
训练:预训练、微调与对齐:把能力、行为和偏好分开看
大模型不是一次训练成“产品模型”的。预训练、监督微调和偏好对齐都在更新同一组参数,但它们给模型的监督信号完全不同:预训练让模型从海量 token 里学会世界和语言的统计结构,SFT 把能力接到可执行的任务格式上,偏好/RL 再让模型在多个可行回答之间学会选择。
把这三层混成一个词,会直接影响诊断。模型不会做数学,通常不是多加几轮拒答数据能补出来;模型会做但输出格式乱,也不一定需要重做预训练;模型啰嗦、自信过头或拒答边界怪,往往是偏好数据、reference 约束和评测口径的问题。
更稳的读法是:预训练回答“能不能”,SFT 回答“怎么做”,偏好对齐回答“更倾向选哪种做法”。
三个阶段解决三种问题
| 阶段 | 模型看到什么 | 训练信号来自哪里 | 主要塑造什么 |
|---|---|---|---|
| 预训练 | 海量文本、代码、多模态 token | 数据本身的下一个 token、masked token 或其他自监督目标 | 知识、语言、代码、表示、能力边界 |
| SFT | 指令和高质量示范回答 | 人写、专家写或强模型生成的 demonstration | 指令遵循、格式、任务流程、工具调用习惯 |
| 偏好 / RLHF | 同一 prompt 下多个候选回答 | 人类排序、AI feedback、reward model、verifier 或规则 | 风格、风险偏好、简洁度、拒答边界、可验证任务成功率 |
这张表的重点不是阶段名字,而是监督信号。预训练通常从原始数据里构造目标,SFT 用示范回答告诉模型“应该怎么写”,偏好训练则比较多个回答“哪个更好”。三者都可能用交叉熵或 policy gradient 这类优化工具,但它们在回答不同的问题。
公式里真正变的是监督对象
语言模型预训练常见目标是 next-token prediction:
是真实下一个 token, 是前文, 是模型参数。这个目标让模型在海量语料上学习“在这种上下文里,下一个 token 更可能是什么”。
SFT 也常写成交叉熵,但条件和目标变了:
是用户指令或任务输入, 是示范回答里的第 个 token。它不是重新教模型全部世界知识,而是把底座能力拉到人希望看到的交互格式里。
偏好对齐更进一步。以 RLHF 的抽象目标为例:
是当前策略模型, 是 reward model 或 verifier 给回答的分数, 是参考模型, 是不要偏离太远的约束强度。这里监督对象已经不是“标准答案 token”,而是“生成出来的回答是否更符合偏好或任务成功标准”。
所以读训练报告时,不要只问“用了什么 loss”。更该问:正样本是谁给的,负样本怎么来的,偏好标签是否一致,reward 是否可验证,reference 约束有没有保护住底座能力。
预训练塑造能力边界
