
论文专题讲解:vLLM / PagedAttention:为什么 KV cache 需要分页管理
论文题名: Efficient Memory Management for Large Language Model Serving with PagedAttention。
作者: Woosuk Kwon、Zhuohan Li、Siyuan Zhuang、Ying Sheng、Lianmin Zheng、Cody Hao Yu、Joseph E. Gonzalez、Hao Zhang、Ion Stoica。
机构: 未在公开元数据中稳定解析;以 arXiv/PDF 或官方页 affiliation block 为准。
时间 / 主题: 2023-09;高效推理。
arXiv / 官方报告: arXiv:2309.06180;官方材料:vllm.ai/blog/2023-06-20-vllm。
GitHub / 项目: GitHub:github.com/vllm-project/vllm;项目页:vllm.ai/blog/2023-06-20-vllm。
元数据来源与核验口径: 来源:arXiv;GitHub API / repo;官方 / 项目材料;Checked Date:2026-06-04;Repro Status:Paper / official materials reviewed, independent reproduction not claimed。
vLLM 的核心贡献不是“写了一个更快的推理库”,而是抓住了 LLM serving 里最容易被低估的瓶颈:decode 阶段的 KV cache 既大、又动态、还随请求长度不断增长。如果每个请求都按最大长度预留一整段连续 KV 显存,短请求浪费,长尾请求碎片化,请求结束后还会留下难以利用的空洞。PagedAttention 的作用,是把每条 sequence 逻辑上连续的 KV cache 拆成固定大小 block,再用 block table 映射到不连续的物理显存。
一句话读懂这篇论文:vLLM 把 KV cache 从“每个请求一条连续大数组”改成“逻辑连续、物理分页、按需分配、可共享的 block table”。
先算清 KV cache 为什么会压垮并发
自回归生成时,每生成一个 token,模型都会为每层 attention 保存这个 token 的 key/value。下一步 decode 只输入最新 token,但它要 attend 到历史所有 token,因此必须读历史 KV cache。对一条长度为 的请求,KV cache 的显存大致是:
这里的 2 来自 key 和 value, 是层数, 是 KV heads 数, 是 head dimension, 是每个元素的字节数。batch 里有 条活跃请求时,这个量还要乘以 。GQA/MQA 可以降低 ,量化可以降低 bytes,但只要服务长输出、多并发或多候选采样,KV cache 仍然会成为容量瓶颈。
更麻烦的是,KV cache 不是训练时那种形状固定的大 tensor。请求会在不同时间到来,不同时间结束,prompt 长度不同,输出长度也不可预测。传统连续分配要么提前按最大长度预留,浪费大量空间;要么运行时扩容、搬移、压缩,调度复杂且容易产生碎片。
从系统图看 vLLM 管的是什么
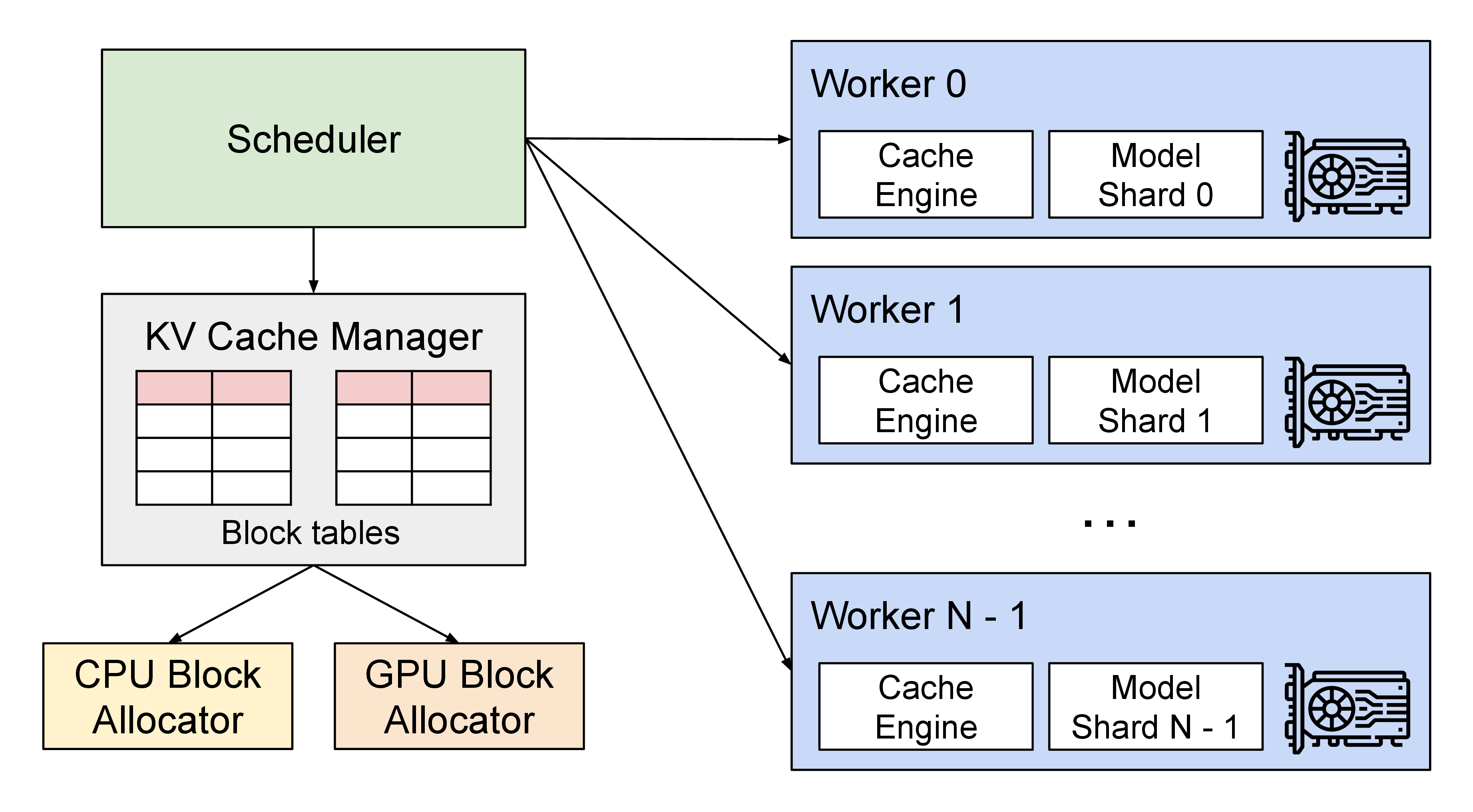
图源:vLLM 官方博客:Easy, Fast, and Cheap LLM Serving with PagedAttention。原图表达 vLLM 在 scheduler、KV cache manager、GPU workers 和模型执行之间的关系。本站读法是把 vLLM 看成 serving runtime:它不只跑 forward,还要决定哪些请求同一轮执行、哪些 block 分配或释放、哪些 KV 可以共享。
这张图把 vLLM 的位置讲得很清楚。模型权重只是一部分;真正的 runtime 还要管理请求队列、iteration-level batching、KV block 分配、GPU worker 执行和返回结果。PagedAttention 是其中的 attention/KV 内存接口,让调度器可以更自由地把变长请求塞进 batch。
PagedAttention:逻辑连续,物理不必连续
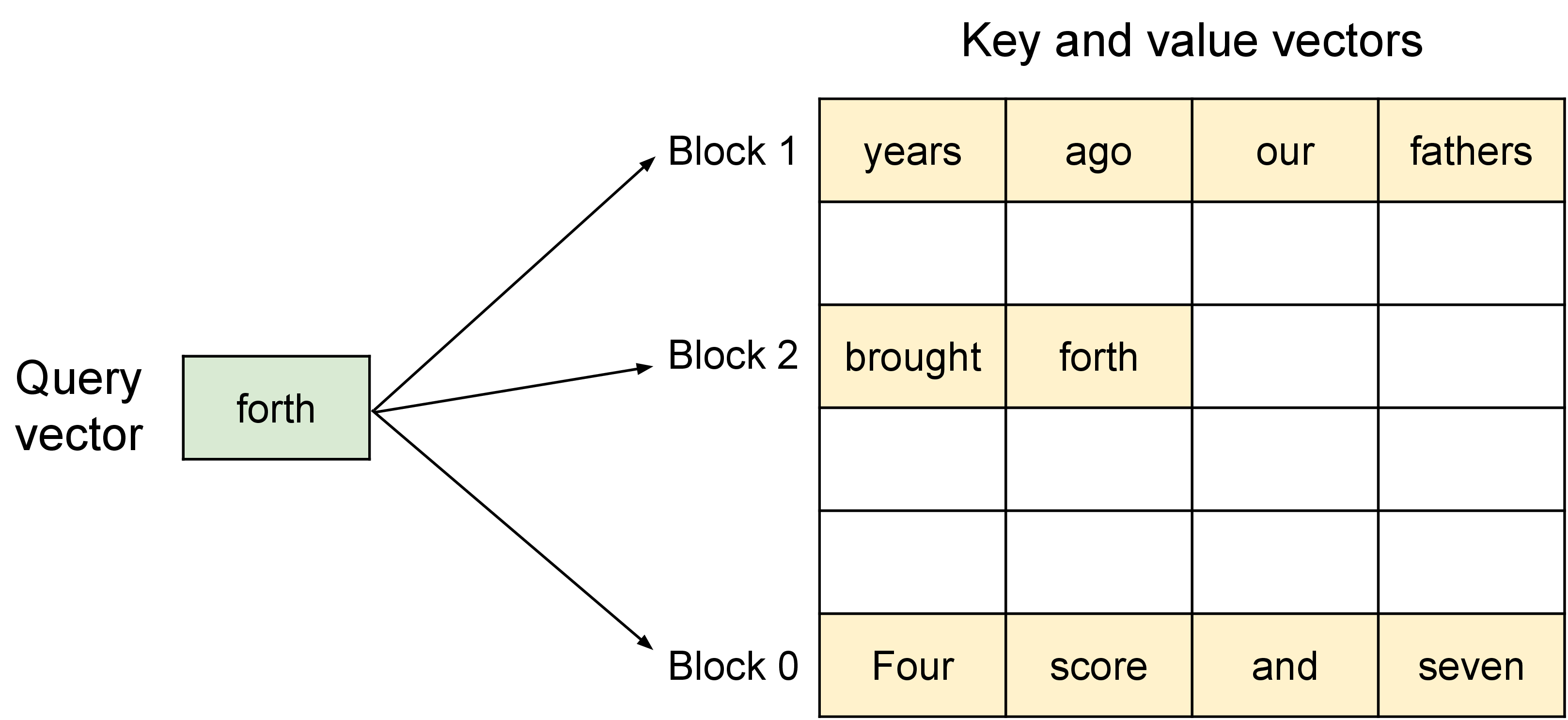
图源:vLLM 官方博客。原图表达每条 sequence 的 KV cache 被切成 block,逻辑 block 通过 block table 映射到物理 block。本站读法是看两层地址:token 序列在逻辑上连续,GPU DRAM 里的 KV block 可以散落在不同位置。
论文把 KV cache 按固定 token 数切成 KV blocks。设 block size 是 ,第 个 key/value block 可以写成:
对第 个 query token,attention 仍然要看 到 的历史 token,只是读取方式变了:kernel 不再假设这些 key/value 在显存里连续,而是按 block table 找到每个逻辑 block 对应的物理 block,再分块读取 做 attention。
