
强化学习:MDP、价值函数与 Bellman
强化学习的基础不是某个算法,而是一套描述闭环决策的语言。只要把 state、action、reward、policy、value 和 Bellman equation 理顺,后面的 PPO、GRPO、Dreamer 和世界模型都会清楚很多。
强化学习要解决的是“现在做什么会让未来更好”。所以它不只关心当前动作是否看起来合理,还关心这个动作会把系统带到什么状态,以及后面还能拿到多少奖励。
1. MDP 是最小决策模型
MDP 通常写成:
| 符号 | 简洁解释 |
|---|---|
| state space:环境可能处在的状态集合 | |
| action space:agent 可以选择的动作集合 | |
| transition:执行动作后状态如何变化 | |
| reward:当前动作或结果带来的反馈 | |
| discount factor:未来奖励打多少折扣 |
如果状态不能完全观测,就变成 POMDP。机器人和 VLA 常常是 POMDP,因为摄像头只能看到一部分世界,抽屉里、遮挡后、过去发生过的接触都可能影响下一步。
observation 是传感器看到的东西,例如当前图像;state 是足以预测未来的内部描述,例如物体位置、速度、接触关系和任务进度。VLM 往往处理 observation,世界模型要努力学习更接近 state 的 latent。
你站在客厅里只能看到桌面,这就是 observation。钥匙可能在抽屉里、沙发缝里或你刚刚放过的外套口袋里,这些未观测信息属于 state。好的 agent 会记住历史、主动打开抽屉或询问人类;只看当前画面做判断,很容易把“没看见钥匙”误当成“钥匙不存在”。
MDP 的一个隐含假设是 Markov property:只要知道当前 state,未来就不需要额外依赖更早历史。
这不是说真实世界没有历史,而是说我们选的 state 应该已经把有用历史压进去了。世界模型、RSSM、Transformer memory 和 VLA 的历史窗口,本质上都在努力构造更接近 Markov 的内部状态。
2. Policy 是行为规则
策略写成:
意思是:给定当前状态 ,模型以什么概率选择动作 。在语言模型 RLHF 中,状态可以理解为 prompt 加已经生成的前缀,动作就是下一个 token。
| 术语 | 简洁解释 |
|---|---|
| deterministic policy | 同一状态总输出同一动作,适合稳定执行 |