预训练像给模型建立一套压缩后的世界和语言索引。GPT-3 这类语言模型用大规模 next-token 目标展示了一个事实:简单预测目标在足够数据、容量和计算下,可以诱导出广泛的语言、代码、翻译、问答和少样本能力。
但预训练 loss 低,不等于产品任务一定好。它优化的是平均 token 预测,而真实任务可能关心严格格式、长链推理、工具执行、安全边界、检索使用和交互体验。预训练打底,但不直接定义模型该如何服务某类用户。
能力短板也很难靠最后一层对齐凭空补出来。如果底座模型缺少数学推导、代码修复、长上下文跟踪或某个领域的基本知识,SFT 和 RLHF 更可能只是把它包装得更像会,而不是稳定地产生正确能力。
SFT 是行为克隆,不是魔法增强
SFT 的直觉很朴素:给模型看“好回答长什么样”。这一步通常负责指令遵循、输出格式、分步流程、工具调用模板、多轮对话习惯和领域工作流。
它的风险也来自这里。示范数据模板僵硬,模型会学得僵硬;示范数据逻辑不严谨,模型会学会漂亮但脆弱的推理外壳;示范数据覆盖窄,模型在分布外任务上会把相似格式硬套过去。LIMA 和 FLAN 这类工作都提醒我们:指令数据的质量、覆盖和组织方式,常常比“多堆一点 SFT 样本”更关键。
可以把 SFT 看成语言模型里的行为克隆。它能让底座模型进入目标任务接口,但不保证已经具备闭环恢复、真实偏好理解或安全判断。SFT 后的模型如果“会答,但不稳定”,下一层才轮到偏好数据、verifier、RL 或更细的评测体系出场。
RLHF 是先学偏好,再约束策略更新
InstructGPT 的流程图仍然是理解 RLHF 的好入口。它没有让人类逐 token 教模型,而是把“人喜欢什么回答”变成一个可训练的 reward model,再用强化学习优化 policy。
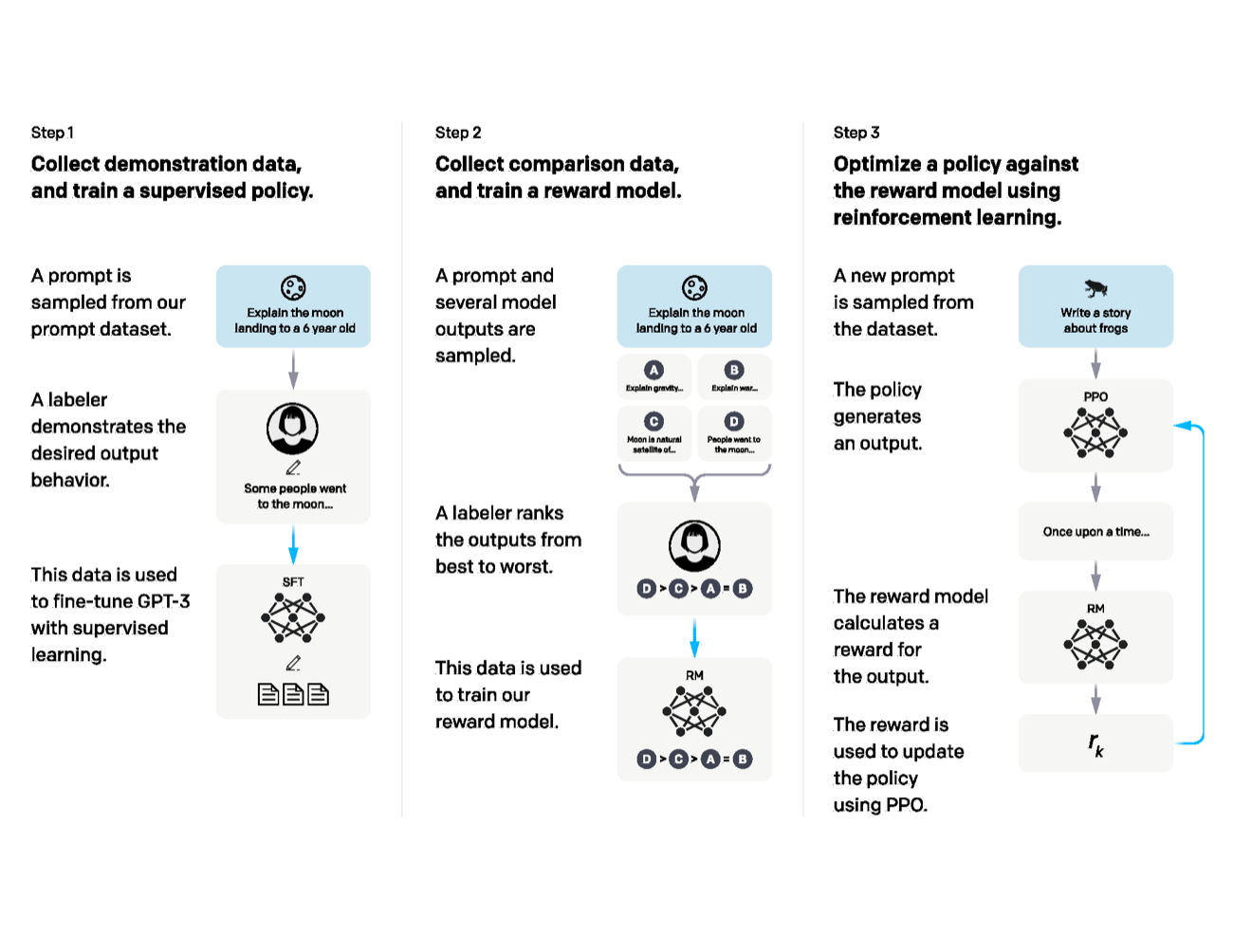
图源:Training language models to follow instructions with human feedback,Figure 2。本站复用已有论文图,未使用 image2 生成新图。原图展示三步流程:收集 demonstration data 做 SFT,收集模型输出排序训练 reward model,再用 PPO 按 reward model 优化 policy。
这三步最好分开看:
| 步骤 | 训练对象 | 信号 | 常见失败 |
|---|---|---|---|
| SFT | policy model | 高质量示范回答 | 模板化、覆盖窄、示范质量不稳 |
| Reward modeling | reward model | 同一 prompt 下候选回答排序 | 标注者偏置、候选分布窄、reward hacking |