这和操作系统分页的类比非常贴切,但要注意它不是把 OS page table 直接搬进 GPU,而是在 serving runtime 和 attention kernel 里显式维护 block table。请求继续生成时追加 block;请求结束时释放 block;最后一个 block 里没有填满的槽位是主要内部浪费。
Block table:为什么它能减少碎片
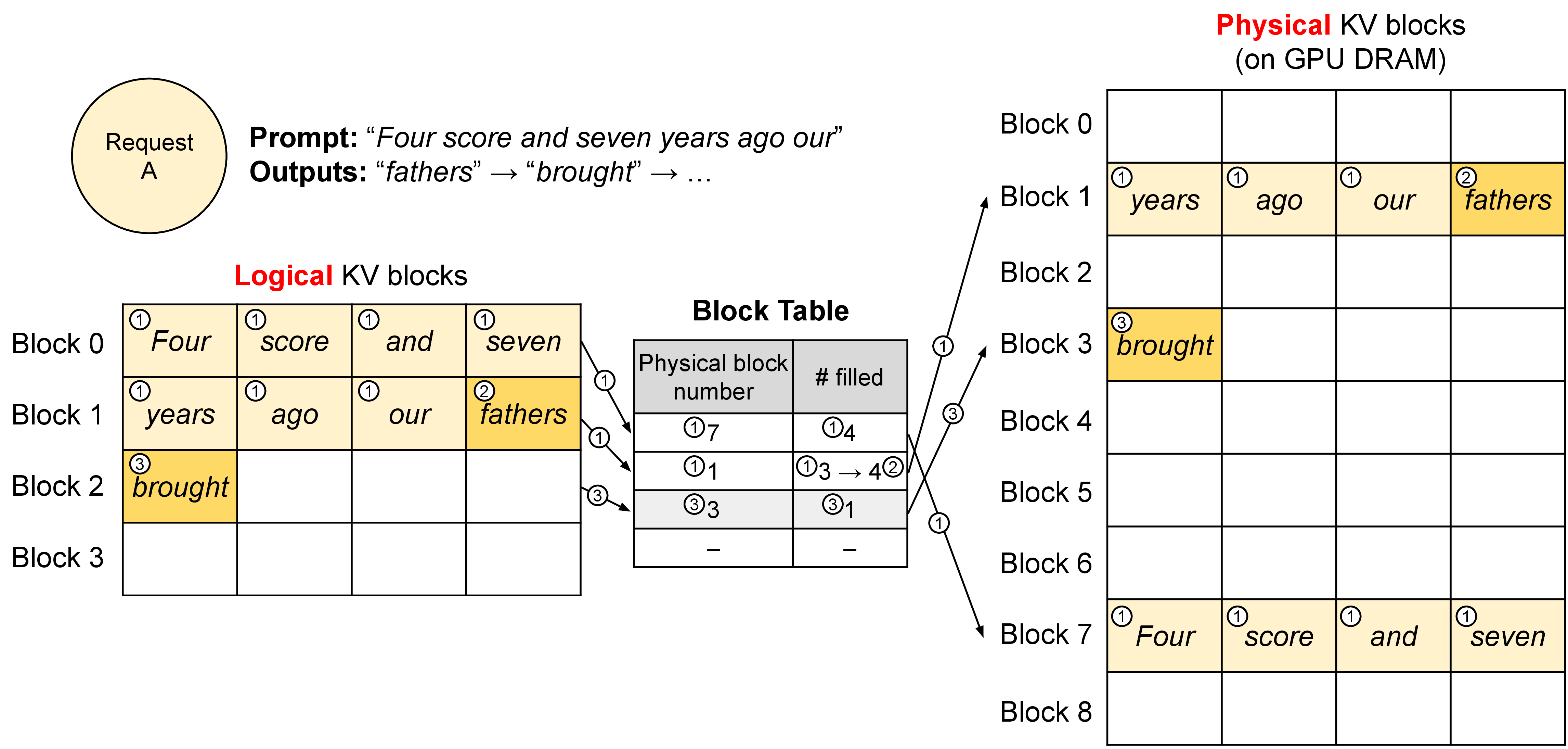
图源:Efficient Memory Management for Large Language Model Serving with PagedAttention,Figure 6。原图展示 block table 如何把 logical KV blocks 映射到 physical KV blocks,并记录 block 中已填位置。本站读法是看“何时分配”:prompt 只分配已经需要的 block,decode 时当前 block 填满才申请下一个物理 block。
假设 block size 是 4,一个 prompt 有 7 个 token,那么它只需要两个 logical blocks。第一个 block 填 4 个 token,第二个 block 填 3 个 token,还留 1 个位置给后续生成。下一步 decode 时,如果最后一个 block 还有空位,就直接写进去;如果满了,才向 block pool 申请新物理 block,并更新 block table。
这个策略解决了三类浪费。第一,不再按最大可能输出长度预留整段 KV。第二,逻辑上相邻的 block 不要求物理相邻,外部碎片不再阻止新请求进入。第三,每条请求的主要未用空间被限制在最后一个 block 内。结果不是单个 token attention 公式变少了,而是同样显存里能容纳更多活跃请求,batch 更大,吞吐更高。
共享前缀和 copy-on-write
PagedAttention 还有一个很实用的收益:多个候选输出可以共享 prompt KV。parallel sampling、beam search、同一系统提示词下的多请求,都可能拥有相同前缀。vLLM 可以让多个 logical blocks 指向同一组 physical blocks,并给物理 block 维护 reference count。