| stochastic policy | 同一状态按概率采样动作,适合探索和生成 |
| behavior policy | 负责采样数据的策略,可能是旧模型或示范策略 |
| target policy | 正在被优化或评估的策略 |
如果每次到路口都固定向左走,这是 deterministic policy。如果有 70% 概率向左、30% 概率向右,这是 stochastic policy。训练早期需要一定随机性,否则 agent 可能永远发现不了右边有出口。
Offline RL 和 VLA 示范数据经常来自旧策略或人类示范,也就是 behavior policy。你要训练的新策略可能想选更好的动作,但如果这个动作在数据里几乎没出现过,value 估计就只能外推,容易虚高。后面讲 support constraint、trajectory stitching 和 verl rollout 时,都要记住“数据到底是谁采来的”。
3. Trajectory、Episode 和 Horizon
RL 不只看单个样本,而是看一串状态、动作和奖励:
| 术语 | 简洁解释 |
|---|---|
| trajectory | 一段连续交互记录,可以是完整回合,也可以是截断片段 |
| episode | 从开始到终止的一整局任务,例如一局游戏或一次机器人任务 |
| horizon | 最多向前看多少步,短 horizon 看局部,长 horizon 看长期后果 |
| rollout | 用当前 policy 采样一段 trajectory,真实环境或模型环境都可以 |
如果 horizon 只有 1 步,机器人只会问“现在夹锅铲是否合理”。如果 horizon 有 30 步,它还要考虑夹起锅铲后抽屉是否打开、路径是否会撞到锅、放进去后是否需要松爪。世界模型之所以重要,是因为长 horizon 真实试错很贵,内部 rollout 可以先筛掉明显危险的候选动作。
4. Reward、Return 和 Value
单步 reward 是当前反馈:
return 是从当前时刻开始累计的未来奖励:
value 是在某个策略下,从状态 出发能拿到的期望 return:
Q-value 则多固定了当前动作:
Advantage 衡量“这个动作比平均策略好多少”:
reward 像这一步考试得了几分,value 像从现在开始预计整门课最终能拿多少分。一个动作当前 reward 可能低,但如果它把系统带到更好的未来状态,value 仍然可能很高。很多长时任务难,就难在短期反馈和长期收益不一致。
