
训练:集群运维与实验治理
当训练规模足够大之后,很多失败已经不再是“模型没学会”,而是“系统没组织好”。节点临时故障、对象存储抖动、sampler 状态丢失、实验配置漂移、checkpoint 写爆带宽、多个团队抢同一批 GPU,这些问题最后都会反映到训练效率、复现能力和研究迭代速度上。
这页先回答“集群运维与实验治理”在「训练」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先知道 loss、optimizer、batch、checkpoint 和评测集的基本含义。 必要时先回 训练入口、基础知识 或 术语表。
主线关系:把目标函数、数据、分布式系统、评测回流和实验治理串起来,看一次训练为什么成功、为什么不稳、为什么贵。
这页关注训练系统里经常被低估的一层:如何把昂贵训练作业组织成可启动、可恢复、可复盘、可持续优化的工程流程。它和 分布式训练与 Checkpoint、输入流水线与吞吐治理 应该一起读。
大规模训练像运营一座工厂:GPU 是生产设备,数据是原料,checkpoint 是半成品库存,实验 metadata 是生产记录。只盯着“机器有没有转”,看不到原料、工序和记录是否可靠,就很难复盘一次训练到底为什么成败。
几百张 GPU 同步训练,像一列很长的车:一个车厢掉队,整列车都要慢下来。节点健康、网络拓扑、checkpoint 写入和数据读取,看似是运维细节,实际都会改变整趟训练的到站时间。
集群治理页在“世界模型高效训练”主线里不负责提出新模型,而是负责让训练结论可信:减少失败重跑、恢复偏移、数据路径污染、无效实验和评测不可复现。它降低的是训练成本、恢复成本和评测成本;如果治理缺失,任何模型收益都可能被系统事故淹掉。
训练集群是一条生产线
训练平台不是“很多 GPU 的集合”,而是一条由调度、环境、数据、checkpoint、监控和实验元数据组成的生产线。任意一层不稳,都会让 GPU 小时变成不可解释的消耗。
| 层级 | 典型职责 | 常见失败 |
|---|---|---|
| 调度层 | gang scheduling、拓扑感知、优先级 | rank 启动不齐、拓扑碎片、排队失控 |
| 环境层 | 镜像、驱动、CUDA/NCCL、启动器 | 版本漂移、热修未记录、节点差异 |
| 数据层 | 数据快照、缓存、sampler、packing | 小文件抖动、重复样本、数据版本不明 |
| Checkpoint 层 | 写入、归档、恢复、祖先追踪 | 写爆共享存储、恢复不等价、坏 checkpoint |
| 观测层 | loss、吞吐、系统指标、事件线 | 只看到挂掉,看不到早期异常 |
| 治理层 | 成本、owner、stop criteria、postmortem | 无效实验空跑、结论不可复用 |
一个成熟训练平台的目标不是把所有作业都塞满,而是让高价值实验在可解释的成本下稳定推进。
调度先看资源画像
很多团队上来讨论调度策略,但真正应该先做资源画像。大模型训练需要的不是“若干张 GPU”,而是一组拓扑、带宽和稳定性都匹配的资源。
资源画像至少应包含 GPU 型号、显存、健康状态和历史故障,节点内 NVLink / NVSwitch 互联,跨节点网络层级和 IB 域,本地 NVMe、共享文件系统、对象存储路径,以及机架、供电、温度、坏卡和弱链路标签。
这些标签应该进入调度系统的一等元数据。TP、PP、EP 对拓扑的敏感点不同:TP 更依赖节点内高速互联,EP 更容易放大 all-to-all,checkpoint 和数据预取更依赖存储路径。若调度器只按 GPU 数量分配,同一份配置落在不同拓扑上,吞吐和稳定性都可能差很多。
训练调度还必须处理公平、效率和实验价值之间的冲突。一个实用分层是把主线大训练放进稳定的保底池,给可恢复、可抢占的探索实验留出弹性池,再用低优先级池承接夜间任务、预处理、回放和离线评测。
只追集群利用率会制造拓扑碎片和频繁抢占,最后损害的是组织整体研究效率。
启动前必须有 Preflight
昂贵训练作业的很多失败,本可以在启动前被挡住。Preflight 不应该只是启动脚本里的几行检查,而应该是一套正式的风险筛查。
| 检查项 | 要回答的问题 |
|---|---|
| 节点健康 | GPU、ECC、链路、温度、磁盘是否正常 |
| 环境版本 | 驱动、CUDA、NCCL、容器、编译器是否匹配 |
| 配置一致性 | 配方、并行参数、batch、scheduler 是否 materialize |
| 数据状态 | dataset、tokenizer、packer、sampler 版本是否固定 |
| Checkpoint | 祖先 checkpoint、优化器状态、RNG、数据游标是否兼容 |
| 显存账本 | 参数、梯度、优化器、激活、KV/缓存是否在预算内 |
| 存储路径 | 数据缓存、checkpoint 目录、临时目录是否可读写 |
