
P5 Design documents
Verilog流水线CPU设计文档
一、 CPU设计方案综述
(一) 总体设计概述
使用Verilog开发一个简单的流水线CPU,总体概述如下:
-
此CPU为32位CPU
-
此CPU为流水线设计
-
此CPU支持的指令集为:
{add, sub, ori, lw, sw, beq, lui, nop,jal,j,jr}
-
add, sub不支持溢出
(二) 关键模块定义
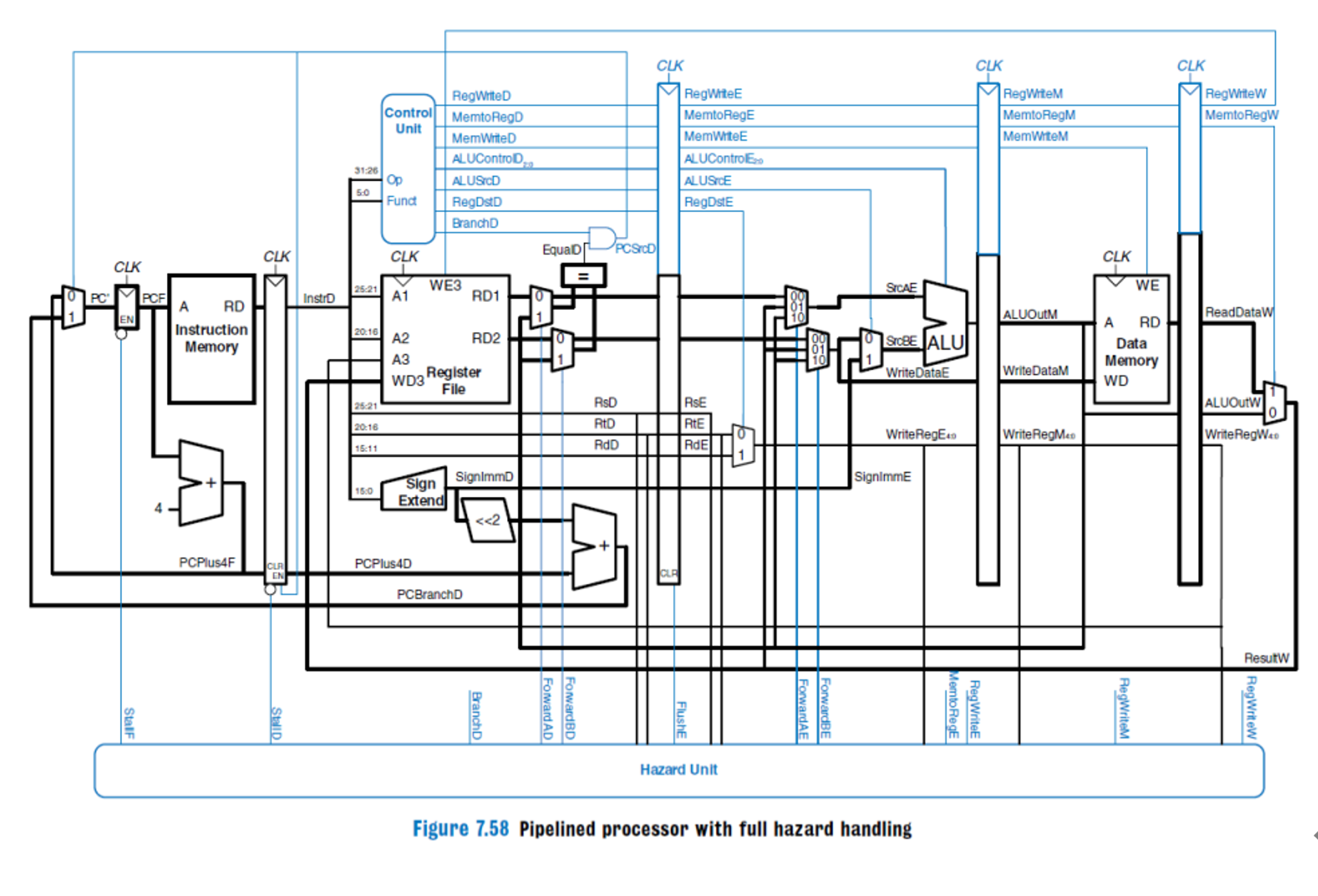
F级流水线
1. PC
(1) 端口说明
| 序号 | 信号名 | 方向 | 描述 |
|---|---|---|---|
| 1 | clk | I | 时钟信号 |
| 2 | reset | I | 同步复位信号,将PC值置为0x0000_3000: 0:无效 1:复位 |
| 3 | en | I | 使能信号,决定是否阻塞 |
| 4 | NPC[31:0] | I | 下一周期PC的地址 |
| 5 | instr[31:0] | O | 将IM中,要执行的指令输出 |
| 6 | PC[31:0] | O | 当前执行的PC |
(2) 功能定义
| 序号 | 功能 | 描述 |
|---|---|---|
| 1 | 复位 | reset有效时,PC置为0x00000000 |
| 2 | 更新PC的值 | 将PC赋值为NPC |
| 3 | 输出指令 | 根据PC的值,取出IM中的指令 |
Folding coding
1 |
|
Folding coding
1 | //内置IM |
D级流水线
1. GRF
(1) 端口说明
| 序号 | 信号名 | 方向 | 描述 |
|---|---|---|---|
| 1 | clk | I | 时钟信号 |
| 2 | reset | I | 同步复位信号,将32个寄存器中全部清零 1:清零 0:无效 |
| 3 | WE | I | 写使能信号 1:可向GRF中写入数据 0:不能向GRF中写入数据 |
| 4 | A1[4:0] | I | 5位地址输入信号,指定32个寄存器中的一个,将其中存储的数据读出到RD1 |
| 5 | A2[4:0] | I | 5位地址输入信号,指定32个寄存器中的一个,将其中存储的数据读出到RD2 |
| 6 | A3[4:0] | I | 5位地址输入信号,指定32个寄存器中的一个,作为RD的写入地址 |
| 7 | WD[31:0] | I | 32位写入数据 |
| 8 | WPC[31:0] | I | 当前写入GRF的PC |
| 9 | RD1[31:0] | O | 输出A1指定的寄存器的32位数据 |
| 10 | RD2[31:0] | O | 输出A2指定的寄存器的32位数据 |
(2) 功能定义
| 序号 | 功能 | 描述 |
|---|---|---|
| 1 | 同步复位 | reset为1时,将所有寄存器清零 |
| 2 | 读数据 | 将A1和A2地址对应的寄存器的值分别通过RD1和RD2读出 |
| 3 | 写数据 | 当WE为1且时钟上升沿来临时,将WD写入到A3对应的寄存器内部 |
| 4 | 内部转发 | 当A1和A2之一与A3相等且写入信号为1时,用WD代替RD1或RD2的输出 |
Folding coding
1 |
|
2. EXT
(1) 端口说明
| 序号 | 信号名 | 方向 | 描述 |
|---|---|---|---|
| 1 | imm16[15:0] | I | 代扩展的16位信号 |
| 2 | sign[2:0] | I | 无符号或符号扩展选择信号 3’b001:无符号扩展 3’b010:符号扩展 3’b100: 寄存到高位 |
| 3 | imm32[31:0] | O | 扩展后的32位的信号 |
(2) 功能定义
| 序号 | 功能 | 描述 |
|---|---|---|
| 1 | 无符号扩展 | 当sign为3’b001时,将imm16无符号扩展输出 |
| 2 | 符号扩展 | 当sign为3‘b010时,将imm16符号扩展输出 |
| 3 | 存储到高位 | 当sign为3’100时,将imm16存在高16位 |
Folding coding
1 |
|
3. Controller
(1) 端口说明
| 序号 | 信号名 | 方向 | 描述 |
|---|---|---|---|
| 1 | op[5:0] | I | instr[31:26]6位控制信号 |
| 2 | func[5:0] | I | instr[5:0]6位控制信号 |
| 3 | AluOp[6:0] | O | ALU的控制信号 |
| 4 | WeGrf | O | GRF写使能信号 0:禁止写入 1:允许写入 |
| 5 | WeDm | O | DM的写入信号 0:禁止写入 1:允许写入 |
| 6 | branch[3:0] | O | PC转移位置选择信号 4’b0001:其他情况 4’b0010:beq 4’b0100:j||jal 4’b1000:jr; |
| 7 | AluSrc1[3:0] | O | 参与ALU运算的第一个数 4’b0001:RD1 4’b0010:RD2 |
| 8 | AluSrc2[3:0] | O | 参与ALU运算的第二个数,来自GRF还是imm 4’b0001:RD2 4’b0010:imm32 4’b0100: offset |
| 9 | WhichtoReg[3:0] | O | 将何种数据写入GRF? 4’b0001:ALU计算结果 4’b0010:DM读出信号 4’b0100:upperImm 4’b1000: PC+4 |
| 10 | RegDst[3:0] | O | 写入GRF的哪个寄存器? 4’b0001:rd 4’b0010:rt 4’b0100:31号寄存器 |
| 11 | SignExt[2:0] | O | 拓展方式: 3’b001:0拓展 3’b010:符号拓展 3’b100:存储到高位 |
| 12 | B_change[3:0] | O | B转移的类型 4’b0001:beq 4’b0010:slt 4’b0100:blez |
| 13 | DM_type[3:0] | O | 存取指令类型: 4’b0001:lw/sw 4’b0010:lh/sh 4’b0100:lb/sb |
| 14 | D_Tuse_rs[1:0] | O | 指令的rs寄存器的值从第一次进入D级到被使用的周期数 |
| 15 | D_Tuse_rt[1:0] | O | 指令的rt寄存器的值从第一次进入D级到被使用的周期数 |
| 16 | D_Tnew[1:0] | O | 指令从进入D开始到产生运算结果需要的周期数 |
Folding coding
1 |
|
4.NPC(下一指令计算单元)
该模块根据当前pc(包括D级和F级)和其他控制信号(NPCOp,CMP输出信息),计算出下一指令所在的地址npc,传入IFU模块。
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| F_pc | I | 32 | F级指令地址 |
| D_pc | I | 32 | D级指令地址 |
| offset | I | 32 | 地址偏移量,用于计算B类指令所要跳转的地址 |
| imm26 | I | 26 | 当前指令数据的前26位(0~25),用于计算jal和j指令所要跳转的地址 |
| ra | I | 32 | 储存在寄存器($ra或是jalr指令中存储“PC+4”的寄存器)中的地址数据,用于实现jr和jalr指令 |
| ALU_change | I | 1 | B类指令判断结果 1:说明当前B类指令的判断结果为真 0:说明判断结果为假 |
| branch | I | 4 | NPC功能选择 0x000:顺序执行 0x001:B类指令跳转 0x010: jal/j跳转 0x011: jr/jalr跳转 |
| npc | O | 32 | 输出下一指令地址 |
| PC8 | O | 32 | jr指令时存储PC+8的值 |
Folding coding
1 |
|
5.B_transfer(B类指令比较单元)
该单元根据输入的CMPOp信号对当前B指令的类型进行判断,进而对当前输入的数值进行相应比较,最后输出结果。
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| A | I | 32 | 输入B_transfer单元的第一个数据 |
| B | I | 32 | 输入B_transfer单元的第二个数据 |
| Type | I | 4 | Type功能选择信号 0x0001:beq判断 0x0010:slt判断 0x0100:blez判断 |
| ALU_change | O | 1 | 判断结果输出 1: 判断结果为真 0:判断结果为假 |
Folding coding
1 |
|
E级流水线
1. ALU
(1) 端口说明
| 序号 | 信号名 | 方向 | 描述 |
|---|---|---|---|
| 1 | A[31:0] | I | 参与运算的第一个数 |
| 2 | B[31:0] | I | 参与运算的第二个数 |
| 3 | ALUop[6:0] | I | 决定ALU做何种操作 7’b000001:无符号加 7’b000010:无符号减 7’b000100:与 7’b001000:或 7’b010000:左移位运算 |
| 4 | res | O | A与B做运算后的结果 |
(2) 功能定义
| 序号 | 功能 | 描述 |
|---|---|---|
| 1 | 加运算 | res = A + B |
| 2 | 减运算 | res = A - B |
| 3 | 与运算 | res = A & B |
| 4 | 或运算 | res = A | B |
| 5 | 左移位运算 | Res=A<<B |
Folding coding
1 |
|
M级流水线
1. DM
(1) 端口说明
| 序号 | 信号名 | 方向 | 描述 |
|---|---|---|---|
| 1 | clk | I | 时钟信号 |
| 2 | reset | I | 异步复位信号 0:无效 1:内存值全部清零 |
| 3 | WE | I | 写使能信号 0:禁止写入 1:允许写入 |
| 4 | Address[31:0] | I | 读取或写入信号地址 |
| 5 | WD[31:0] | I | 32为写入数据 |
| 6 | pc[31:0] | I | 当前输入DM的PC值(用于测试) |
| 7 | RD[31:0] | O | 32位读出数据 |
| 8 | DM_type[3:0] | O | 决定存取指令类型 4’b0001 lw/sw 4’b0010 lh/sh 4’b0100 lb/sb |
(2) 功能定义
| 序号 | 功能 | 描述 |
|---|---|---|
| 1 | 异步复位 | 当reset为1时,DM中所有数据清零 |
| 2 | 写入数据 | 当WE有效时,时钟上升沿来临时,WD中数据写入A对应的DM地址中 |
| 3 | 读出数据 | RD永远读出A对应的DM地址中的值 |
Folding coding
1 |
|
Folding coding
1 | //DM_In DM输入信号 |
Folding coding
1 | //DM_Out DM输出信号 |
各级流水线寄存器
1.IF_ID
D_Reg(IF/ID流水寄存器)
- 端口定义
| 方向 | 信号名 | 位宽 | 描述 | 输入来源 |
|---|---|---|---|---|
| I | clk | 1 | 时钟信号 | mips.v中的clk |
| I | reset | 1 | 同步复位信号 | mips.v中的reset |
| I | en | 1 | D级寄存器使能信号 | stall信号取反 |
| I | F_instr | 32 | F级instr输入 | IFU_instr |
| I | F_pc | 32 | F级pc输入 | IFU_pc |
| I | F_pc8 | 32 | F级pc8输入 | IFU_pc + 8 |
| O | D_instr | 32 | D级instr输出 | |
| O | D_pc | 32 | D级pc输出 | |
| O | D_pc8 | 32 | D级pc8输出 |
Folding coding
1 |
|
2.ID_EX
E_Reg(ID/EX流水寄存器)
- 端口定义
| 方向 | 信号名 | 位宽 | 描述 | 输入来源 |
|---|---|---|---|---|
| I | clk | 1 | 时钟信号 | mips.v中的clk |
| I | reset | 1 | 同步复位信号 | mips.v中的reset |
| I | clr | 1 | E级寄存器清空信号 | HazardUnit中stall信号 |
| I | D_RD1 | 32 | D级GRF输出RD1 | 通过B_transfer_D1转发的数据 |
| I | D_RD2 | 32 | D级GRF输出RD2 | 通过B_transfer_D2转发的数据 |
| I | D_instr_s | 5 | D级instr的shamt | D_instr的s域数据 |
| I | D_A1 | 5 | D级A1输入 | D_instr的rs域数据 |
| I | D_A2 | 5 | D级A2输入 | D_instr的rt域数据 |
| I | D_A3 | 5 | D级A3输入 | 通过MUX_A3选择出的数据 |
| I | D_imm32 | 32 | D级imm32输入 | 通过EXT模块扩展出的数据 |
| I | D_PC | 32 | D级PC输入 | 前一级相同信号 |
| I | D_PC8 | 32 | D级PC8输入 | 前一级相同信号 |
| I | Tnew_D | 2 | D级指令的Tnew输入 | 前一级相同信号 |
| I | D_Wegrf | 1 | D级控制信号输入 | 前一级相同信号 |
| I | D_WeDm | 1 | D级控制信号输入 | 前一级相同信号 |
| I | D_ALUop | 7 | D级控制信号输入 | 前一级相同信号 |
| I | D_AluSrc1 | 4 | D级控制信号输入 | 前一级相同信号 |
| I | D_AluSrc2 | 4 | D级控制信号输入 | 前一级相同信号 |
| I | D_WhichtoReg | 8 | D级控制信号输入 | 前一级相同信号 |
| I | D_RegDst | 4 | D级控制信号输入 | 前一级相同信号 |
| I | D_DM_type | 4 | D级控制信号输入 | 前一级相同信号 |
| O | E_RD1 | 32 | E级RD1输出 | |
| O | E_RD2 | 32 | E级RD2输出 | |
| O | E_instr_s | 5 | 移位指令的位移数 | |
| O | E_A1 | 5 | E级A1输出 | |
| O | E_A2 | 5 | E级A2输出 | |
| O | E_A3 | 5 | E级A3输出 | |
| O | E_imm32 | 32 | E级imm32输出 | |
| O | E_PC | 32 | E级PC输出 | |
| O | E_PC8 | 32 | E级PC8输出 | |
| O | E_Tnew | 2 | E级指令的Tnew输出 | |
| O | E_Wegrf | 1 | E级控制信号输出 | |
| O | E_WeDm | 1 | E级控制信号输出 | |
| O | E_ALUop | 7 | E级控制信号输出 | |
| O | E_AluSrc1 | 4 | E级控制信号输出 | |
| O | E_AluSrc2 | 1 | E级控制信号输出 | |
| O | E_WhichtoReg | 1 | E级控制信号输出 | |
| O | E_RegDst | 3 | E级控制信号输出 | |
| O | E_DM_type | 4 | E级控制信号输出 |
-
运算功能
Tnew_E = (Tnew_D > 0) ? Tnew_D - 1: 0Tnew_E=(Tnew_D>0)?Tnew_D−1:0
Folding coding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
module ID(input clk,
input reset,
input clr,
input [31:0] D_RD1,
input [31:0] D_RD2,
input [4:0] D_instr_s,
input [4:0] D_A1,
input [4:0] D_A2,
input [4:0] D_A3,
input [31:0] D_imm32,
input [31:0] D_PC,
input [31:0] D_PC8,
input [1:0] D_Tnew,
input D_Wegrf,
input D_WeDm,
input [6:0] D_ALUop,
input [3:0] D_AluSrc1,
input [3:0] D_AluSrc2,
input [7:0] D_WhichtoReg,
input [3:0] D_RegDst,
input [3:0] D_DM_type,
output reg [31:0] E_RD1,
output reg [31:0] E_RD2,
output reg [4:0] E_instr_s,
output reg [4:0] E_A1,
output reg [4:0] E_A2,
output reg [4:0] E_A3,
output reg [31:0] E_imm32,
output reg [31:0] E_PC,
output reg [31:0] E_PC8,
output reg [1:0] E_Tnew,
output reg E_Wegrf,
output reg E_WeDm,
output reg [6:0] E_ALUop,
output reg [3:0] E_AluSrc1,
output reg [3:0] E_AluSrc2,
output reg [7:0] E_WhichtoReg,
output reg [3:0] E_RegDst,
output reg [3:0] E_DM_type
);
always @(posedge clk)begin
if (reset || clr)begin
//if(reset)begin
E_instr_s <= 0;
E_RD1 <= 0;
E_RD2 <= 0;
E_A1 <= 0;
E_A2 <= 0;
E_A3 <= 0;
E_imm32 <= 0;
E_PC <= 0;
E_PC8 <= 0;
E_Tnew <=0;
E_Wegrf <= 0;
E_WeDm <= 0;
E_ALUop <= 7'b0000001;
E_AluSrc1 <= 4'b0001;
E_AluSrc2 <= 4'b0001;
E_WhichtoReg <= 8'b00000001;
E_RegDst <= 4'b0001;
E_DM_type <= 4'b0001;
end
else begin
E_instr_s <= D_instr_s;
E_RD1 <= D_RD1;
E_RD2 <= D_RD2;
E_A1 <= D_A1;
E_A2 <= D_A2;
E_A3 <= D_A3;
E_imm32 <= D_imm32;
E_PC <= D_PC;
E_PC8 <= D_PC8;
E_Wegrf <= D_Wegrf;
E_WeDm <= D_WeDm;
E_ALUop <= D_ALUop;
E_AluSrc1 <= D_AluSrc1;
E_AluSrc2 <= D_AluSrc2;
E_WhichtoReg <= D_WhichtoReg;
E_RegDst <= D_RegDst;
E_DM_type <= D_DM_type;
if(D_Tnew>0)begin
E_Tnew<=D_Tnew-1;
end
else E_Tnew<=0;
//$display("%d D_RD1:%d ,D_RD2:%d ,D_imm32:%d,D_PC:%h",$time,D_RD1,D_RD2,D_imm32,D_PC);
end
end
//assign E_Tnew = (D_Tnew>0)?D_Tnew-1:0;
endmodule
3.EX_MEM
M_Reg(EX/MEM流水寄存器)
- 端口定义
| 方向 | 信号名 | 位宽 | 描述 | 输入来源 |
|---|---|---|---|---|
| I | clk | 1 | 时钟信号 | mips.v中的clk |
| I | reset | 1 | 同步复位信号 | mips.v中的reset |
| I | E_A2 | 5 | E级A2输入 | ALU_out数据 |
| I | E_A3 | 5 | E级A3输入(转发值) | MUX_ALU选择出来的数据 |
| I | E_RD2 | 32 | E级RD2输入 | 前一级相同信号 |
| I | E_ALUout | 32 | E级res输入 | 前一级相同信号 |
| I | E_PC | 32 | E级PC输入 | 前一级相同信号 |
| I | E_PC8 | 32 | E级PC8输入 | 前一级相同信号 |
| I | E_Tnew | 2 | E级Tnew输入 | 前一级相同信号 |
| I | E_Wegrf | 1 | E级控制信号输入 | 前一级相同信号 |
| I | E_WeDm | 1 | E级控制信号输入 | 前一级相同信号 |
| I | E_WhichtoReg | 8 | E级控制信号输入 | 前一级相同信号 |
| I | E_RegDst | 4 | E级控制信号输入 | 前一级相同信号 |
| I | E_DM_type | 4 | E级控制信号输入 | 前一级相同信号 |
| I | E_imm32 | 32 | E级imm32输入 | 前一级相同信号 |
| O | M_A2 | 5 | M级A2输出 | |
| O | M_A3 | 5 | M级A3输出 | |
| O | M_RD2 | 32 | M级RD2输出 | |
| O | M_ALUout | 32 | M级res输出 | |
| O | M_PC | 32 | M级PC输出 | |
| O | M_PC8 | 32 | M级PC8输出 | |
| O | M_Tnew | 2 | M级Tnew输出 | |
| O | M_Wegrf | 1 | M级Tnew输出 | |
| O | M_WeDm | 1 | M级控制信号输出 | |
| O | M_WhichtoReg | 8 | M级控制信号输出 | |
| O | M_RegDst | 4 | M级控制信号输出 | |
| O | M_DM_type | 4 | M级控制信号输出 | |
| O | M_imm32 | 32 | M级imm32输出 |
-
运算功能
Tnew_M = (Tnew_E > 0) ? Tnew_E - 1: 0Tnew_M=(Tnew_E>0)?Tnew_E−1:0
Folding coding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
module EX(input clk,
input reset,
input [4:0] E_A2,
input [4:0] E_A3,
input [31:0] E_RD2,
input [31:0] E_ALUout,
input [31:0] E_PC,
input [31:0] E_PC8,
input [1:0] E_Tnew,
input E_Wegrf,
input E_WeDm,
input [7:0] E_WhichtoReg,
input [3:0] E_RegDst,
input [3:0] E_DM_type,
input [31:0] E_imm32,
//input E_SelDM,
output reg [4:0] M_A2,
output reg [4:0] M_A3,
output reg [31:0] M_RD2,
output reg [31:0] M_ALUout,
output reg [31:0] M_PC,
output reg [31:0] M_PC8,
output reg [1:0] M_Tnew,
output reg M_Wegrf,
output reg M_WeDm,
output reg [7:0] M_WhichtoReg,
output reg [3:0] M_RegDst,
output reg [3:0] M_DM_type,
output reg [31:0] M_imm32
//output reg M_SelDM
);
always @(posedge clk)begin
if (reset)begin
M_A2 <= 0;
M_A3 <= 0;
M_RD2 <= 0;
M_ALUout <= 0;
M_PC <= 0;
M_PC8 <= 0;
M_Wegrf <= 0;
M_WeDm <= 0;
M_WhichtoReg <= 8'b0000_0001;
M_RegDst <= 4'b0001;
M_DM_type <= 4'b0001;
M_imm32 <= 0;
M_Tnew<=0;
// M_SelDM<=0;
end
else begin
M_A2 <= E_A2;
M_A3 <= E_A3;
M_RD2 <= E_RD2;
M_ALUout <= E_ALUout;
M_PC <= E_PC;
M_PC8 <= E_PC8;
M_Wegrf <= E_Wegrf;
M_WeDm <= E_WeDm;
M_WhichtoReg <= E_WhichtoReg;
M_RegDst <= E_RegDst;
M_DM_type <= E_DM_type;
M_imm32 <= E_imm32;
if(E_Tnew>0)begin
M_Tnew<=E_Tnew-1;
end
else M_Tnew<=0;
//M_SelDM<=E_SelDM;
//$display("%d E_A3: %d,E_ALUout:%d ,E_RD2:%d ,E_PC:%h",$time,E_A3,E_ALUout,E_RD2,E_PC);
end
end
// assign M_Tnew = (E_Tnew>0)?E_Tnew-1:0;
endmodule
4.MEM_WB
W_Reg(MEM/WB流水寄存器)
- 接口定义
| 方向 | 信号名 | 位宽 | 描述 | 输入来源 |
|---|---|---|---|---|
| I | clk | 1 | 时钟信号 | mips.v中的clk |
| I | reset | 1 | 同步复位信号 | mips.v中的reset |
| I | M_A3 | 5 | M级A3输入 | 前一级相同信号 |
| I | M_RD | 32 | M级RD输入 | 前一级相同信号 |
| I | M_PC | 32 | M级PC输入 | 前一级相同信号 |
| I | M_PC8 | 32 | M级PC8输入 | 前一级相同信号 |
| I | M_Wegrf | 1 | M级控制信号输入 | 前一级相同信号 |
| I | M_WhichtoReg | 1 | M级控制信号输入 | 前一级相同信号 |
| I | M_RegDst | 4 | M级控制信号输入 | 前一级相同信号 |
| I | M_imm32 | 32 | M级imm32输入 | 前一级相同信号 |
| I | M_Tnew | 2 | M级Tnew输入 | 前一级相同信号 |
| O | W_A3 | 5 | W级A3输出 | |
| O | W_ALUout | 32 | W级res输出 | |
| O | W_RD | 32 | W级RD输出 | |
| O | W_PC | 32 | W级PC输出 | |
| O | W_PC8 | 32 | W级PC8输出 | |
| O | W_Wegrf | 1 | W级控制信号输出 | |
| O | W_WhichtoReg | 8 | W级控制信号输出 | |
| O | W_RegDst | 4 | W级控制信号输出 | |
| O | W_imm32 | 32 | W级imm32输出 | |
| O | W_Tnew | 2 | W级Tnew输出 |
Folding coding
1 |
|
暂停、转发处理及相关多路选择器
(一).冲突综合单元(HazardUnit)
| 方向 | 信号名 | 位宽 | 描述 |
|---|---|---|---|
| I | D_A1 | 5 | D级A1端输入 |
| I | D_A2 | 5 | D级A2端输入 |
| I | E_A1 | 5 | E级A1端输入 |
| I | E_A2 | 5 | E级A2端输入 |
| I | M_A2 | 5 | M级A2端输入 |
| I | E_A3 | 5 | E级A3端输入 |
| I | M_A3 | 5 | M级A3端输入 |
| I | W_A3 | 5 | W级A3端输入 |
| I | D_Tuse_rs | 2 | D_Tuse_rs输入 |
| I | D_Tuse_rt | 2 | D_Tuse_rt输入 |
| I | E_Tnew | 2 | E级Tnew输入 |
| I | M_Tnew | 2 | M级Tnew输入 |
| I | W_Tnew | 2 | W级Tnew输入 |
| I | E_Wegrf | 1 | E级Wegrf输入 |
| I | M_Wegrf | 1 | M级Wegrf输入 |
| I | W_Wegrf | 1 | W级Wegrf输入 |
| O | SelB_D1 | 2 | B_transfer的D1输入转发信号 |
| O | SelB_D2 | 2 | B_transfer的D2输入转发信号 |
| O | SelALU_A | 2 | ALU输入A转发信号 |
| O | SelALU_B | 2 | ALU输入B转发信号 |
| O | SelDM | 1 | DM写入WD转发信号 |
| O | SelJr | 2 | Jr转发信号 |
| O | stall | 1 | 冲突信号 |
Folding coding
1 |
|
(二).控制和冒险简述
-
对于控制冒险,本实验要求大家实现比较过程前移至 D 级,并采用延迟槽。
-
对于数据冒险,两大策略及其应用:
- 假设当前我需要的数据,其实已经计算出来,只是还没有进入寄存器堆,那么我们可以用转发( Forwarding )来解决,即不引用寄存器堆的值,而是直接从后面的流水级的供给者把计算结果发送到前面流水级的需求者来引用。如果我们需要的数据还没有算出来。则我们就只能暂停( Stall ),让流水线停止工作,等到我们需要的数据计算完毕,再开始下面的工作。
(三).冒险处理
冒险处理我们均通过“A_T”法实现——
转发(forward)
当前面的指令要写寄存器但还未写入,而后面的指令需要用到没有被写入的值时,这时候会产生数据冒险,我们首先考虑进行转发。我们假设所有的数据冒险均可通过转发解决。也就是说,当某一指令前进到必须使用某一寄存器的值的流水阶段时,这个寄存器的值一定已经产生,并存储于后续某个流水线寄存器中。
在这一阶段,我们不管需要的值有没由计算出,都要进行转发,即暴力转发。为实现这一机制,我们要清楚哪些模块需要转发后的数据(需求者)和保存着写入值的流水寄存器(供应者)
- 供应者及其产生的数据
| 流水级 | 产生数据 | MUX名&选择信号名 | MUX输出名 |
|---|---|---|---|
| E | E_imm32, E_PC8 |
直接流水线传递 | 直接流水线传递 |
| M | M_ALUout, M_PC8 |
直接流水线传递 | 直接流水线传递 |
| W | w_res, w_RD, w_imm32, W_PC8 |
w_WhichtoReg | WD |
注:当M级指令为读hi和lo的指令时, M_AO中的结果是从上一周期在乘除槽中读取的hi或lo的值;如果是其他指令,M_AO是上一周期ALU的计算结果。
- 需求者及其产生的数据
| 接收端口 | 选择数据 | HMUX名&选择信号名 | MUX输出名 |
|---|---|---|---|
| B_transfer_D1 | D_V1, M_out, E_out |
SelB_D1 | d_b_transfer1 |
| B_transfer_D2 | d_RD2, m_res, e_res |
SelB_D2 | d_b_transfer2 |
| ALU_A | e_RD1, WD, m_res |
SelALU_A | e_A |
| ALU_B | e_RD2, WD, m_res |
SelALU_B | e_B |
| DM_WD | m_RD2, WD |
SelDM | M_WD_f |
| NPC_ra | D_V1_f , E_PC8 , M_PC8 |
SelJr | ra |
从上表可以看出,W级中的数据没有转发到D级,原因是我们在GRF内实现了内部转发机制,将GRF输入端的数据(还未写入)及时反映到RD1或这RD2,判断条件为A3 == A2或者A3 == A1。
此时为了生成HMUX的选择信号,我们需要向HCU(冒险控制器)输入”A”数据,然后进行选择信号的计算,执行转发的条件为——

暂停(stall)
接下来,我们来处理通过转发不能处理的数据冒险。在这种情况下,新的数据还未来得及产生。我们只能暂停流水线,等待新的数据产生。为了方便处理,我们仅仅为D级的指令进行暂停处理。
我们把Tuse和Tnew作为暂停的判断依据——
- Tuse:指令进入 D 级后,其后的某个功能部件再经过多少时钟周期就必须要使用寄存器值。对于有两个操作数的指令,其每个操作数的 Tuse 值可能不等(如 store 型指令 rs、rt 的 Tuse 分别为 1 和 2 )。
- Tnew:位于 E 级及其后各级的指令,再经过多少周期就能够产生要写入寄存器的结果。在我们目前的 CPU 中,W 级的指令Tnew 恒为 0;对于同一条指令,Tnew@M = max(Tnew@E - 1, 0)、
在这一阶段,我们找到D级生成的Tuse_rs和Tuse_rt和在E,M,W级寄存器中流水的Tnew_D,Tnew_M,Tnew_W,如下表所示
- Tuse表和计算表达式
| 指令类型 | Tuse_rs | Tuse_rt |
|---|---|---|
| calc_R | 1 | 1 |
| calc_I | 1 | X |
| shift | X | 1 |
| shiftv | 1 | 1 |
| load | 1 | X |
| store | 1 | 2 |
| md | 1 | 1 |
| mt | 1 | X |
| mf | X | X |
| branch | 0 | 0 |
| j / jr | X | X |
| jal / jalr | 0 | X |
| lui | X | X |
- Tnew表和计算表达式
| 指令类型 | Tnew_D | Tnew_E | Tnew_M | Tnew_W |
|---|---|---|---|---|
| calc_R | 2 | 1 | 0 | 0 |
| calc_I | 2 | 1 | 0 | 0 |
| shift | 2 | 1 | 0 | 0 |
| shiftv | 2 | 1 | 0 | 0 |
| load | 3 | 2 | 1 | 0 |
| store | X | X | X | X |
| md | X | X | X | X |
| mt | X | X | X | X |
| mf | 2 | 1 | 0 | 0 |
| branch | X | X | X | X |
| jal / jalr | 0 | 0 | 0 | 0 |
| j / jr | X | X | X | X |
| lui | 1 | 0 | 0 | 0 |
然后我们Tnew和Tuse传入HCU(冒险控制器中),然后进行stall信号的计算。如果满足以下条件则stall有效——
-
Tnew > Tuse
-
前位点的读取寄存器地址和某转发输入来源的写入寄存器地址相等且不为 0
-
写使能信号有效
-
当E级延迟槽在进行运算(
start | busy)时,D级为md、mt、mf指令 -
阻塞的构造(D级)


真值表
| 端口 | addu | subu | ori | lw | sw | lui | beq |
|---|---|---|---|---|---|---|---|
| op | 000000 | 000000 | 001101 | 100011 | 101011 | 001111 | 000100 |
| func | 100001 | 100011 | |||||
| AluOp | 0000001 | 0000010 | 0001000 | 0000000 | 0000000 | 0000000 | 0000000 |
| WeGrf | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| WeDm | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| branch | 0001 | 0001 | 0001 | 0001 | 0001 | 0001 | 0010 |
| AluSrc1 | 0001 | 0001 | 0001 | 0001 | 0001 | 0001 | 0001 |
| AluSrc2 | 0001 | 0001 | 0010 | 0010 | 0010 | 0001 | 0001 |
| WhichtoReg | 0001 | 0001 | 0001 | 0010 | 0001 | 0100 | 0001 |
| RegDst | 0001 | 0001 | 0010 | 0010 | 0010 | 0010 | 1010 |
| SignExt | 0 | 0 | 0 | 1 | 1 | 0 | 1 |
| 端口 | andi | jal | j | jr | sll | add | sub |
| op | 001100 | 000011 | 000010 | 000000 | 000000 | 000000 | 000000 |
| func | 001000 | 000000 | 100000 | 100010 | |||
| AluOp | 0000100 | 0000000 | 0000000 | 0000000 | 0010000 | 0000000 | 0000001 |
| WeGrf | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| WeDm | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| branch | 0001 | 0100 | 0100 | 1000 | 0001 | 0001 | 0001 |
| AluSrc1 | 0001 | 0001 | 0001 | 0001 | 0010 | 0001 | 0001 |
| AluSrc2 | 0010 | 0001 | 0001 | 0001 | 0100 | 0001 | 0001 |
| WhichtoReg | 0001 | 1000 | 0001 | 0001 | 0001 | 0001 | 0001 |
| RegDst | 0010 | 0100 | 0001 | 0001 | 0001 | 0001 | 0001 |
| SignExt | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
二、 测试方案
(1) 测试代码:
Folding coding
.text
ori $a0,$0,0x100
ori $a1,$a0,0x123
lui $a2,456
lui $a3,0xffff
ori $a3,$a3,0xffff
addu $s0,$a0,$a2
addu $s1,$a0,$a3
addu $s4,$a3,$a3
subu $s2,$a0,$a2
subu $s3,$a0,$a3
sw $a0,0($0)
sw $a1,4($0)
sw $a2,8($0)
sw $a3,12($0)
sw $s0,16($0)
sw $s1,20($0)
sw $s2,24($0)
sw $s3,44($0)
sw $s4,48($0)
lw $a0,0($0)
lw $a1,12($0)
sw $a0,28($0)
sw $a1,32($0)
ori $a0,$0,1
ori $a1,$0,2
ori $a2,$0,1
beq $a0,$a1,loop1
beq $a0,$a2,loop2
loop1: sw $a0,36($t0)
loop2: sw $a1,40($t0)
jal loop3
jal loop3
sw $s5,64($t0)
ori $a1,$a1,4
jal loop4
loop3:sw $a1,56($t0)
sw $ra,60($t0)
ori $s5,$s5,5
jr $ra
loop4: sw $a1,68($t0)
sw $ra,72($t0)
(2) 该CPU运行结果
Folding coding
@00003000: $ 4 <= 00000100
@00003004: $ 5 <= 00000123
@00003008: $ 6 <= 01c80000
@0000300c: $ 7 <= ffff0000
@00003010: $ 7 <= ffffffff
@00003014: $16 <= 01c80100
@00003018: $17 <= 000000ff
@0000301c: $20 <= fffffffe
@00003020: $18 <= fe380100
@00003024: $19 <= 00000101
@00003028: *00000000 <= 00000100
@0000302c: *00000004 <= 00000123
@00003030: *00000008 <= 01c80000
@00003034: *0000000c <= ffffffff
@00003038: *00000010 <= 01c80100
@0000303c: *00000014 <= 000000ff
@00003040: *00000018 <= fe380100
@00003044: *0000002c <= 00000101
@00003048: *00000030 <= fffffffe
@0000304c: $ 4 <= 00000100
@00003050: $ 5 <= ffffffff
@00003054: *0000001c <= 00000100
@00003058: *00000020 <= ffffffff
@0000305c: $ 4 <= 00000001
@00003060: $ 5 <= 00000002
@00003064: $ 6 <= 00000001
@00003074: *00000028 <= 00000002
@00003078: $31 <= 0000307c
@0000308c: *00000038 <= 00000002
@00003090: *0000003c <= 0000307c
Folding coding
1 | //testbench模块 |
三、 思考题
(一)我们使用提前分支判断的方法尽早产生结果来减少因不确定而带来的开销,但实际上这种方法并非总能提高效率,请从流水线冒险的角度思考其原因并给出一个指令序列的例子。
1 | ori $t0,10 |
在类似上述指令的前提下,由于$t2的值还没有生成,所以beq指令会在D级暂停一个周期,之后后面一条指令进入D级。
但如果在E级进行beq判断,则beq在D级不需要暂停就可以直接通过转发进入E级,在beq执行后其后面一条延迟槽指令可以直接进入E级参与计算。
综上所述,在这种情况之下,addi(延迟槽无关指令)的数据提前一个周期完成了计算。
(二) 因为延迟槽的存在,对于 jal 等需要将指令地址写入寄存器的指令,要写回 PC + 8,请思考为什么这样设计?
因为,jal和jalr后一步会是延迟槽,是必做的一步,所以jr跳回来的是jal和jalr后两步的地方,因此jal和jalr存入RF中的PC+8。
(三)我们要求大家所有转发数据都来源于流水寄存器而不能是功能部件(如 DM 、 ALU ),请思考为什么?
由于流水线寄存器为时序逻辑电路,在工业实际生产时数据来源于流水线寄存器时更加稳定,这样有利于转发更有效的进行。同时,从流水线寄存器中获取数据有利于我们更好地掌握不同数据来自的流水线的级数,有利于效率提高。
(四) 我们为什么要使用 GPR 内部转发?该如何实现?
通过GPR的内部转发,我们可以将要存入GPR的值提前一个轮回带入了计算,这样也就省略了GRF两个输入对数据外部转发的需要,且实现起来相对简单。
GPR 是一个特殊的部件,它既可以视为 D 级的一个部件,也可以视为 W 级之后的流水线寄存器。基于这一特性,我们将对 GPR 采用内部转发机制。也就是说,当前 GPR 被写入的值会即时反馈到读取端上。
具体的说,当读寄存器时的地址与同周期写寄存器的地址相同时,我们将读取的内容改为写寄存器的内容,而不是该地址可以索引到的寄存器文件中的值。
(五)我们转发时数据的需求者和供给者可能来源于哪些位置?共有哪些转发数据通路?
只有 RS 和 RT 会被转发。有四个位点是转发的接受端:
-
NPC 的 RS 输入端
-
CMP 的两个输入端
-
ALU 的输入端
-
DM 的输入端
所以共有6条转发路径,见上方转发说明具体路径。
(六)在课上测试时,我们需要你现场实现新的指令,对于这些新的指令,你可能需要在原有的数据通路上做哪些扩展或修改?提示:你可以对指令进行分类,思考每一类指令可能修改或扩展哪些位置。
总体而言,添加新指令 有以下几个步骤:
1.添加指令前判断所添加指令的数据通路。
2.添加指令前需要判断各指令的D_Tuse_rs,D_Tuse_rt和D_Tnew,之后从而判断其是否需要转发和阻塞的需求,如果需要 转发则确定转发的数据来源。
3.按照各种控制信号的需求修改Controller的编码和相关控制信号的设置。
4.到新指令所要操作的元器件去完成相关指令的功能。
5.完成相关测试及debug
(七)简要描述你的译码器架构,并思考该架构的优势以及不足。
我的译码器为集中式布局。
集中式译码:在取指令(F 级)时或者读取寄存器阵列信息(D 级)前,将所有的控制信号全部解析出,然后让其随着流水往后逐级传递。使用这种方法,只需要在初始对指令进行一次译码,减少了后续流水级的逻辑复杂度,但流水级之间需要传递的信号数量很大。
集中式译码即在 F 或 D 级进行译码,然后将控制信号流水传递,即 P3/P4 采用的译码方式;分布式译码则只流水传递指令,控制信号在每一级单独译码。
集中式译码的好处在于速度更快,关键路径更短;分布式译码关键路径更长,速度较慢(差不了很多)但是译码信息模块化,不需要流水传递控制信号,更适合应试和学习。
选做题
(一)请详细描述你的测试方案及测试数据构造策略。
写了一个随机数生成器来生成一定长度的代码(较短),之后对代码顺序进行优化后测试。相关结果通过与同学对拍来确定是否正确。
数据构造策略为确定数据生成的范围之后通过随机数生成器进行大量测试。若出现bug则手动修改类似数据进行进一步测试。
(二)请评估我们给出的覆盖率分析模型的合理性,如有更好的方案,可一并提出。
由于转发比阻塞的效率更高,所以我们在编码时的基本原则是尽可能转发,而在这个模型中,转发的得分明显高于阻塞,合理。
本覆盖率分析模型的指令集按需分类,更有利于集中式处理,使效率更高。
四.自动化测试模块
Folding coding
1 | import random |
五、规范化编码
1、命名风格
-
各级之间使用
流水级_instr_方向的方式,来有效地对它们进行区分,如:D/E 寄存器的输入端口就可以命名为 D_instr_i -
在顶层模块中,我们需要实例化调用子模块,这个过程会产生很多负责接线的“中间变量”,推荐
流水级_wirename的方式,并且将同级的信号尽可能都声明在一起。
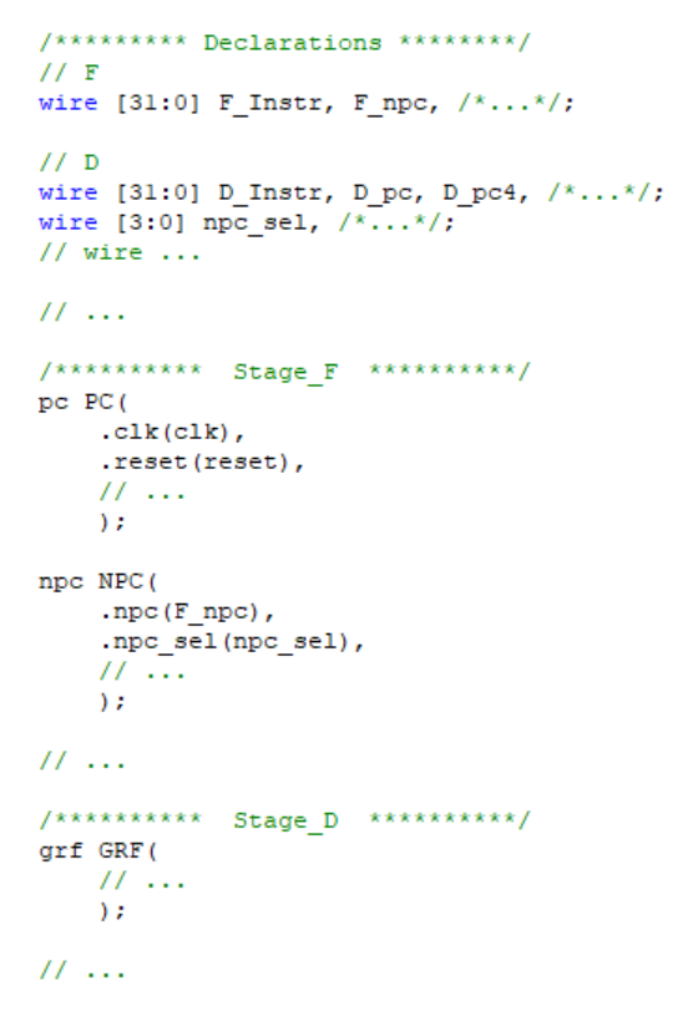
2、模块逻辑排布(看图说话)
3、常量、字面量与宏
对于指令不同的字段,直接定义 wire 型变量如 op、rs 映射到 instr 的对应位上,直观且简短。
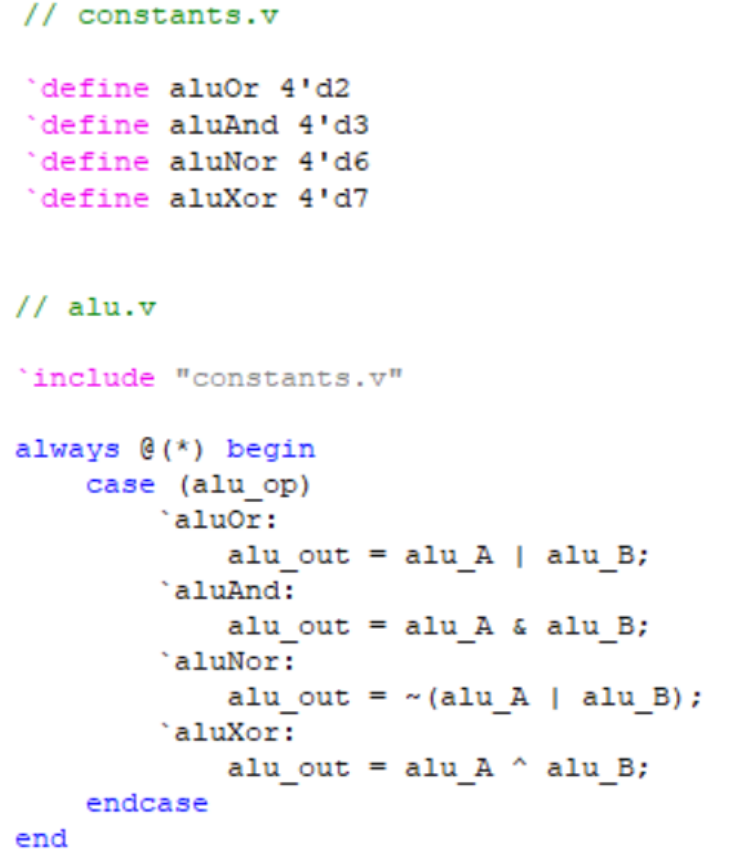
对于控制器译出的信号,如果仅在一个模块内使用,可以使用 localparam 定义。但有很多信号需要被多个模块跨文件使用到(如 alu 的控制信号需要同时在控制器与 alu 出现),并且,我们需要为工程的扩展做好准备,因此更推荐编写一个单独的**宏定义文件(如下)**来供其他的模块用 `include 引用。
4、译码风格
- 指令驱动型:整体在一个 case 语句之下,通过判断指令的类型,来对所有的控制信号一一进行赋值。这种方法便于指令的添加,不易遗漏控制信号,但是整体代码量会随指令数量增多而显著增大。
- 控制信号驱动型:为每个指令定义一个 wire 型变量,使用或运算描述组合逻辑,对每个控制信号进行单独处理。这种方法在指令数量较多时适用,且代码量易于压缩,缺陷是如错添或漏添了某条指令,很难锁定出现错误的位置。
- Title: P5 Design documents
- Author: Charles
- Created at : 2022-12-26 21:10:00
- Updated at : 2023-11-05 21:36:02
- Link: https://charles2530.github.io/2022/12/26/p5-design-documents/
- License: This work is licensed under CC BY-NC-SA 4.0.