奖励太稀疏会难学,但奖励太细也会让模型钻空子。比如只奖励“夹爪靠近杯子”,机器人可能学会一直贴近杯子却不抓;只奖励“回答越长越好”,LLM 可能堆废话。好的 reward 要尽量贴近最终任务,同时监控是否出现投机行为。
5. Bellman 方程
Bellman 方程把“当前价值”拆成“当前奖励 + 下一状态价值”:
Q-value 也可以写成:
这就是动态规划、TD learning、actor-critic 和世界模型规划的共同基础。
Bellman 不是神秘公式,它只是说:要知道现在值多少钱,就看现在立刻得到多少,加上下一步状态值多少钱。世界模型的价值在这里很直接:如果能预测 和 ,就能在执行前估算未来账本。
6. 从 Bellman 到 Q-learning
Q-learning 直接学习 :在状态 做动作 后,长期看大概能拿多少回报。它用 Bellman 思路构造 TD target:
再让当前网络的 靠近这个 target:
| 术语 | 简洁解释 |
|---|---|
| Q-learning | 学状态-动作价值 ,再选价值最高的动作 |
| TD target | 用“当前奖励 + 下一状态估计价值”拼出的训练目标 |
| bootstrapping | 用模型自己的下一步估计来训练当前估计 |
| replay buffer | 保存过去交互样本,训练时随机抽取,减少样本相关性 |
| target network | 慢更新或延迟更新的目标网络,让 TD target 不至于每步剧烈漂移 |
你在商场里选择排哪家餐厅。reward 是这次吃得是否满意,value 是“排这家之后,等待、用餐、赶电影整体值不值”。Q-learning 不只记“这家好吃”,还要记“现在排队 50 分钟时还值不值”。
DQN 把 Q-learning 接到深度网络上,用图像作为输入,用神经网络预测每个动作的 Q-value。它的两个关键工程技巧是 experience replay 和 target network。
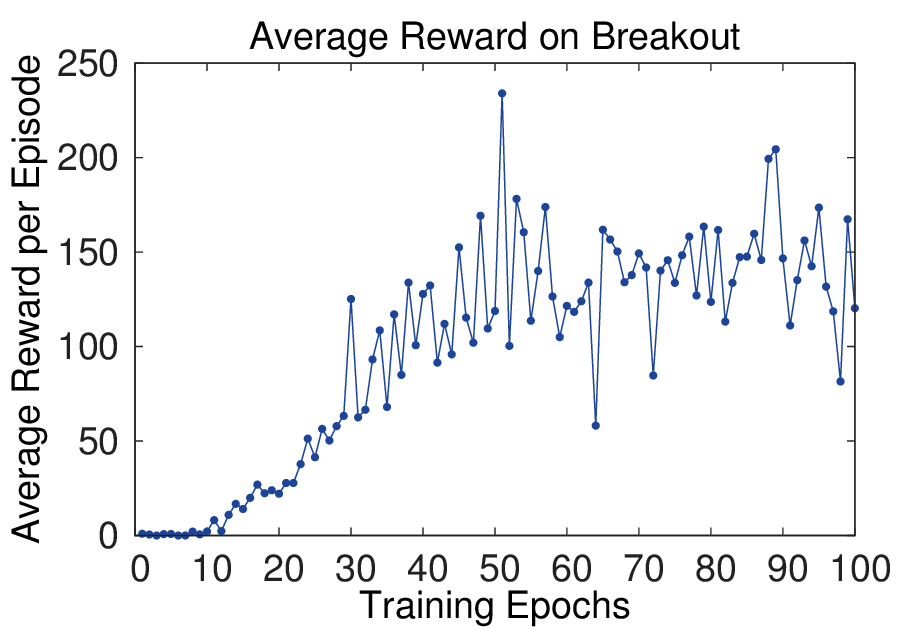
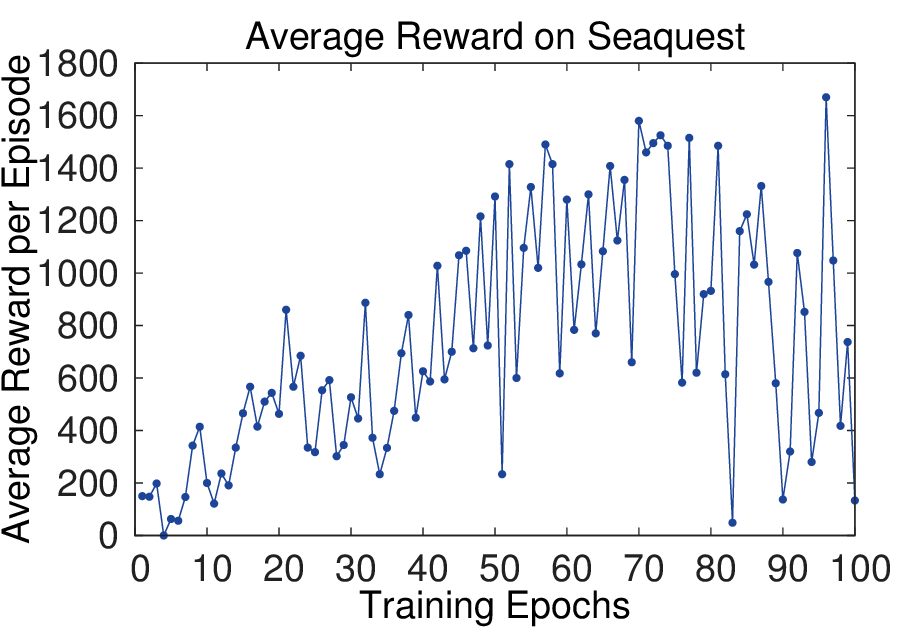
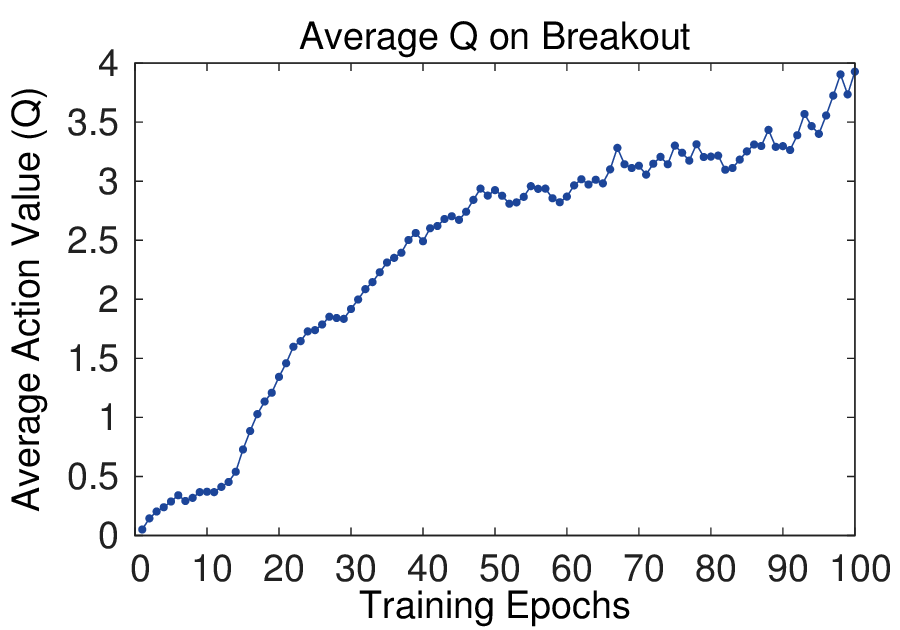
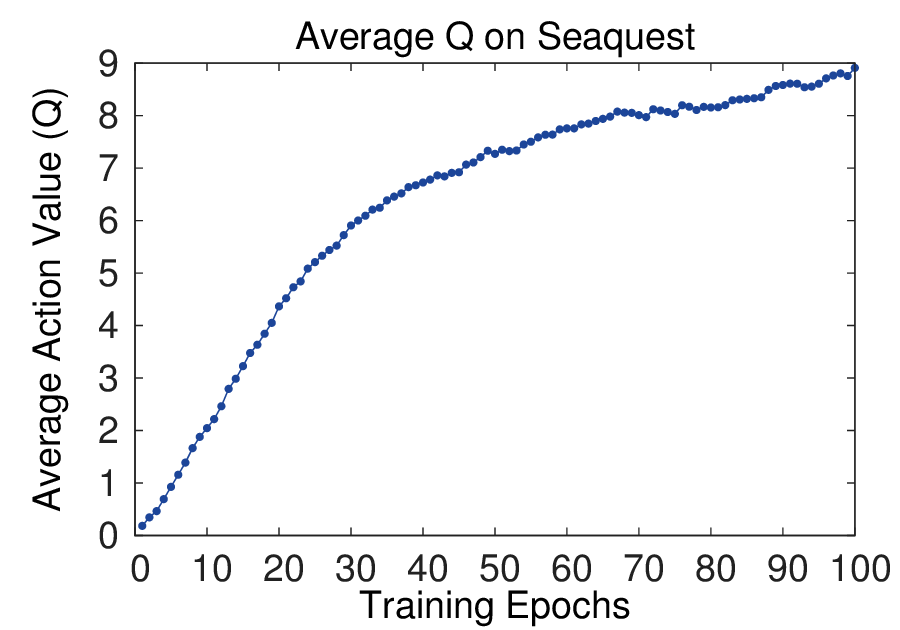