当两个样本共享 prompt 后开始生成不同 token,它们只有最后需要写入的 block 会分叉。此时 runtime 使用 copy-on-write:如果某个物理 block 的 reference count 大于 1,写入前先复制出一个新物理 block,再让其中一个 sequence 写入新 block。这样,长 prompt 的 KV 不需要为每个候选完整复制,只有真正分歧的位置才产生额外显存。
这点对程序生成、搜索、多候选回答特别重要。没有 block-level sharing,多候选采样会把同一 prompt 的 KV 重复存很多份;有了 sharing,显存压力主要来自分叉之后的输出部分。
Continuous batching 为什么离不开内存管理
很多介绍会把 vLLM 的吞吐提升归结为 continuous batching,但 continuous batching 本身并不是魔法。它要求 runtime 能在每一轮 decode 里动态加入新请求、移除完成请求、给正在增长的请求追加 KV 空间。如果 KV cache 只能按连续大段预留,调度器即使想换 batch,也会被显存碎片和预留浪费卡住。
PagedAttention 给 continuous batching 提供了可操作的内存模型:每轮选出当前要执行的 sequences,给需要新空间的逻辑 block 分配物理 block,attention kernel 按 block table 读取历史 KV,生成后写回对应 block。请求结束时,它的物理 block 立即回到 pool。调度、内存和 kernel 这三件事必须一起看,不能把 vLLM 简化成单个 CUDA kernel 优化。
它没有解决什么
PagedAttention 解决的是 KV cache 分配、碎片和共享问题,不是所有推理瓶颈。长上下文仍然需要读大量 KV,attention 的内存带宽压力不会因为分页而消失。长 prompt 短输出的 workload 主要受 prefill 影响;短 prompt 长输出更容易受 decode、KV bandwidth 和调度影响。模型权重本身、跨 GPU 通信、采样逻辑、tokenizer、网络队列和 P99 延迟,也都可能成为瓶颈。
读数边界。 所以读 vLLM benchmark 时不能只看一个 tokens/s,也不能把系统吞吐提升误读成单个 attention kernel 的加速。要看 prompt/output 长度分布、并发数、是否启用 prefix cache、是否使用 beam/parallel sampling、block size、模型结构是否有 GQA/MQA、服务是否受 prefill 还是 decode 支配;PagedAttention 在高并发、变长请求、长输出、多候选共享 prompt 的场景里最能体现价值。
