复 | 依赖 topology、manifest 和分片映射 |
| full / portable weights | SFT、评测、推理、量化 | 导出慢,可能丢 optimizer / data / RNG 状态 |
| async checkpoint | 降低主链暂停 | 一致性边界、后台失败、半成品提交 |
| state dict API | 框架内保存/加载 | full / sharded / local state dict 语义必须明确 |
FSDP 文档里反复出现 state dict 类型,Megatron Core 也有 distributed checkpointing,这些不是琐碎 API,而是训练资产的边界。一个 checkpoint 若只能在当前 world size、当前代码、当前 runtime 里恢复,却无法导出 full weights 或记录数据进度,就不该被当成完整训练资产。
不同规模下取舍不同
8-32 卡训练,中小模型或实验迭代优先简单稳定。FSDP / ZeRO 加少量 TP 往往足够;更重要的是数据顺序、checkpoint、评测和日志可复现。
64-256 卡时,拓扑开始支配吞吐。TP 是否跨节点、PP stage 是否均衡、micro-batch 是否填满 pipeline、ZeRO / FSDP 是否和 checkpoint 语义兼容,会比单个 optimizer 配置更重要。
512 卡以上,训练栈已经是组织工程。需要明确 owner、故障演练、自动化恢复、通信 trace、资产导出和版本治理。此时“框架选择”只是其中一小部分,真正难的是让模型、数据、runtime、checkpoint 和评测长期一致。
多模态、长上下文和 MoE 会进一步放大复杂度。图像 / 视频 token 增多会推高 activation 和 attention 成本;长上下文会把 CP / SP、kernel、checkpoint 和数据 packing 绑在一起;MoE 会把专家路由和 all-to-all 变成训练栈核心。
最后判断
Megatron、DeepSpeed、FSDP 不应被读成同一张排行榜。Megatron 解决 Transformer layer 内部如何跨 GPU 计算;ZeRO / FSDP 解决 data-parallel 副本中训练状态如何不重复常驻;DeepSpeed 提供运行时和内存优化平台;checkpoint 和导出接口决定训练资产能否进入后训练、评测、推理和量化。
如果只记住一句话:训练栈选型是成本账分解,不是框架名比较。先定位瓶颈属于计算、状态、激活、通信、数据还是资产,再决定用 TP、PP、ZeRO / FSDP、CP / SP、EP、offload、checkpointing 或数据系统治理。
外部精读
- Megatron-LM:理解 tensor parallelism 如何切 MLP、attention heads 和 vocab projection。
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM:理解 tensor、pipeline、data parallelism 如何组合到大规模集群。
- ZeRO:理解 optimizer states、gradients、parameters 在 data parallel 中为什么重复占显存。
- DeepSpeed Megatron tutorial:看 Megatron 与 ZeRO 如何在工程训练栈里组合。
- DeepSpeed ZeRO documentation:查 ZeRO-3、offload、参数 gather 和运行时 API。
- Megatron Core documentation:查现代 Megatron Core 的 TP / PP / DP / EP / CP、distributed optimizer、MoE 和 checkpoint 模块。
- Megatron Core tensor parallel API:把 column / row parallel、vocab parallel 和 parallel cross entropy 对应到现代接口。
- PyTorch FSDP documentation:理解 PyTorch 原生 full sharding、state dict 和参数生命周期。
- Datawhale:VRAM Calculation and ZeRO:中文显存账入口,适合配合原论文手算参数、梯度和优化器状态。
相关阅读与下一步
- 外部材料:PyTorch Distributed 文档。
- 外部材料:DeepSpeed ZeRO 教程。
- 外部材料:Weights & Biases 文档。
- 站内下一步:训练系统专题。
- 站内下一步:分布式训练与 Checkpoint。
- 站内下一步:评测与 Ablation 方法论。
- Title: 训练:Megatron、DeepSpeed 与 FSDP:训练栈选型先拆账
- Author: Charles
- Created at : 2026-01-24 09:00:00
- Updated at : 2026-01-24 09:00:00
- Link: https://charles2530.github.io/2026/01/24/ai-files-training-megatron-lm-deepspeed-and-open-training-stacks/
- License: This work is licensed under CC BY-NC-SA 4.0.