| PPO / RL | policy model | reward、KL、value/advantage | 过度优化 reward、能力退化、长度和风格漂移 |
强化学习词表翻译到语言模型里也不复杂:prompt 加已生成前缀是 state,下一个 token 是 action,完整回答是一条 trajectory,reward model 或 verifier 给最终回答打分,reference policy 用来限制模型不要离 SFT 模型太远。
PPO 的作用是小步更新。它既让模型朝高 reward 回答移动,又通过 old policy、clip 和 KL 约束防止模型突然跑偏。放到 RLHF 里,核心含义是 reward 不能没有约束地推动模型大幅改写自身分布;否则模型可能学会 reward model 偏爱的表面格式,却牺牲事实性、能力保持和真实有用性。
RLHF 的难点从来不只是 PPO。更难的是 reward 是否真的代表目标行为,偏好数据是否覆盖长尾任务,KL 是否保护住基础能力,以及线上评测能否发现“reward 上升但用户体验下降”的情况。
DPO 等方法减少流程,但不减少数据责任
DPO 把偏好优化写成更直接的 closed-form objective,不需要显式训练 reward model 再跑 PPO。常见写法是:
是优选回答, 是劣选回答, 是参考模型。直觉是:相对参考模型,提高优选回答概率,压低劣选回答概率。
DPO、IPO、ORPO、RLAIF 和 Constitutional AI 的流程各不相同,但它们绕不开同一组数据问题:偏好维度是否拆清楚,候选回答是否有足够差异,标注指南是否一致,模型是否只学会迎合某种表面风格,安全拒答和真实有用性有没有被分开评估。
这也是为什么“对齐效果不好”不能只怪算法。很多时候,坏掉的是偏好数据设计、候选生成、judge 校准、风险分桶或线上反馈回流。
现代后训练是一条生产线
只用“预训练、SFT、对齐”三段概括今天的模型训练,已经有点太粗。Qwen3、DeepSeek-R1、SmolLM3 这类训练报告更像是在描述一条后训练生产线:先用 cold start 数据稳定格式,再用可验证奖励增强推理,再通过蒸馏、偏好、工具、RAG、安全和多模式回答把能力合回产品模型。
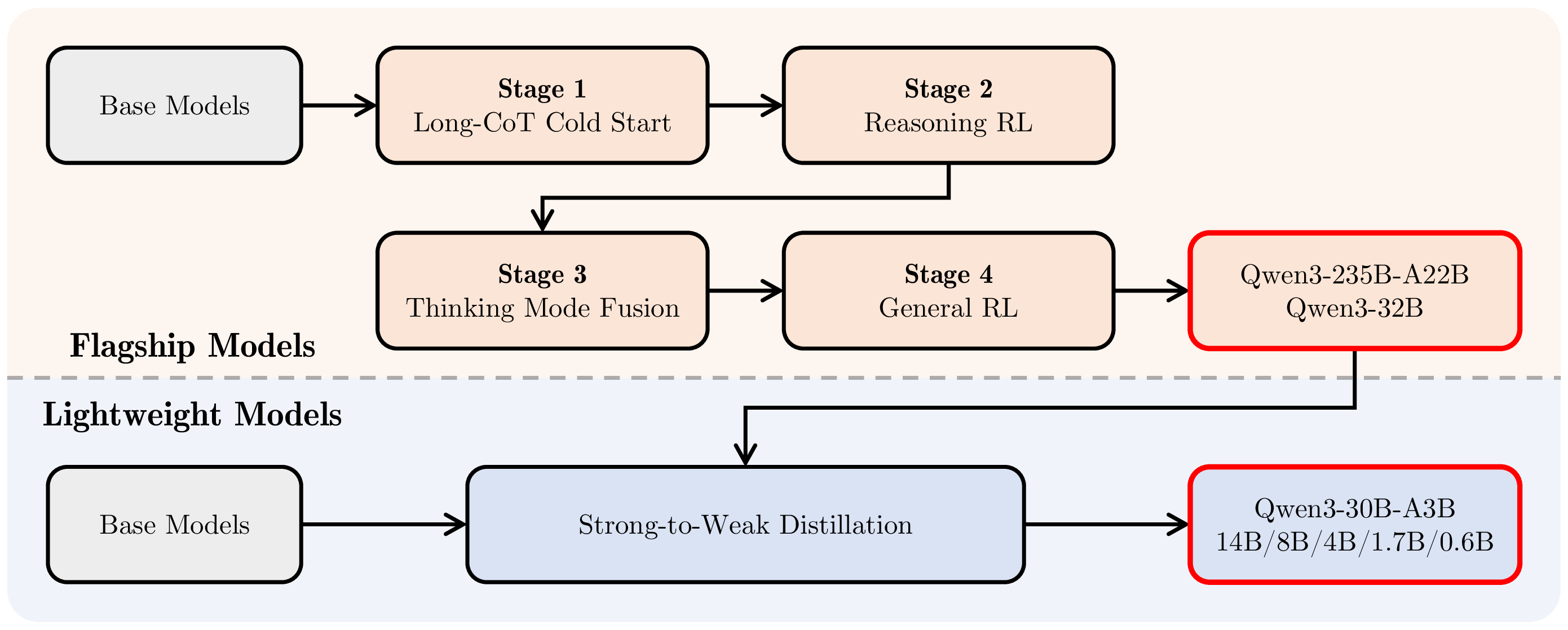
图源:Qwen3 Technical Report,Figure 1。本站复用已有论文图,未使用 image2 生成新图。原图展示 Qwen3 post-training pipeline:旗舰模型经过 Long-CoT Cold Start、Reasoning RL、Thinking Mode Fusion、General RL;轻量模型通过 strong-to-weak distillation 继承大模型能力。
