
Claim Ledger:世界模型高效训练证据账
这页是全站证据账,用来记录“某个说法到底由什么证据支撑、是否可复现、不能外推到哪里”。它不替代正文,也不替代论文精读;它的作用是防止把论文实验、官方 demo、系统吞吐、闭环结果和本站工程推断混成同一种可信度。
证据类型固定使用:Paper Result、Ablation、System Throughput、Closed-loop、Official Demo、Toy Fixture、Site Inference。
复现状态固定使用:Independent Reproduced、Author Code / Official Repo、Paper Only、Official Demo、Site Inference、Toy Fixture。没有第三方复现证据时,不写成 Independent Reproduced。
核心 Claim Ledger
| Claim | Direct Source | Figure/Table/Setting | Evidence Type | Repro Status | Can Support | Cannot Prove |
|---|---|---|---|---|---|---|
| DreamerV3 的 RSSM + imagined actor-critic 是样本效率强的 model-based RL 基线 | DreamerV3 | Figure 3(a)/(b), Figure 6 | Paper Result | Paper Only | latent dynamics、reward/continue prediction 和 imagination 可在多任务 benchmark 中服务控制 | 高分辨率视频世界模型、真实机器人长任务或任意 VLA 都会同样受益 |
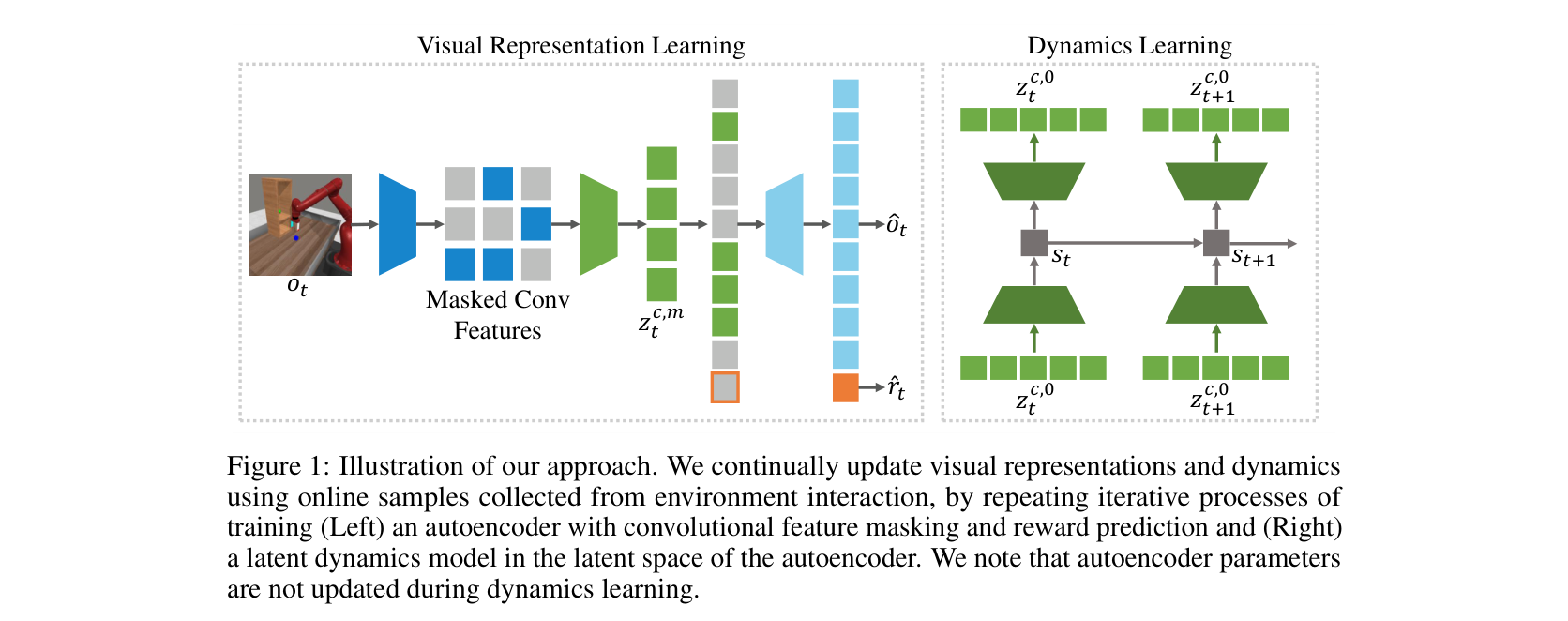
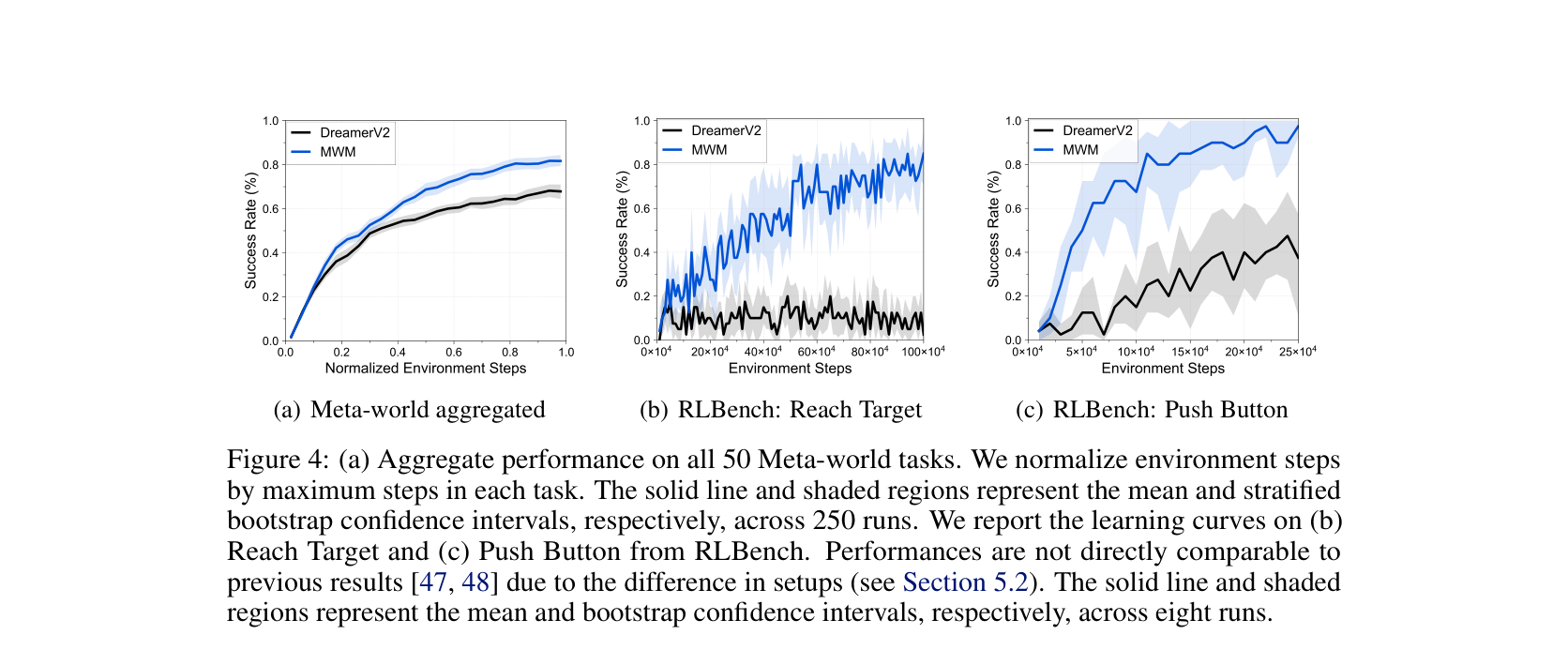
| Masked World Models 通过 decoupled visual representation + latent dynamics 改善视觉控制样本效率 | MWM | Figure 1, Figure 4; Meta-world / RLBench | Paper Result | Paper Only | masked feature learning 能在论文设置中提高 visual control 学习曲线 | masked reconstruction 本身已经具备完整动作因果、reward/done 或任意 closed-loop 泛化 |
| V-JEPA 的 joint-embedding latent prediction 可减少像素重建冗余 | V-JEPA | Figure 3, Table 1, Table 4, Table 5 | Ablation | Paper Only | latent target prediction 是高效视频表征预训练路线 | 原始 V-JEPA 已经是可规划世界模型 |
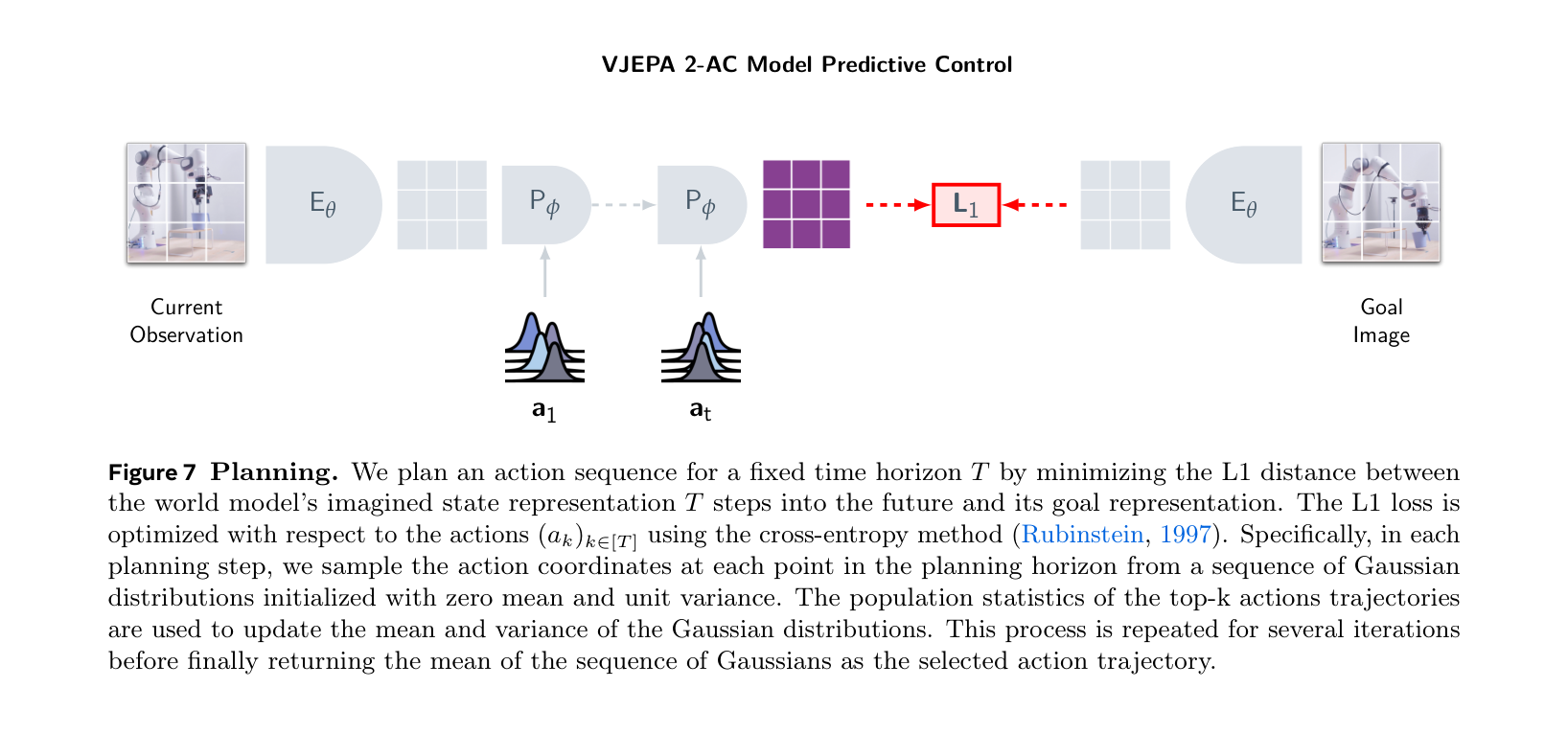