阅读结论
vLLM/PagedAttention 这篇论文的核心知识有三层。第一,KV cache 是 decode 阶段的主要动态显存对象,按最大长度连续预留会造成严重浪费。第二,PagedAttention 用 logical block 到 physical block 的映射,让 KV cache 可以按需增长、非连续存放、完成后释放。第三,block-level sharing 和 copy-on-write 让 parallel sampling、beam search 和共享前缀请求少复制 KV。
看任何 LLM serving 系统时,都可以沿着这条线追问:KV cache 是怎么分配的?请求变长时是否需要搬移?prefix 和多候选能否共享?batch 是按请求、按 token 还是按 iteration 调度?benchmark 的 workload 是否和你的线上请求长度一致?
外部精读
- PagedAttention paper
- vLLM official blog: Easy, Fast, and Cheap LLM Serving with PagedAttention
- vLLM documentation
- vLLM GitHub
- 智源社区:伯克利开源 LLM 推理与服务库 vLLM
相关阅读与下一步
- 外部材料:论文标题 arXiv 检索。
- 外部材料:Semantic Scholar 标题检索。
- 外部材料:Papers with Code 检索。
- 站内下一步:论文精读专题。
- 站内下一步:论文专题写作规范。
- 站内下一步:外部精读来源台账。
- Title: 论文专题讲解:vLLM / PagedAttention:为什么 KV cache 需要分页管理
- Author: Charles
- Created at : 2026-05-20 09:00:00
- Updated at : 2026-05-20 09:00:00
- Link: https://charles2530.github.io/2026/05/20/ai-files-paper-deep-dives-inference-vllm-pagedattention/
- License: This work is licensed under CC BY-NC-SA 4.0.