这张图的价值,是把“后训练”从单个算法名词拉回生产流程。
| 工序 | 通俗理解 | 验收重点 |
|---|---|---|
| Cold start SFT | 先给模型清楚的解题范式和交互范式 | 格式稳定、推理轨迹可读、采样不过度混乱 |
| Reasoning RL / RLVR | 在数学、代码、格式检查等可验证任务上试错 | verifier 可靠性、pass rate、泛化到未见题型 |
| Thinking mode fusion | 把长思考和短回答合到同一模型 | 何时深想、何时直接答、成本与体验 |
| General RL / preference | 修工具、风格、安全、拒答和真实任务偏好 | 分桶胜率、风险边界、事实性退化 |
| Distillation | 把强模型的行为和轨迹压给小模型 | 小模型是否继承流程,而不只是背答案 |
DeepSeek-R1 的 GRPO/RLVR 路线也说明了类似趋势:当 reward 足够可验证,RL 可以不只做“更像助手”,还可以推动模型探索更强的推理策略。但这类收益依赖任务是否能被可靠验证;一旦 reward 来自含糊偏好或不稳 judge,训练仍会回到 reward hacking 和分布漂移问题。
问题归因先看哪一层坏了
| 线上症状 | 更可能的问题层 | 优先检查 |
|---|---|---|
| 基础知识、数学、代码能力弱 | 预训练 / 继续训练 | 数据覆盖、token budget、训练稳定性、污染与能力评测 |
| 不会按格式输出、不会跟流程 | SFT | demonstration 质量、任务覆盖、模板多样性 |
| 会做但风格差、啰嗦、自信过头 | 偏好 / reward | 偏好维度、长度偏置、reference 约束、judge 校准 |
| 拒答边界怪,安全过松或过紧 | 安全对齐 / 策略 | 风险分类、拒答数据、允许帮助的替代路径 |
| 工具调用流程不稳 | SFT + RL + 工具评测 | 调用轨迹、错误恢复、schema 检查、真实执行反馈 |
| 长上下文丢信息 | 预训练 + 推理系统 | 长上下文数据、位置编码、packing、KV/cache 策略 |
| 私域知识不足 | 数据或检索接口 | 继续训练、RAG 覆盖、权限、引用和更新机制 |
这个表不是为了替团队省掉排查,而是为了避免“所有问题都在最后一层对齐里打补丁”。成熟的训练系统应该保留跨阶段追踪表:底座来源、数据版本、SFT 配方、偏好数据版本、reference model、RL 超参、评测版本、已知退化项和回滚条件。
一次训练路线怎样验收
每个阶段都要有自己的验收指标,跨阶段还要有能力保持检查。
| 阶段 | 不够的证据 | 更有用的证据 |
|---|---|---|