图源:Playing Atari with Deep Reinforcement Learning,Figure 2。原论文图意:左侧两图是 Breakout 和 Seaquest 训练中的平均回合奖励;右侧两图是固定状态集合上的平均最大预测 action-value。
平均回合 reward 很容易抖,因为策略一点小变化就会让整局游戏进入不同状态分布。右侧的平均最大 Q-value 用固定状态集合观察模型估计,像一个验证集上的长期价值读数,所以更平滑。初学者读训练曲线时不要只盯 reward:value、KL、entropy、success rate 和真实闭环评测经常要一起看。
7. Value 真的学到了什么
DQN 的 Seaquest 图很适合解释“value 是未来机会”,而不只是当前分数。




图源:Playing Atari with Deep Reinforcement Learning,Figure 3。原论文图意:左图是 Seaquest 中 30 帧片段的预测 value;A、B、C 是曲线上三个时间点对应的游戏画面。
A 点敌人出现,模型预测“现在有得分机会”,value 上升。B 点鱼雷快击中敌人,未来得分几乎要兑现,value 达到峰值。C 点敌人消失,机会被消耗,value 回落。这个例子能帮你分清 reward 和 value:reward 是打中那一下的即时分数,value 是打中之前模型已经看到的未来机会。
8. Model-free 与 Model-based
| 路线 | 学什么 | 优点 | 风险 |
|---|---|---|---|
| Model-free RL | 直接学习 policy 或 value | 不需要显式 dynamics,接口简单 | 样本效率低,长时信用分配难 |
| Model-based RL | 学 transition / world model,再规划或训练策略 | 可用 imagined rollout,提高样本效率 | 模型误差会被 planner 或 actor 利用 |
| Imitation / BC | 模仿示范动作 | 稳定、省交互、工程常用 | 出分布后容易连环偏离 |
| Offline RL | 只用离线数据学习策略 | 适合昂贵或危险环境 | 分布外动作的价值估计容易虚高 |
VLA 常从 BC 起步,因为机器人实机探索代价高。世界模型和 RL 的作用,是在 BC 之外补上“动作后果”和“长期奖励”的闭环。
9. On-policy、Off-policy 与 Offline RL
这三个词很容易混:
| 类型 | 数据从哪里来 | 更新时最怕什么 |
|---|---|---|
| on-policy RL | 当前 policy 刚采样的数据 | 样本贵、方差大、吞吐低 |
| off-policy RL | replay buffer 里的历史数据,仍会继续收新数据 | 旧数据和当前策略差太远 |
| offline RL | 固定数据集,不再和环境交互 | 分布外动作的价值被高估 |
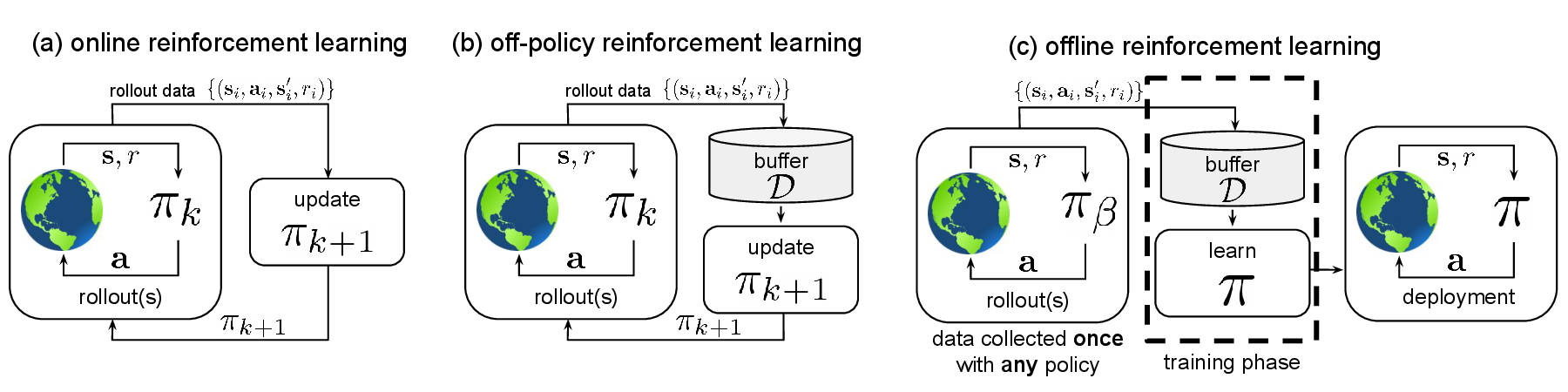
图源:Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems,Figure 1。原论文图意:对比 classic online RL、classic off-policy RL 和 offline RL 的数据收集与训练关系。
左图 online RL 每轮用当前 policy 收新数据;中图 off-policy RL 把多轮 policy 的数据放进 buffer 反复使用;右图 offline RL 的数据集一开始就固定,训练过程不能再试错。机器人、医疗、自动驾驶和大模型后训练经常关心 offline 或接近 offline 的设置,因为真实试错成本高。
Offline RL 不是“把监督学习数据拿来做 RL”这么简单。它真正难的是:模型可能会想选数据里几乎没出现过的动作,而这些动作的 Q-value 只是神经网络外推出来的,可能虚高。
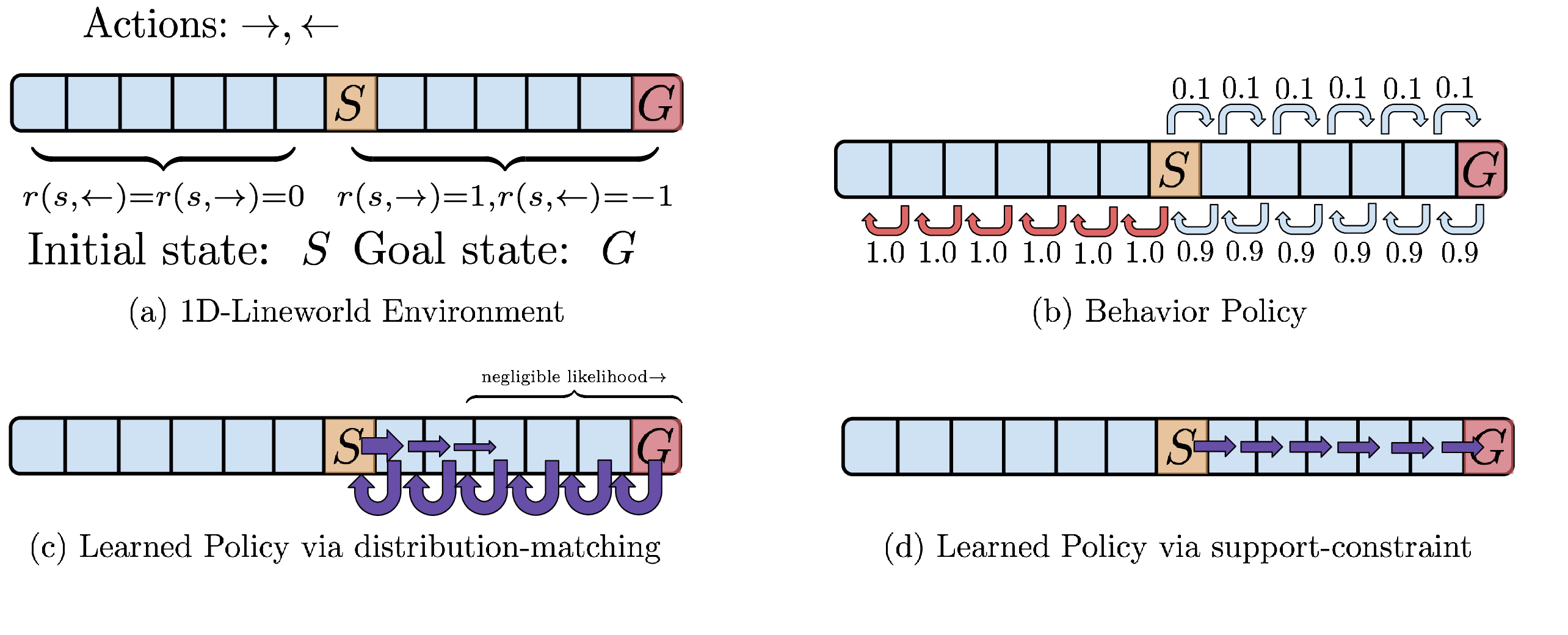
图源:Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems,Figure 4。原论文图意:用一维 lineworld 说明 distribution constraint 和 support constraint 的差别。
图里 behavior policy 很偏向向左走,但只要数据支持向右这个动作,support constraint 仍允许学习出向右到达目标的策略。distribution constraint 更像“按照数据里的概率来”,容易把低概率但正确的动作压住。对 VLA 来说,这对应一个常见矛盾:既要避免分布外危险动作,又不能把策略锁死在低质量示范的频率上。
Offline RL 也可能从不完整轨迹里拼出更好的策略。
