
论文专题讲解:VO-DP:RGB-only 扩散策略怎样借用语义和几何特征
论文题名: VO-DP: Semantic-Geometric Adaptive Diffusion Policy for Vision-Only Robotic Manipulation。
作者: Zehao Ni、Yonghao He、Lingfeng Qian、Jilei Mao、Fa Fu、Wei Sui、Hu Su、Junran Peng、Zhipeng Wang、Bin He。
机构: National Key Laboratory of Autonomous Intelligent Unmanned Systems、University of Science and Technology Beijing、State Key Laboratory of Multimodal Artificial Intelligence System (MAIS)、Institute of Automation of Chinese Academy of Sciences。
时间 / 主题: 2025-10;具身智能。
arXiv / 官方报告: arXiv:2510.15530;官方材料:d-robotics-ai-lab.github.io/vodp/。
GitHub / 项目: GitHub:github.com/D-Robotics-AI-Lab/DRRM;项目页:d-robotics-ai-lab.github.io/vodp/。
元数据来源与核验口径: 来源:arXiv;GitHub API / repo;官方 / 项目材料;Checked Date:2026-06-04;Repro Status:Paper / official materials reviewed, independent reproduction not claimed。
VO-DP 这篇论文要回答一个很工程的问题:机器人 manipulation policy 一定要用点云或 RGB-D 才能学到几何吗?
论文的答案是:不一定。如果 RGB 图像经过足够强的预训练视觉基础模型,policy 可以从中间特征里拿到语义和几何线索,再用扩散策略生成动作。VO-DP 的“Vision-Only”不是说机器人完全没有状态,也不是说几何不重要;它指的是视觉输入只用单视角 RGB,不依赖 depth、RGB-D 或 point cloud。
一句话核心
VO-DP 把 policy 写成:
其中 是历史 RGB 图像, 是机器人关节或本体状态, 是任务条件, 是未来动作序列。这里要读清楚:它不是纯图像到动作的黑箱;它仍然使用机器人状态,只是视觉几何不再来自显式点云。
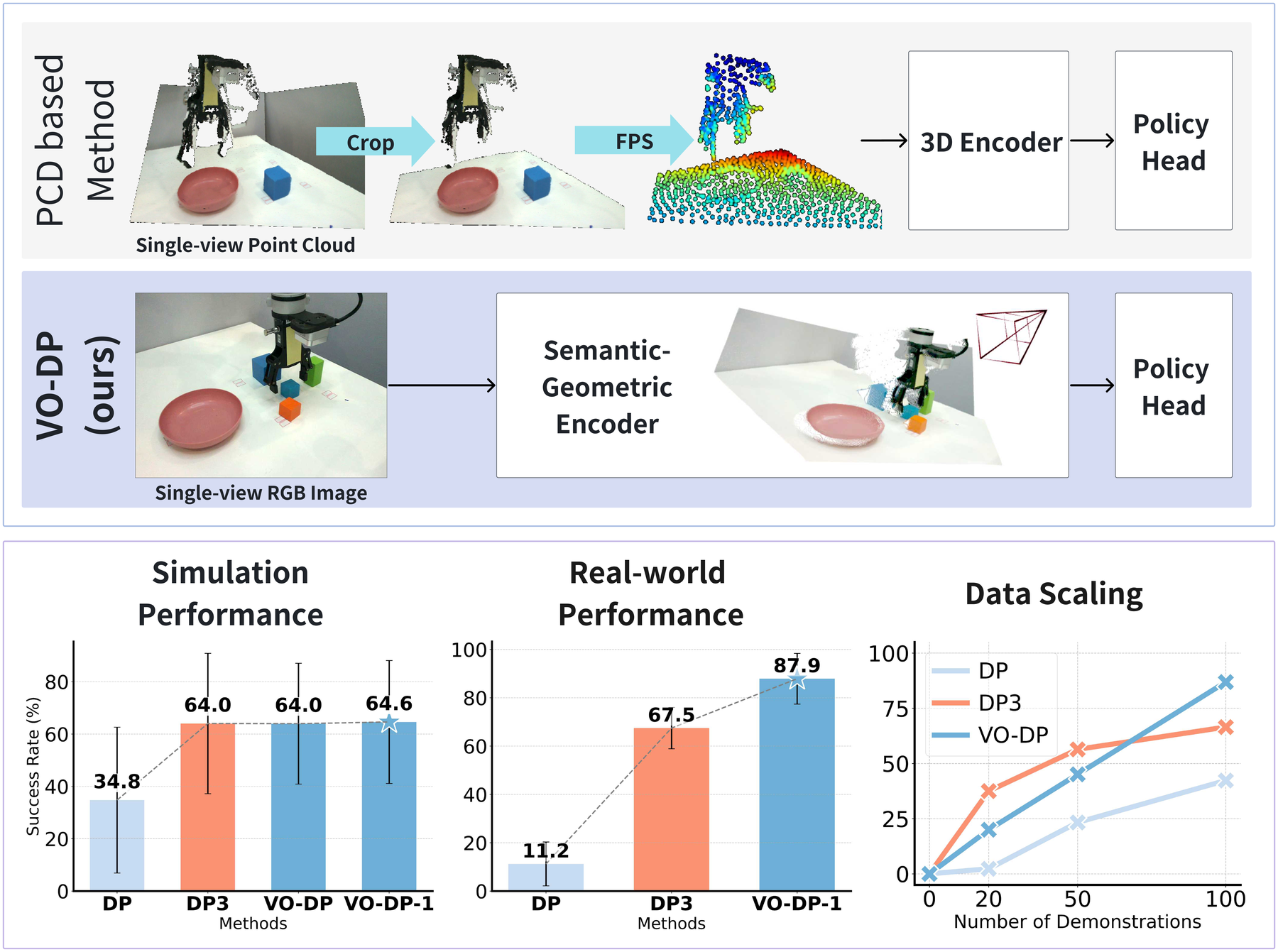
图源:VO-DP,Figure 1。原图表达单视角 RGB policy 通过预训练视觉模型获得语义和几何特征,并在仿真与真实机器人中对比 DP、DP3。本站读法:重点看 RGB-only 的部署链路更短,但并没有取消几何,只是把几何藏进特征里。
为什么点云强,但不总是好部署
点云 policy 的优势很直观:3D 坐标让机器人更容易理解物体位置、桌面高度和抓取空间。DP3 这类方法在仿真中很强,因为仿真点云干净、标定准确、遮挡可控。
真实机器人里问题会变复杂。深度相机受光照、反射、透明物体、视角和有效距离影响;点云裁剪需要手工 operational region;相机外参和机器人坐标系标定也会引入误差。很多系统最后不是 policy 学不好,而是 perception preprocessing 太脆。