| 预训练 | 只看平均 loss | 按领域/语言/长度/代码/数学分桶的 loss 和下游能力曲线 |
| SFT | 只看训练集 loss | 指令遵循、格式稳定、长尾任务、人工抽检、模板污染检查 |
| 偏好/RL | 只看 reward 上升 | held-out 人审、分桶胜率、KL、长度、事实性、安全边界和退化集 |
| 后训练流水线 | 只看最终榜单 | 每个阶段的 anchor eval、数据版本、失败样本回流和恢复一致性 |
评测最好不要只是一张榜单。公共 benchmark 用来对齐外部口径,内部任务集覆盖真实产品目标,长尾失败集记录高价值事故,线上回流挑战集来自真实用户问题,不可触碰 holdout 防止长期调参污染。对齐越靠近产品,越需要按风险等级、用户群、语言、任务类型和回答长度分桶看结果。
最后判断
预训练、SFT 和偏好对齐可以按四句话记:
- 预训练塑造能力边界;底座不会的东西,后训练很难凭空造出来。
- SFT 塑造行为格式;示范数据的质量和覆盖决定模型像不像“会做这类任务”。
- 偏好/RL 塑造选择倾向;reward、reference 和评测分桶决定模型是否真的更有用。
- 现代后训练是一条数据生产线;算法只是最后一层,样本发现、judge 校准、可验证奖励、蒸馏和回归治理同样关键。
继续往下读,可以接 目标函数、优化器与 LR 日程、偏好数据与对齐失效、训练评测与消融设计 和 后训练数据引擎与 Judge 模型。
外部精读
- InstructGPT:理解 demonstration、reward model 和 PPO 三步 RLHF。
- PPO:理解 clipped surrogate 为什么是“小步更新”。
- DPO:理解不用显式 reward model 的偏好优化入口。
- LIMA 与 FLAN:理解指令数据质量、覆盖和行为格式的重要性。
- DeepSeek-R1 与 Qwen3:理解现代后训练如何把 cold start、RLVR、distillation 和 general RL 串成流水线。
- Hugging Face RLHF blog:适合作为英文直觉入口;事实和实验 claim 仍回到论文与技术报告核对。
- Title: 训练:预训练、微调与对齐:把能力、行为和偏好分开看
- Author: Charles
- Created at : 2026-02-01 09:00:00
- Updated at : 2026-02-01 09:00:00
- Link: https://charles2530.github.io/2026/02/01/ai-files-training-pretraining-finetuning-alignment/
- License: This work is licensed under CC BY-NC-SA 4.0.