| V-JEPA 2-AC 把 JEPA 表征接到 action-conditioned latent planning | V-JEPA 2 | Figure 7, Table 3; robot planning setting | Closed-loop | Paper Only | 论文实验支持表征空间 MPC 在特定机器人任务和目标图像设置下可工作 | 跨平台通用控制、长时风险规划和真实部署安全性 |
| LingBot-World 展示了视频生成底座继续训练成可交互世界模拟器的系统路线 | LingBot-World, GitHub | Figure 4/5/6/12; official demos | Official Demo | Author Code / Official Repo | 官方 claim、开源接口和论文实验可支持“动作注入、因果化、长时记忆是视频世界模型工程路线” | 不能单独证明通用 closed-loop robot/control utility;未独立复现 |
| DreamZero / WAM 通过 joint video-action prediction 把世界模型推向可执行 policy | DreamZero | Figure 1/2/4/5/14; robot eval tables | Closed-loop | Paper Only | 论文实验支持 WAM 在特定机器人任务中有 zero-shot / post-training 控制潜力 | 不证明 WAM 是通用 VLA 替代品;未独立复现 |
| CausVid 将 bidirectional video diffusion 蒸馏为 causal student,可降低 streaming rollout 步数和延迟 | CausVid 专题 | Figure 1/5, latency table; paper setting | Paper Result | Author Code / Official Repo | 支持“少步化 + 因果化”是视频世界模型实时化方向 | 视频延迟下降不等于 planning utility 或真实闭环成功率 |
| MagiAttention 在异构 mask 长上下文训练中降低通信和负载不均成本 | MagiAttention docs, GitHub | Official CP benchmark, AttnSlice / dispatch / overlap | System Throughput | Author Code / Official Repo | 官方 benchmark 支持 mask-aware dispatch、AttnSlice 和 overlap 对长上下文训练有系统价值 | 不证明世界模型 dynamics 更准确,也不证明下游控制更好 |
| Depth Anything 3 提供多视角几何状态层,可服务世界模型的 state / geometry 接口 | Depth Anything 3, GitHub | Figure 1/2/10; project repo | Paper Result | Author Code / Official Repo | depth、ray、camera 与 3D geometry 可以作为机器人/驾驶世界模型的状态底座 | 几何估计不等于动作动力学、接触建模或策略安全;未独立复现 |