VO-DP 的动机就在这里:能否少依赖显式点云,把 RGB 图像交给已经学过 3D 几何的视觉基础模型,让 policy 从中间表征里吸收几何?
视觉编码器:不是直接用 VGGT 输出,而是取中间特征
VO-DP 使用 VGGT 作为视觉 backbone。VGGT 原本能从图像预测 camera、depth、point map 和 tracks,但 VO-DP 不把这些输出直接喂给 policy。论文取的是中间特征:
- DINOv2 / visual tokens 提供语义线索,例如物体类别、边界和可抓区域。
- VGGT alternating attention blocks 提供几何线索,例如跨 token 的空间关系和局部 3D structure。
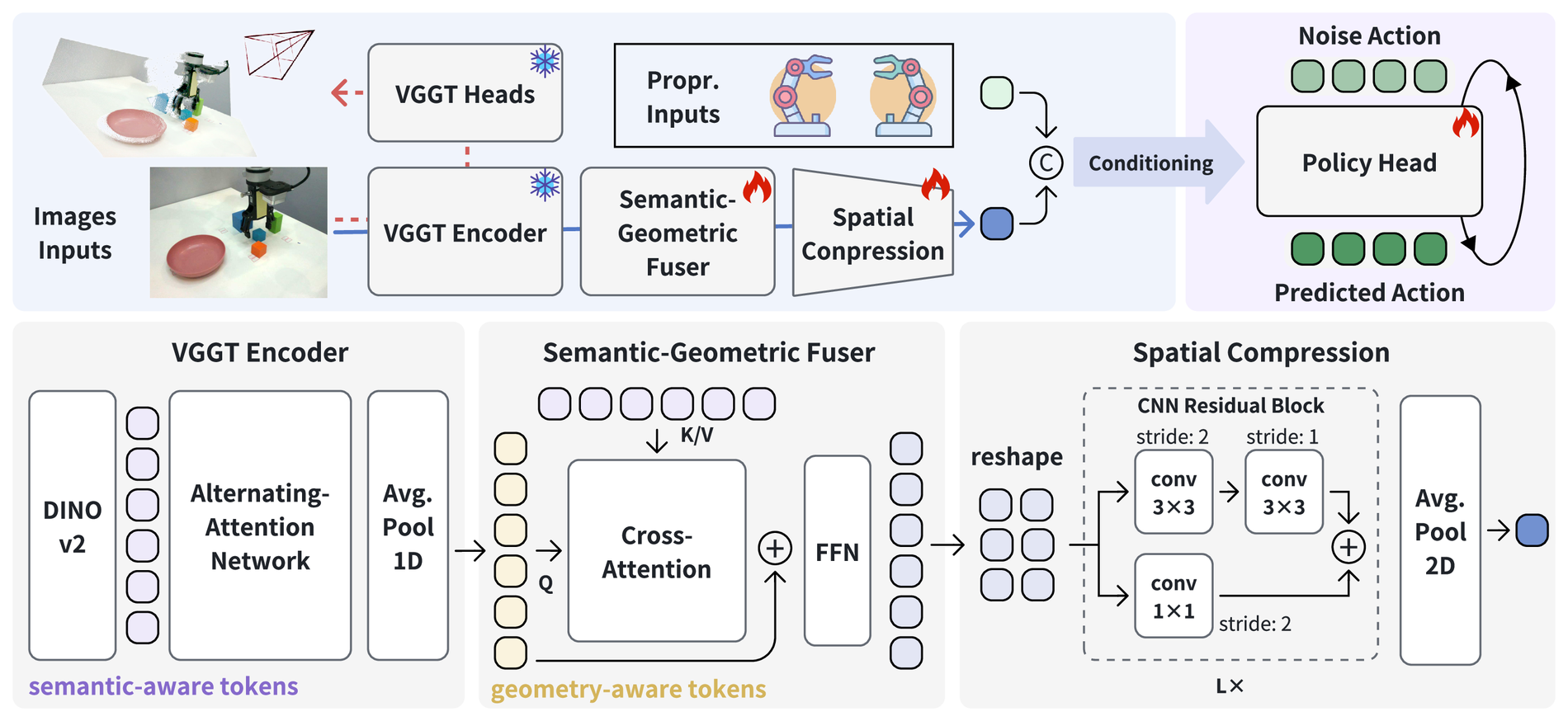
图源:VO-DP,Figure 2。原图表达 VGGT 特征提取、语义-几何融合、CNN 压缩和 diffusion policy head。本站读法:把 VGGT 看成 RGB 到语义-几何特征的转换器,而不是把它当成显式深度传感器。
这一步很重要。显式 depth / point cloud 一旦错了,错误会以几何输入的形式进入 policy;中间特征虽然不如点云可解释,但可能更鲁棒,尤其是在真实世界深度噪声较强时。
融合:语义告诉你抓什么,几何告诉你怎么靠近
VO-DP 先把几何特征通道压到和语义特征同一维度,再用 residual cross-attention 做融合。简化写法是:
其中 表示来自 VGGT 几何分支的中间特征, 表示语义特征, 是对齐后的几何和语义表示。第二行表示语义 token 主动去查询几何 token:先知道“我要操作哪个语义区域”,再从几何特征里拿到空间关系。
融合后的特征经过 CNN spatial compression,变成 diffusion policy 的条件。这个 CNN 压缩不是小细节:动作模型不需要完整高分辨率特征图,它需要一个足够紧凑、稳定、可与机器人状态拼接的控制条件。
动作头:为什么用扩散策略
VO-DP 采用 DDPM 风格的 action diffusion head。policy 不直接回归一个动作,而是从噪声动作序列逐步去噪:
其中 是第 个噪声等级下的动作序列, 是融合后的视觉特征, 是机器人状态, 是模型预测的噪声。训练时模型学习从带噪动作恢复真实动作,推理时从随机噪声迭代生成未来动作 chunk。
扩散策略适合 manipulation 的原因是动作分布可能多峰。同一个任务可以从左边绕,也可以从右边绕;可以先调整夹爪角度,也可以先靠近物体。直接均值回归容易生成“平均但不可执行”的动作,扩散模型更适合保留多种可行动作模式。
仿真结果:VO-DP 不是压倒点云,而是接近点云
RoboTwin 仿真里,VO-DP 平均成功率接近 DP3,并明显高于普通 RGB Diffusion Policy。这个结论要谨慎读:仿真点云很干净,所以 DP3 的几何输入有天然优势;VO-DP 能接近它,说明 RGB 预训练几何特征确实有用。
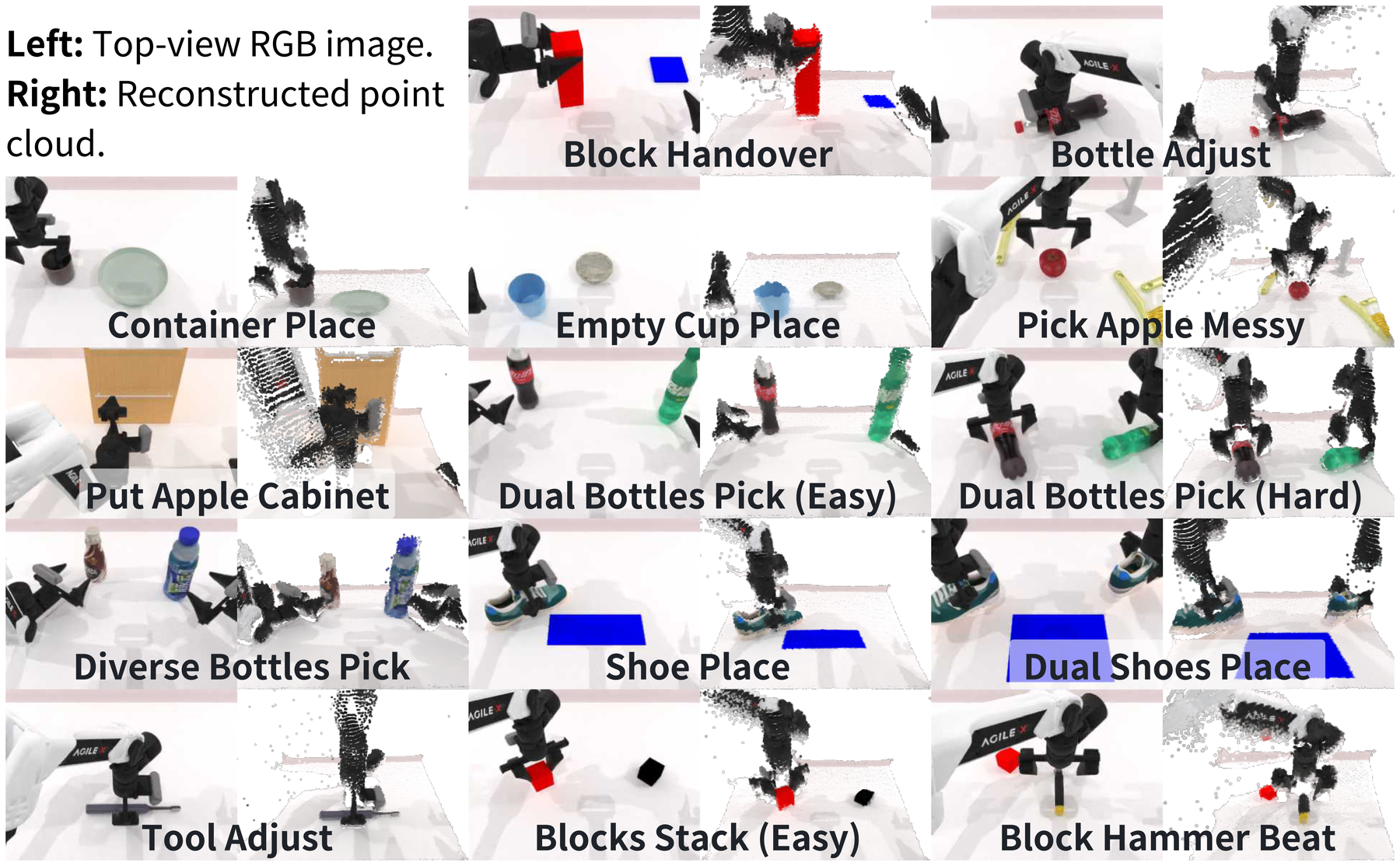
图源:VO-DP,Figure 3。原图表达 RoboTwin 场景重建和仿真任务。本站读法:这组结果主要证明 RGB-only 特征能逼近点云 policy,而不是证明点云没有价值。
论文的消融也支持这个解释。只用语义特征,policy 缺少空间结构;只用几何特征,policy 对目标和语义条件的理解不足;两者融合才稳定。average pooling 比 MLP projection 更稳,说明在低数据 imitation learning 中,额外参数并不一定带来更强策略,反而可能让模型更容易贴合训练分布。
真实结果:为什么 RGB-only 反而可能赢
真实机器人实验更有意思。论文使用 Realman RM65-B 和 Inspire EG2-4C2 夹爪,视觉观测来自 RealSense L515。传感器可以获得 RGB 与点云,但 VO-DP 只用 RGB;DP3 baseline 使用点云,并需要手工定义 operational region。

图源:VO-DP,Figure 4。原图表达真实机器人任务,包括桌面操作、物体移动和夹爪交互。本站读法:看任务是否需要精细空间关系,而不是只看成功率平均值。
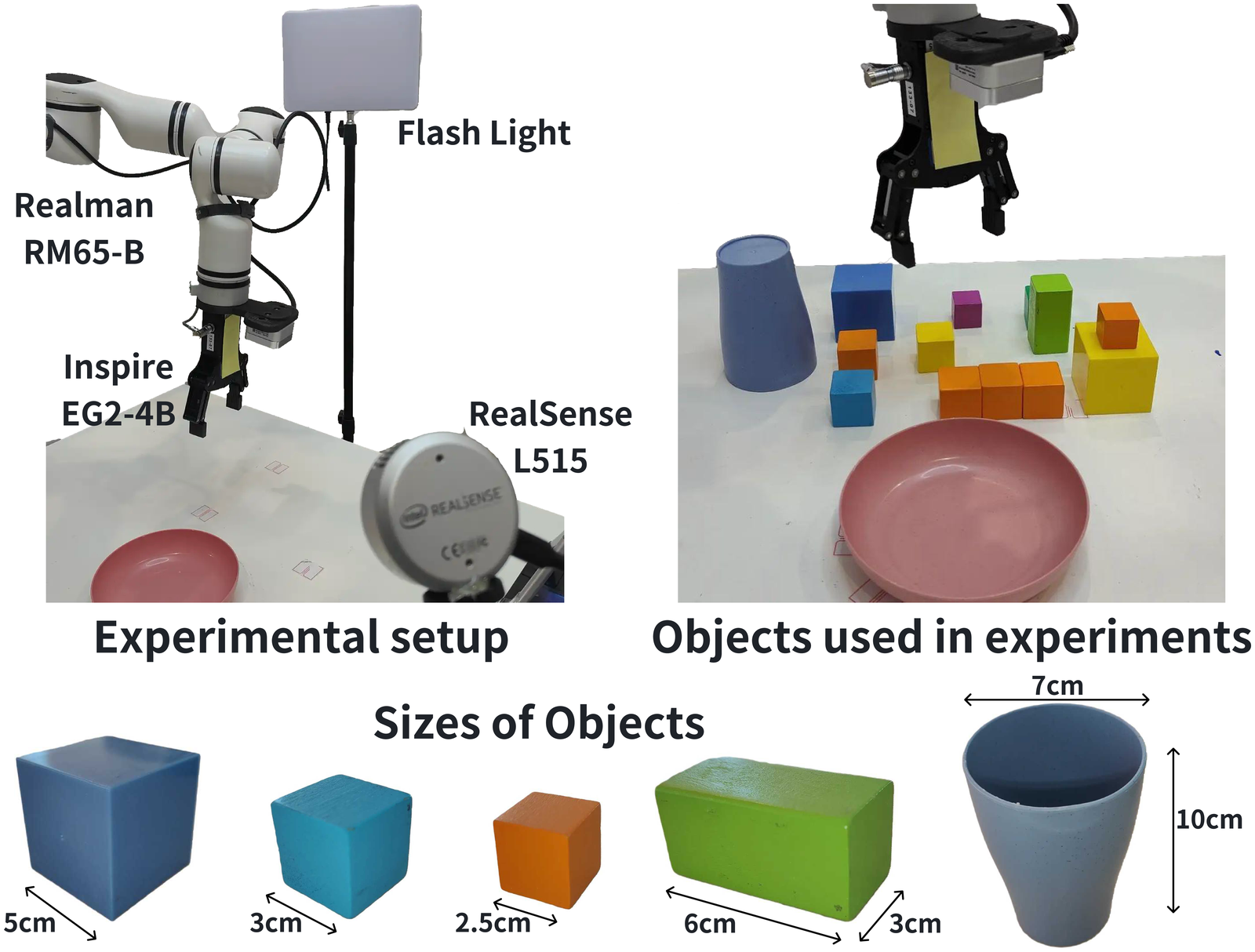
图源:VO-DP,Figure 5。原图表达真实机器人平台和传感器设置。本站读法:注意 RGB-only policy 的实际优势来自部署链路少,不需要点云裁剪和复杂几何预处理。
论文报告真实任务中 VO-DP 明显高于 DP 和 DP3。一个合理解释是:真实点云比仿真点云脆弱,标定误差、深度噪声和 preprocessing 会让 DP3 掉分;而 VO-DP 依赖的是预训练 RGB 特征,虽然几何不显式,但对视觉域变化更鲁棒。
这不是说 RGB 一定强于点云,而是说“点云是强信息”不等于“点云 pipeline 一定强”。真实系统里,信息质量、标定成本、预处理稳定性和 policy 训练都会一起决定效果。
鲁棒性:它在测什么
VO-DP 的鲁棒性实验覆盖颜色、大小、背景、光照等变化。读这组实验时要区分两件事:视觉 backbone 的泛化和 policy 的控制泛化。颜色或背景变化更考验语义表征;物体大小和布局变化更考验几何与动作分布。
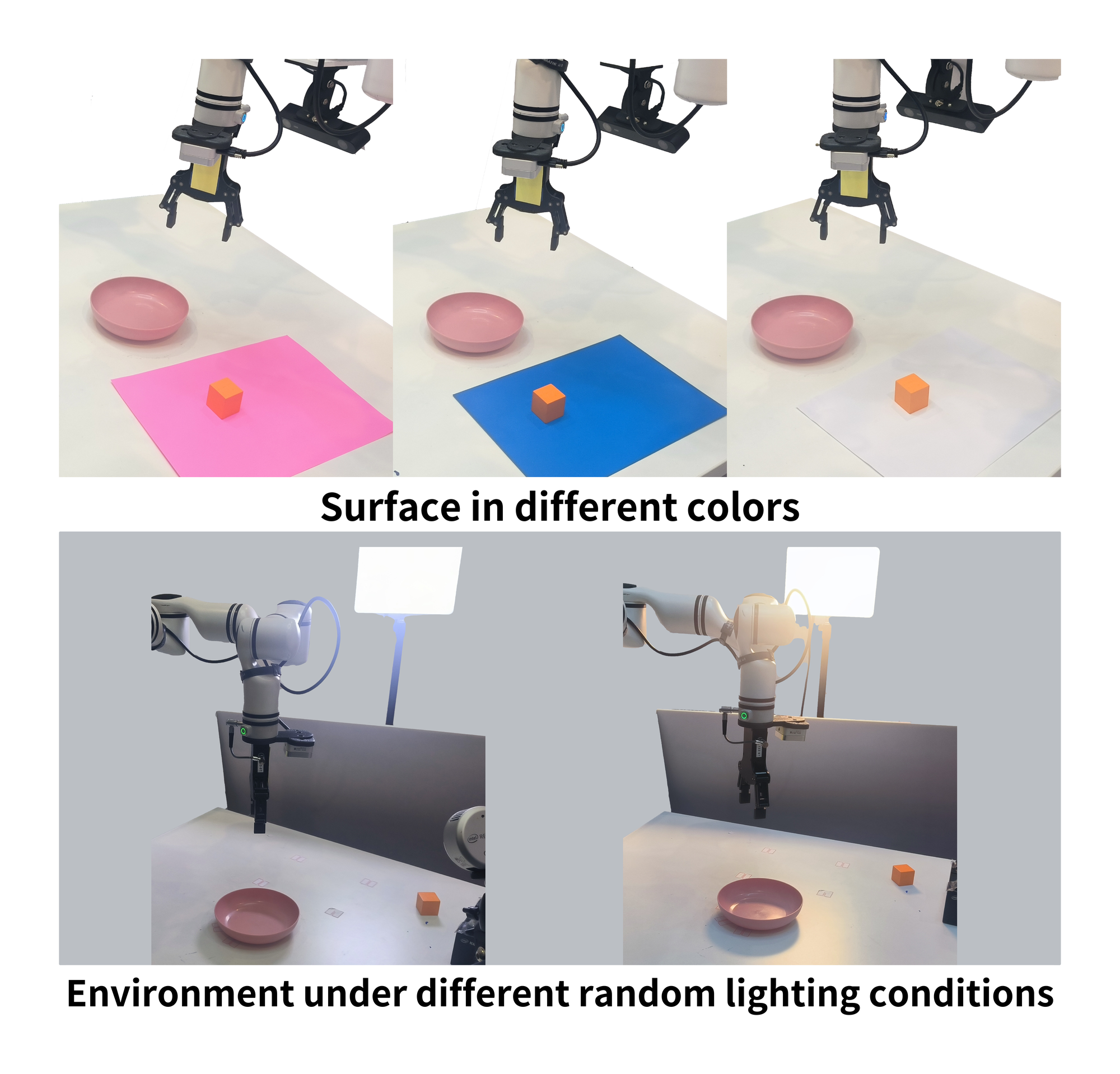
图源:VO-DP,Figure 7。原图表达鲁棒性评测环境变化。本站读法:这些变化主要测试视觉域迁移和局部几何泛化,还不是开放世界长时程任务。

图源:VO-DP,Figure 8。原图表达不同条件下的真实任务鲁棒性。本站读法:如果 RGB-only policy 在光照和背景变化下更稳,说明预训练视觉特征降低了传感器链路脆弱性。
边界与误解
第一,VO-DP 不是大规模语言条件 VLA。它主要是 imitation learning policy,任务范围、语言开放性和长时程组合能力都不能直接外推到 RT-2 或 π0.5 那类模型。
第二,Vision-Only 不等于完全不用几何。它只是不用显式 depth / point cloud 输入;几何信息来自 VGGT 中间特征。更准确地说,VO-DP 是“RGB-only observation with pretrained semantic-geometric representation”。
第三,它没有证明点云路线过时。仿真里 DP3 仍然很强;在真实世界里,点云 pipeline 的部署成本和噪声让 VO-DP 更有优势。未来更稳的 RGB-D、事件相机、触觉或多视角系统仍可能超过单视角 RGB。
第四,扩散动作头并不能自动解决安全和控制。VO-DP 输出的是动作 chunk,真实机器人仍需要低层控制器、限位、安全检查和环境约束。
外部精读
- VO-DP: Semantic-Geometric Adaptive Diffusion Policy for Vision-Only Robotic Manipulation:论文原文,重点读 feature fusion、simulation / real-world 对比和 ablation。
- VO-DP project page:项目页适合看真实机器人视频和任务设置。
- DRRM GitHub repository:论文配套训练库,适合核对 policy 训练接口。
- Diffusion Policy:理解为什么动作生成可以用扩散模型。
- VGGT project page:理解 VO-DP 借用的语义-几何视觉特征来自哪里。
相关阅读与下一步
- 外部材料:论文标题 arXiv 检索。
- 外部材料:Semantic Scholar 标题检索。
- 外部材料:Papers with Code 检索。
- 站内下一步:论文精读专题。
- 站内下一步:论文专题写作规范。
- 站内下一步:外部精读来源台账。
- Title: 论文专题讲解:VO-DP:RGB-only 扩散策略怎样借用语义和几何特征
- Author: Charles
- Created at : 2026-05-03 09:00:00
- Updated at : 2026-05-03 09:00:00
- Link: https://charles2530.github.io/2026/05/03/ai-files-paper-deep-dives-embodied-ai-vodp/
- License: This work is licensed under CC BY-NC-SA 4.0.