
基础知识:数据与数据集基础:模型真正吃下去的不是“文件夹”
这篇文章只回答一个问题:读到“我们用某数据集训练/评测”时,怎样判断这个结论是不是可信。
数据集不是一个目录、一张表或若干 JSONL。它是一组样本定义、标签规则、来源记录、processor、split、过滤和版本共同构成的训练契约。只要契约说不清,后面的 loss、benchmark 和训练曲线都可能在回答错误问题。
样本不是一行数据,而是一份契约
一个样本可以先写成:
这行式子在说:第 个样本不只有输入 和目标 ,还应该有 metadata 与 provenance / rights 。 记录来源、时间、语言、设备、任务、标注者、机器人、场景等信息; 记录许可、采集边界、可否商用、可否公开、是否包含敏感信息。
不同任务里,这四项长得不一样:
| 场景 | 输入 | 目标 | 为什么重要 |
|---|---|---|---|
| 分类 | 文本、图像或表格 | 类别 | 可以按来源、类别、时间、设备分桶看错因 |
| LLM 预训练 | token 序列前缀 | 下一个 token | 来源和时间决定知识覆盖、污染和重复 |
| SFT | 指令和上下文 | 示范回答 | 任务类型、语言、难度、风格会被模型一起学走 |
| 偏好数据 | 同题多个回答 | 排序或胜负 | 标注者偏好、rubric 和冲突样本决定 reward 边界 |
| RAG 文档 | 文档片段 | 可检索证据 | URL、版本、时间戳和章节层级决定引用是否可信 |
| 机器人轨迹 | 观测、状态、语言目标 | 动作序列或成功信号 | 机器人、相机、频率、坐标系决定动作是否可迁移 |
很多“数据质量”问题,其实是样本契约不完整:标签不知道怎么来的,split 不知道怎么切的,metadata 不足以解释失败,数据版本无法复现,许可和使用边界也没写清。
标签不是事实,而是训练信号
标签常被写成 ground truth,但它更准确地说是训练信号。它可以来自人工标注、规则生成、环境 reward、用户点击、模型伪标签、下一个 token 或同题回答排序。来源不同,含义完全不同。
| 标签来源 | 它告诉模型什么 | 风险 |
|---|---|---|
| 人工标注 | 人按说明书做出的判断 | 标注规范含糊、标注者不一致、文化偏差 |
| 规则标签 | 代码或业务规则的输出 | 规则错会规模化复制,边界样本可能被硬切 |
| 自监督目标 | 从数据本身构造目标,如 next-token、mask prediction | 学到的是分布相关性,不等于学会真实因果 |
| 偏好排序 | 哪个回答更符合人类偏好 | 偏好可能奖励啰嗦、讨好或格式模板 |
| 环境 reward | 动作是否成功、得分多少 | reward 稀疏或代理目标错,会诱导捷径 |
| 伪标签 | teacher model 生成的标签 | teacher 的幻觉、拒答风格和偏见会被学生继承 |
所以读训练数据时,不要只问“有多少条”,要问“这些标签在教什么”。一个问答数据集如果答案来自检索摘要,它在教证据整合;如果答案来自强模型,它在教 teacher 的风格和盲点;如果答案来自用户点赞,它还混入了界面、用户群体和推荐策略的选择偏差。
Processor 会改变模型看见的世界
原始数据进入模型前,一定经过 processor。它可能叫 tokenizer、image processor、video sampler、audio tokenizer、document chunker、robot data loader,也可能藏在训练脚本里。
1 | raw source |
这条链路不是中性搬运,而是在改变分布。文本归一化会处理大小写、繁简、emoji 和乱码;图像 resize/crop 可能删掉小字和边缘物体;视频抽帧可能错过短动作;RAG chunking 会决定一句话和它的上下文能不能一起被检索;机器人数据同步会决定某个动作到底对应哪一帧视觉观测。
一个数据版本应该同时记录:
| 版本对象 | 为什么必须记录 |
|---|---|
| raw data snapshot | 证明原始来源和时间 |
| cleaning/filter code | 解释哪些样本被删掉,为什么删 |
| tokenizer / processor | 同一文本或图像可能被切成不同 token/patch |
| split rule | 证明 train、validation、test 的边界 |
| packing / sampling policy | 影响长度分布、batch 组成和训练吞吐 |
| license / risk policy | 决定数据能否用于目标产品或公开模型 |
只记录训练代码版本不够。模型吃进去的是“代码 + 数据快照 + processor + split + 采样策略”的组合。
Split 和泄漏决定评测有没有意义
最常见的数据幻觉是:模型在评测集上表现很好,但它其实在训练中见过相同或近似内容。
理想情况下,训练集和测试集的相关内容重叠应尽量低:
这里 NearDuplicate 不只是完全相同字符串。它包括同一道题的改写、网页镜像、PDF 转写、代码仓库 fork、同一视频切片、同一机器人轨迹的相邻片段、同一患者或同一设备的重复记录。只做 exact match 去重,通常挡不住这些污染。
不同任务应该用不同 split:
| Split 方式 | 适合场景 | 能防什么 |
|---|---|---|
| 随机切分 | 独立同分布、样本互不关联的基础任务 | 基础过拟合 |
| 按实体切分 | 用户、患者、商品、机器人、场景 | 同一实体泄漏 |
| 按时间切分 | 新闻、网页、产品规则、线上日志 | 未来信息泄漏和时间漂移 |
| 按来源切分 | 网站、题库、数据供应商、相机设备 | 来源模板泄漏 |
| 按轨迹切分 | 视频、机器人、驾驶、RL | 相邻片段泄漏 |
| 隐藏 holdout | 长期模型迭代 | 团队反复调参把 test 调穿 |
读 benchmark 时,要特别警惕“随机切分 + 高相似样本”。如果同一网页的不同段落、同一题库的变体或同一机器人轨迹的相邻窗口同时进 train/test,模型看起来像泛化,实际是在复述邻近样本。
清洗、去重和过滤会改变数据分布
清洗不是把数据变干净这么简单。它是在决定哪些信号被保留,哪些信号被删除。
| 操作 | 想解决什么 | 可能伤害什么 |
|---|---|---|
| 乱码/坏文件过滤 | 防止无效样本污染训练 | 可能误删小语种、特殊格式或真实长尾 |
| 低质网页过滤 | 提升平均可读性 | 可能把论坛、口语、领域文档删掉 |
| 去重 | 防止重复内容主导 loss,减少评测污染 | 可能删掉合法重复模板或稀有格式 |
| 安全过滤 | 降低敏感/违法/高风险内容 | 可能产生选择偏差,影响模型理解边界 |
| 长度过滤 | 控制训练吞吐和上下文成本 | 可能删掉长文档、长推理和长时任务 |
| 质量打分过滤 | 保留高质量样本 | scorer 的偏好会变成数据偏好 |
大规模预训练数据报告,如 The Pile、Dolma、FineWeb 和 DataComp,最值得学习的不是某个数据量数字,而是它们会详细说明来源混合、过滤规则、去重、benchmark contamination 检查和数据版本。数据越大,越不能只看 total tokens;要看 mixture、质量、重复、污染和覆盖。
Mixture 会直接改变训练目标。假设数据来自 个来源,第 类来源权重是 ,训练目标可以粗略理解成:
这行式子在说:模型不是在学习一个抽象的“互联网”,而是在按 mixture 权重学习不同来源的加权平均。代码、数学、网页、论文、论坛、多语言、指令数据、机器人轨迹各占多少,决定模型会把哪类模式当成常态。
Metadata 和数据卡让失败可追踪
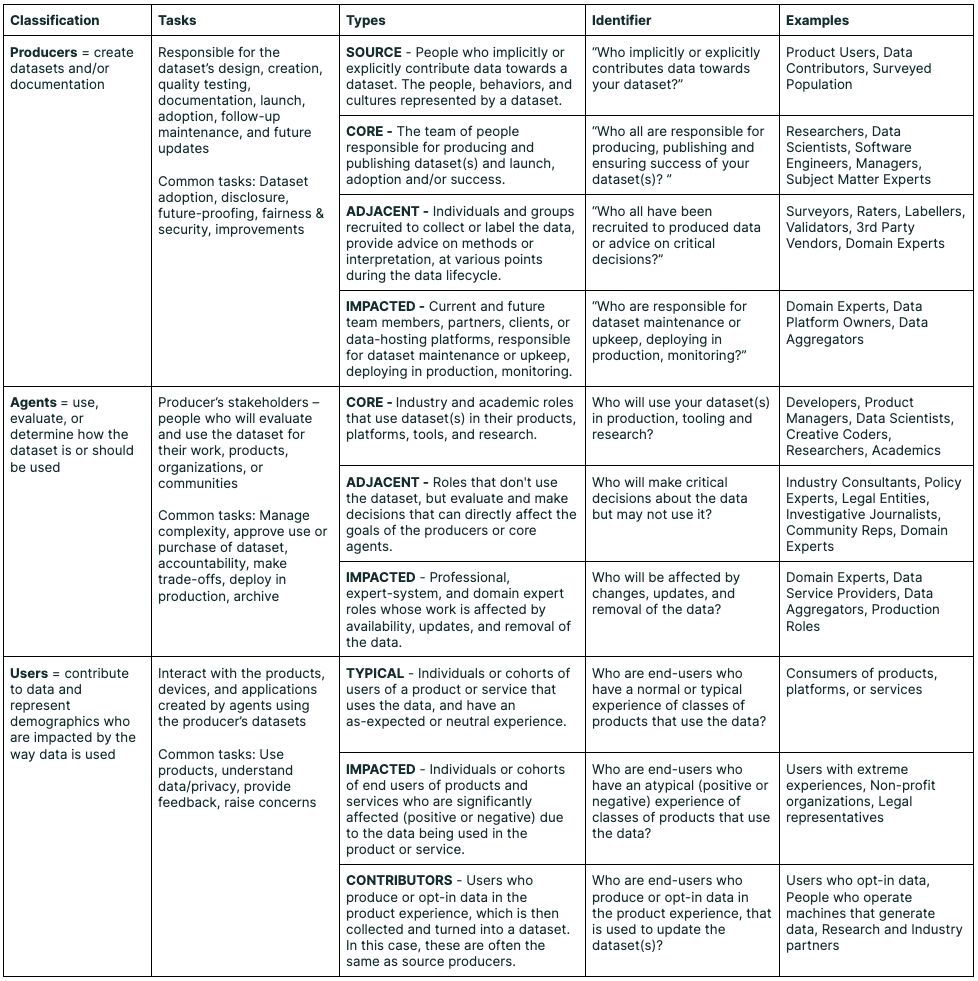
图源:Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI,Typology table。原图把 dataset 文档相关角色分为 producers、agents 和 users。本站用这张图说明:数据文档不是附录礼仪,而是让不同角色能追问来源、用途、风险、评测和影响的共同接口。
Datasheets for Datasets 和 Data Cards 的共同思想是:数据集应该像模型和硬件一样有文档。基础阶段至少要能回答这些问题:
| 问题 | 最小记录 |
|---|---|
| 数据从哪里来 | 来源、采集时间、许可、采集设备、地理/语言/场景范围 |
| 样本是什么 | 输入、目标、metadata、单位、shape、时间窗口 |
| 标签怎么来 | 人工、规则、模型、环境 reward、偏好排序、伪标签 |
| 怎么切分 | split 规则、entity/time/source/trajectory 边界、holdout |
| 怎么清洗 | 过滤规则、去重方法、删除比例、已知误删风险 |
| 怎么使用 | 推荐用途、禁止用途、已知偏差、高风险人群或场景 |
| 当前版本 | raw snapshot、processor、tokenizer、schema、数据代码版本 |
没有 metadata,平均分就很难解释。你不知道错误集中在哪个来源、哪种语言、哪个设备、哪个时间段、哪个任务难度,也不知道新模型提升到底来自真正能力提升,还是来自某个大桶样本被优化得更好。
具身数据的样本边界更长
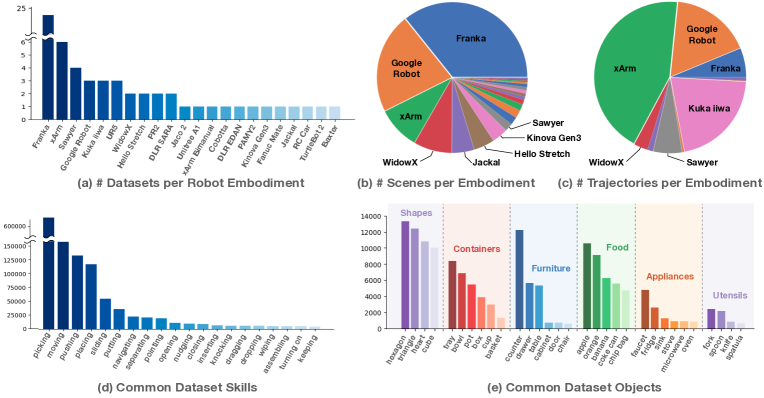
图源:Open X-Embodiment: Robotic Learning Datasets and RT-X Models,Figure 1。原图统计 Open X-Embodiment 中 robot embodiment、scene、trajectory、skill 和 object category 的分布。本站用这张图说明:机器人数据的样本不是单张图,而是跨机器人、场景、物体、技能和动作接口的轨迹分布。
机器人/VLA 数据里,一个样本常常是一段轨迹:
这里 是第 步观测,可能包含多相机图像、深度、语言目标、关节状态和 gripper 状态; 是动作,可能是末端位姿增量、关节控制、离散 action token 或 action chunk; 记录机器人类型、相机标定、控制频率、任务、场景、成功信号和采集策略。
具身数据难在三件事:
| 难点 | 为什么影响训练 |
|---|---|
| embodiment 不同 | 同一句“向前移动”在不同机器人上对应不同坐标和控制接口 |
| 时间对齐困难 | 视觉、状态和动作频率不同,错半拍就会学到错误因果 |
| 分布外恢复缺失 | 专家轨迹大多在成功路径上,部署偏离后模型不知道如何回正 |
所以 VLA 数据不能只看“多少条轨迹”。要看机器人种类、任务覆盖、失败样本、near-miss、动作接口、控制频率、相机视角、标定质量和 closed-loop 评测。只把轨迹压成“图片 + 文本标签”,会丢掉决定动作成败的接口信息。
读数据报告时真正要抓什么
读一篇模型报告的数据部分,可以按一条主线判断:
| 报告写法 | 应该追问 |
|---|---|
| 使用了 N tokens / N samples | 来源 mixture、去重比例、质量过滤和版本是什么 |
| 使用公开数据集 | split 是否防近重复、是否有 benchmark contamination 检查 |
| 使用合成数据 | teacher 是谁,过滤器是什么,失败样本怎么处理 |
| 使用高质量数据 | 质量 scorer 的定义是什么,会不会偏向某种格式或语言 |
| 使用机器人数据 | 轨迹 schema、动作接口、时间同步和 closed-loop 证据是什么 |
| 评测提升 | 提升来自整体能力,还是某个数据桶、模板或污染 |
数据页最重要的结论很朴素:不要先相信“数据更多”,先问“数据是什么”。如果样本、标签、processor、split、去重、metadata、版本和使用边界说不清,训练曲线越漂亮,越可能只是把问题藏得更深。
外部精读
- Datasheets for Datasets:理解为什么数据集需要系统文档。
- Data Cards:学习数据文档如何服务 producers、agents 和 users。
- The Pile:看大规模语言数据 mixture、去重和污染检查。
- Dolma:看开放预训练语料如何记录来源、过滤、去重和版本。
- FineWeb:看网页语料处理、去重和质量过滤的工程化讲法。
- DataComp:理解数据过滤策略本身也可以成为 benchmark。
- Open X-Embodiment:理解机器人数据里的 embodiment、轨迹、动作接口和跨数据集异质性。
相关阅读与下一步
- 外部材料:The Illustrated Transformer。
- 外部材料:Dive into Deep Learning。
- 外部材料:Distill Circuits。
- 站内下一步:基础概念专题。
- 站内下一步:Transformer 输入与注意力。
- 站内下一步:数值、内存与运行时基础。
- Title: 基础知识:数据与数据集基础:模型真正吃下去的不是“文件夹”
- Author: Charles
- Created at : 2026-04-19 09:00:00
- Updated at : 2026-04-19 09:00:00
- Link: https://charles2530.github.io/2026/04/19/ai-files-foundations-data-and-dataset-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.