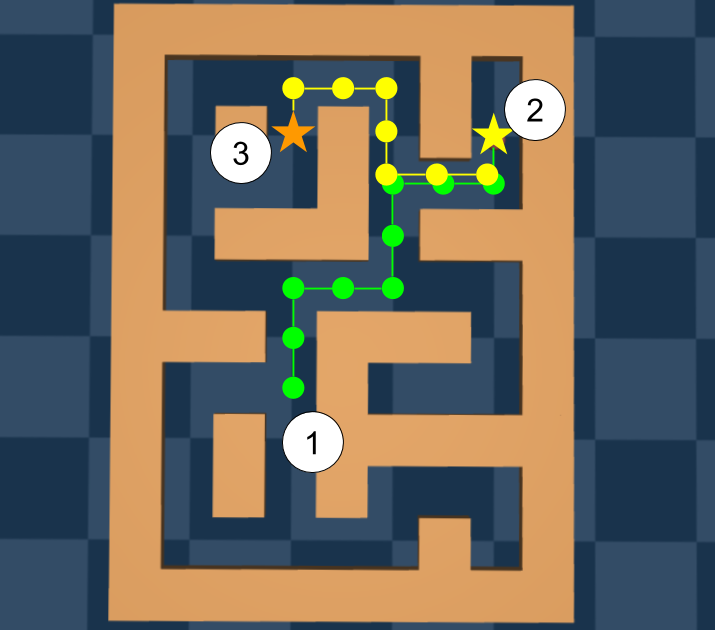
图源:Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems,Figure 6。原论文图意:展示 Maze2D 中利用轨迹组合结构找到更短路径的例子。
数据里可能没有一条完整最优轨迹,但有“从 1 到 2”的片段和“从 2 到 3”的片段。好的 offline RL 应该能把这些片段组合起来,推出从 1 到 3 的更优行为。这比行为克隆更进一步:BC 只模仿已有路径,offline RL 尝试用 Bellman/value 把片段的长期价值接起来。
10. 信用分配和探索
强化学习最难的两个问题:
| 问题 | 简洁解释 |
|---|---|
| credit assignment | 一段轨迹最后成功了,究竟是哪几个早期动作贡献最大 |
| exploration | 当前策略没试过的动作,怎么知道有没有更高回报 |
在 LLM/VLM 后训练里,credit assignment 也很明显:完整回答最后得 1 分,但哪几个 token 真的让答案正确?在机器人里更明显:任务成功可能来自前 30 秒里某个微小对齐动作。
密集奖励能降低学习难度,但也可能把模型带偏。比如只奖励“靠近杯子”,机器人可能学会把夹爪贴近杯子却不稳定抓取。好的 reward 要贴近最终任务,同时避免被策略钻空子。
11. 和世界模型的接口
世界模型本质上补上了 MDP 里的 transition:
如果还能预测 reward、done 和 risk:
就可以在模型内部做 planning 或 imagined rollout。后面的 PlaNet、Dreamer、RLVR-World 都在围绕这件事展开:用可学习模型近似环境,再把强化学习的长期优化接上去。
- Title: 强化学习:MDP、价值函数与 Bellman
- Author: Charles
- Created at : 2026-01-25 09:00:00
- Updated at : 2026-01-25 09:00:00
- Link: https://charles2530.github.io/2026/01/25/ai-files-reinforcement-learning-mdp-value-bellman/
- License: This work is licensed under CC BY-NC-SA 4.0.