| KVSlimmer 的 asymmetric KV merging 可降低长上下文推理显存和 decoder 开销 | KVSlimmer, GitHub | Table 1/2, Figure 4/5/6 | System Throughput | Author Code / Official Repo | 推理阶段 KV 压缩可服务长历史 agent / VLA / world model rollout 成本控制 | 不证明世界模型记忆压缩后仍保留动作分叉和风险判断;未独立复现 |
| 本仓库 mini-chain 可暴露 action sensitivity 和 candidate ranking 的失败 | 完整实验报告样例 | episodes.jsonl, rollouts.jsonl, eval_mini_chain.py |
Toy Fixture | Toy Fixture | 能说明世界模型证据链应包含日志、rollout、指标和失败回放 | 不是任何真实模型或论文方法的有效性证明 |
| “Masked / JEPA 表征适合作为世界模型前置状态层”是工程归纳 | Masked / JEPA 与潜变量预测 | 机制对照与失败边界 | Site Inference | Site Inference | 可作为“先压缩,再建模动作”的工程路径 | 单独替代 RSSM、reward head、risk head 或 closed-loop 评测 |
Figure Register
| Figure / Table | Source | Evidence Type | Repro Status | Can Support | Cannot Prove |
|---|---|---|---|---|---|
| DreamerV3 Figure 3(a)/(b) | DreamerV3 专题 | Paper Result | Paper Only | world model learning 与 actor-critic imagination 的接口分工 | 视频模拟器可直接规划 |
| MWM Figure 1 | MWM Figure 1 | Paper Result | Paper Only | decoupled representation learning 与 latent dynamics 的接口 | MWM 在所有视觉控制任务上稳定优于其它方法 |
| MWM Figure 4 | MWM Figure 4 | Paper Result | Paper Only | 论文设置下的样本效率比较 | 真实机器人闭环或任意动作空间泛化 |
| V-JEPA Figure 2/3/4 | V-JEPA 专题 | Ablation | Paper Only | latent prediction 表征训练机制 | action-conditioned planning 能力 |