配置治理的底线是:运行时实际生效配置必须被写回 metadata。只把脚本放进 git 并不够,因为真正影响结果的常常是命令行覆盖、环境变量、自动推导出的 batch、临时热修和恢复状态。
建议对破坏复现性的字段做启动前 diff 检查,尤其是 tokenizer、数据 mixture、并行拓扑、学习率日程、checkpoint 祖先和 loss 配置。
运行中看四条信号
训练监控不能只看 GPU utilization。真实排障时,至少要把损失、吞吐、系统和数据四条信号放在同一条时间线上。
| 信号层 | 关键指标 | 典型用途 |
|---|---|---|
| 损失层 | train/valid loss、loss spike、nan/inf、grad norm、LR | 判断训练是否数值异常 |
| 吞吐层 | token/s、step time、loader stall、pipeline bubble、checkpoint pause | 判断算力是否被有效使用 |
| 系统层 | GPU util、显存、网络、文件系统、对象存储、ECC、链路错误 | 判断瓶颈是否来自平台 |
| 数据层 | 数据源曝光、长度桶、坏样本率、sampler 重复/跳样、packing 异常 | 判断结论是否被数据路径污染 |
训练事故经常是跨层问题:对象存储抖动会变成 loader stall,loader stall 会变成 step time 抖动,step time 抖动又可能被误判为模型或 kernel 问题。监控系统若不能跨层关联,团队只会在错误层面反复排查。
告警也应从“作业挂了才报警”前移到早期异常。吞吐突然下跌、某些 rank step time 漂移、checkpoint 写盘延迟拉长、对象存储重试率上升、节点温度/ECC/链路错误开始变坏,或者 loss、grad norm、loader stall 与系统异常同时间出现,都应进入同一条事件线。
运行中案例:一次世界模型训练变慢该怎么判
假设一个 64 卡视频世界模型作业从第 18k step 开始变慢:
1 | step=17980 token_s=1.02M loader_stall=3% ckpt_pause=0s loss=2.31 |
如果只看 GPU utilization,可能会误判为 kernel 退化。治理面板应该把四条信号放到一张事件线上:
| 观察 | 证据 | 初步判断 |
|---|---|---|
token/s 从 1.02M 掉到 0.69M |
吞吐层告警 | 端到端训练效率下降 |
loader stall 从 3% 升到 25% |
数据层告警 | 数据输入开始阻塞 |
| 对象存储 retry 同步升高 | 系统层告警 | 很可能是存储或缓存路径问题 |
| loss 没有同步 spike | 损失层正常 | 暂不优先怀疑优化器或数值 |
| checkpoint pause 在后段升高 | Checkpoint 层告警 | 存储路径被训练数据和 checkpoint 共同踩踏 |
治理动作也要有退出条件:
| 动作 | 触发条件 | 验收 |
|---|---|---|
| 切换到本地 NVMe cache | loader stall 连续 50 step 超过 15% |
token/s 恢复到基线 90% 以上 |
| 延后 checkpoint 或改异步队列 | checkpoint pause 超过 30s |
pause 不再进入关键路径 |
| 标记本段实验为受污染 | 数据 stall 与训练曲线重叠超过 500 step |
后续评测解释中排除这段吞吐异常 |
| 开 postmortem | 单次事故浪费超过 100 GPU-hour |
playbook 增加对象存储重试阈值 |
这类案例的重点是:训练治理不是“作业慢了重启一下”,而是能把慢归因到数据、存储、checkpoint 或模型本身,并把影响写进实验证据链。否则同一个模型改动可能被错误地判成“训练 recipe 更慢”。
恢复要证明等价
训练恢复不是“重新跑起来”这么简单。团队真正需要证明的是:恢复后的训练状态与失败前的逻辑状态足够等价。
恢复流程建议固定下来:先把故障归到节点、网络、存储、数据、数值或代码,再自动回退到最近可信 checkpoint;启动前检查模型、优化器、RNG、sampler、数据游标和配置;恢复后 shadow 观察若干 step,比较 loss、吞吐和数据曝光;最后把恢复事件写入实验证据链,并对高成本失败做 postmortem。
Checkpoint 路径最好与训练数据路径分开治理。checkpoint 高峰写入、恢复时大规模读取、多个作业同时落盘,都会互相踩踏。成熟系统通常会有独立带宽策略、异步写入队列、生命周期管理和热/温/冷归档分层。
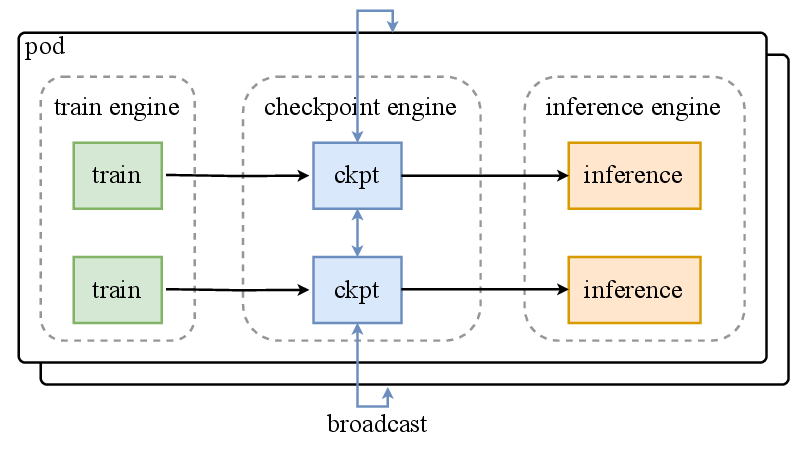
图源:Kimi K2: Open Agentic Intelligence,Figure 10。原论文图意:co-located distributed checkpoint engine 在 training engine 与 inference engine 之间管理参数状态,避免通过普通网络文件系统重新切分和广播超大模型参数。
Kimi K2 的图不是在讲“多保存几个文件”,而是在说明大规模 RL / agentic 训练里,参数更新、推理引擎、训练引擎和环境服务会形成循环。checkpoint engine 如果只被当成落盘脚本,权重同步、恢复一致性和 rollout freshness 都会成为隐形瓶颈。
算一遍:checkpoint 频率不是越高越好
假设一个 512 卡世界模型训练作业,单步 2.4s,同步 checkpoint 每次暂停 75s。如果每 500 step 存一次,训练 500 step 本身耗时 1200s,checkpoint 开销占:
如果改成每 2000 step 存一次,占比降到:
但故障恢复成本会上升。若集群平均每 10h 遇到一次会导致作业重启的故障,500 step 间隔最多丢 20min,期望丢 10min;2000 step 间隔最多丢 80min,期望丢 40min。因此真实目标是最小化:
1 | 总成本 = checkpoint 暂停成本 + 期望丢失训练成本 + 存储/带宽成本 + 恢复验证成本 |
判断链应写成:
1 | 症状:token/s 周期性下跌,训练 wall-clock 明显拉长 |
实验管理要管理证据链
实验管理不是“记日志”,而是防止自我欺骗。一个训练结论是否可信,取决于它是否能回答:这次结果到底基于什么代码、数据、配置、环境和恢复路径得来。
最小证据链应包括代码版本和镜像版本,配置文件版本与运行时实际配置,数据版本、过滤版本、mixture recipe、tokenizer 和 packer,模型结构摘要、并行拓扑、启动器参数,checkpoint 祖先、恢复事件、人工干预记录,关键指标曲线、系统告警和异常事件线,以及评测结果、产物路径和保留策略。
实验面板也应服务决策,而不是只展示曲线。它至少要帮助判断哪条训练值得继续,哪条应该尽快停掉,哪些实验可以被公平比较,性能变化更像数据问题、系统问题还是模型问题,以及哪些异常会影响最终结论。
成本治理要下钻到实验
训练成本治理如果只在月底看账单,基本无法反哺工程决策。更有用的拆法是把成本下钻到实验层和事故层。
| 成本项 | 需要记录什么 | 为什么重要 |
|---|---|---|
| 有效训练成本 | GPU 小时、有效 token、token/s | 衡量每单位训练进展的代价 |
| 失败重跑成本 | 失败次数、丢失 step、恢复耗时 | 判断平台稳定性是否值得投入 |
| 数据成本 | 预处理、缓存、对象存储读取 | 找出数据路径是否在吞预算 |
| Checkpoint 成本 | 写入耗时、存储占用、归档策略 | 避免恢复能力和存储费用失控 |
| 无效实验成本 | stop criteria、早停触发、低价值空跑 | 把研究决策和资源治理连起来 |
| 排队与碎片成本 | 等待时延、拓扑碎片、抢占损耗 | 判断调度策略是否伤害主线 |
高成本实验必须提前写清楚 owner、假设、停止条件和回滚计划。没有 stop criteria 的大训练,很容易在“也许再跑几天会好”的模糊判断里消耗大量资源。
运维闭环
一个可持续训练平台的闭环可以压缩成七步:用模板化配置创建实验;启动前做资源、拓扑、数据、checkpoint 和显存 Preflight;训练中统一观察损失、吞吐、系统和数据四条信号;故障时按可信 checkpoint 自动恢复,并验证恢复等价;结束后自动汇总元数据、成本、评测和产物;对高成本失败和高价值实验做 postmortem;最后把失败模式、告警阈值和修复动作写回 playbook。
集群运维和实验管理的价值,不在于让训练流程显得“正规”,而在于把拓扑、调度、成本、资产、告警和复盘组织成一套长期运行机制。只有这样,大模型训练平台才会从“能接作业”升级成“能持续放大研究效率”的基础设施。
- 回到本专题入口:训练,确认这页在整条路线中的位置。
- 按导航顺序继续:W&B:实验追踪与治理。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 训练:集群运维与实验治理
- Author: Charles
- Created at : 2026-01-31 09:00:00
- Updated at : 2026-01-31 09:00:00
- Link: https://charles2530.github.io/2026/01/31/ai-files-training-cluster-operations-and-experiment-management/
- License: This work is licensed under CC BY-NC-SA 4.0.