| V-JEPA 2 Figure 7 / Table 3 | V-JEPA 2 planning 图 | Closed-loop | Paper Only | action-conditioned latent rollout 如何接目标图像规划 | 长时真实部署和跨平台通用性 |
| LingBot-World Figure 4/5/6/12 | LingBot-World 专题 | Official Demo | Author Code / Official Repo | 视频底座、动作注入、因果化和长时记忆的系统结构 | 闭环控制收益和真实机器人安全性 |
| DreamZero Figure 1/2/4/5/14 | DreamZero 专题 | Closed-loop | Paper Only | WAM、joint video-action prediction、KV refresh 和少步策略的论文证据 | 通用 policy 替代和未见硬件安全性 |
| MagiAttention Figure 1/3/4/6/9 | MagiAttention 专题 | System Throughput | Author Code / Official Repo | 异构 mask、AttnSlice、dispatch 和 overlap 的系统机制 | 世界模型预测质量 |
| CausVid Figure 1/5 与延迟表 | CausVid 专题 | Paper Result | Author Code / Official Repo | causal student、DMD 少步化和 streaming rollout 机制 | 任务级规划收益 |
| Depth Anything 3 Figure 1/2/10 | Depth Anything 3 专题 | Paper Result | Author Code / Official Repo | 几何状态层如何服务 perception/state interface | 动作策略和动力学预测 |
{kind=link}
{kind=link}
{kind=link}
使用规则
- 如果一页声称“高效”,必须回到这里或正文
Claim Ledger说明证据类型与复现状态。 - 如果证据来自
Official Demo,只允许支撑“系统展示了某种能力或方向”,不能直接推成 closed-loop 成功率。 - 如果证据来自
System Throughput,只能证明系统成本改善,不能自动证明 world model 预测更准。 - 如果证据是
Site Inference,必须写清推断链路,并在前沿论文尚未独立复现时保留边界。 - 如果没有第三方复现实验,不要使用
Independent Reproduced。
- Title: Claim Ledger:世界模型高效训练证据账
- Author: Charles
- Created at : 2026-04-26 09:00:00
- Updated at : 2026-04-26 09:00:00
- Link: https://charles2530.github.io/2026/04/26/ai-files-references-claim-ledger/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments