
prefix_sum_algorithm
prefix_sum_algorithm
前缀和
一维前缀和
前缀和是指某序列的前n项和,可以把它理解为数学上的数列的前n项和,而差分可以看成前缀和的
逆运算。合理的使用前缀和与差分,可以将某些复杂的问题简单化。

前缀和算法的作用
先来了解这样一个问题:
输入一个长度为n的整数序列。接下来再输入m个询问,每个询问输入一对l, r。对于每个询问,输出原序列中从第l个数到第r个数的和。
我们很容易想出暴力解法,遍历区间求和。
这样的时间复杂度为O(n * m),如果n和m的数据量稍微大一点就有可能超时,而我们如果使用前缀和的方法来做的话就能够将时间复杂度降到O(n + m),大大提高了运算效率。
构造前缀和数组
首先做一个预处理,定义一个sum[]数组,sum[i]代表a数组中前i个数的和。
1 | const int N = 1e5 + 10; |
sum[r] = a[1] + a[2] + a[3] + a[l-1] + a[l] + a[l + 1] … a[r];
sum[l - 1] = a[1] + a[2] + a[3] + a[l - 1];
sum[r] - sum[l - 1] = a[l] + a[l + 1] + …+ a[r];
这样,对于每个询问,只需要执行 sum[r] - sum[l - 1]。输出原序列中从第l个数到第r个数的和的时间复杂度变成了O(1)。
我们把它叫做一维前缀和。
查询操作
1 | scanf("%d%d",&l,&r); |
对于每次查询,只需执行sum[r] - sum[l - 1] ,时间复杂度为O(1)
总结

二维前缀和
如果数组变成了二维数组怎么办呢?
先给出问题:
输入一个n行m列的整数矩阵,再输入q个询问,每个询问包含四个整数x1, y1, x2, y2,表示一个子矩阵的左上角坐标和右下角坐标。对于每个询问输出子矩阵中所有数的和。
同一维前缀和一样,我们先来定义一个二维数组s[][] , s[i][j] 表示二维数组中,左上角(1, 1)到右下角(i, j)所包围的矩阵元素的和。接下来推导二维前缀和的公式。
先看一张图:
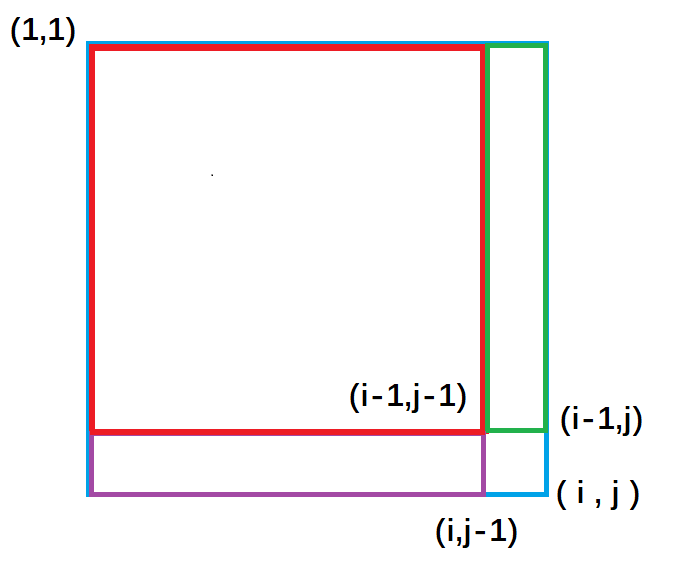
构造二维前缀和数组
由图得出二维前缀和预处理公式:
s[i][j] = s[i - 1][j] + s[i][j - 1 ] + a[i][j] - s[i - 1][j - 1]
接下来回归问题去求以(x1,y1)为左上角和以(x2,y2)为右下角的矩阵的元素的和。
如图:
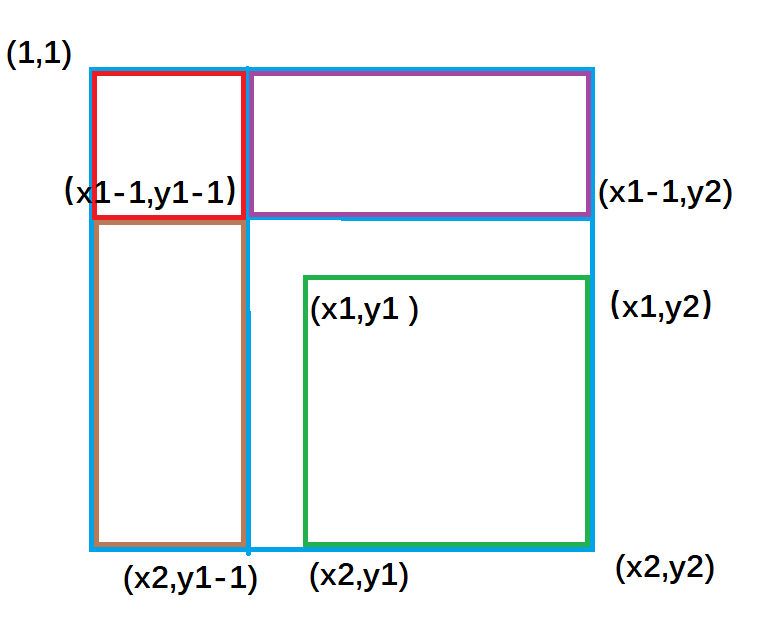
紫色面积是指 (1, 1)左上角到
(x1 - 1, y2)右下角的矩形面积 ,黄色面积是指(1, 1)左上角到(x2, y1 - 1)右下角的矩形面积;
不难推出:
绿色矩形的面积 = 整个外围面积s[x2, y2] - 黄色面积s[x2, y1 - 1] - 紫色面积s[x1 - 1, y2] + 重复减去的红色面积 s[x1 - 1, y1 - 1]
因此二维前缀和的结论为:
以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为:
s[x2, y2] - s[x1 - 1, y2] - s[x2, y1 - 1] + s[x1 - 1, y1 - 1]
总结

差分

一维差分
差分可以看成前缀和的逆运算。
差分数组的作用
给定区间[l, r ],让我们把a数组中的[l, r] 区间中的每一个数都加上c,即 a[l] + c , a[l + 1] + c , a[l + 2] + c , a[r] + c;
暴力做法是for循环l到r区间,时间复杂度O(n),如果我们需要对原数组执行m次这样的操作,时间复杂度就会变成O(n * m)。有没有更高效的做法吗? 考虑差分做法,(差分数组派上用场了)。
首先让差分b数组中的 b[l] + c ,通过前缀和运算,a数组变成 a[l] + c ,a[l + 1] + c, a[n] + c;
然后我们减去范围外多加的c,b[r + 1] - c, 通过前缀和运算,a数组变成 a[r + 1] - c,a[r + 2] - c,a[n] - c;
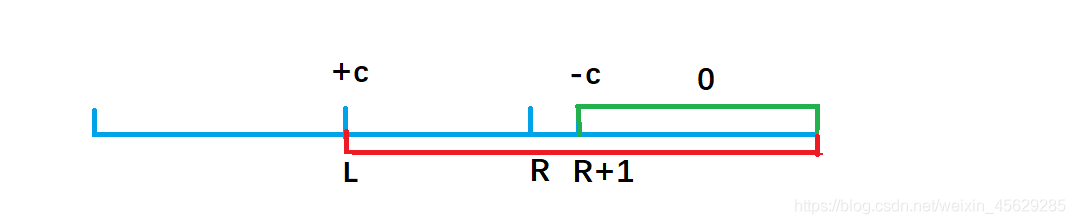
b[l] + c,效果使得a数组中 a[l] 及以后的数都加上了c(红色部分),但我们只要求l到r 区间加上 c, 因此还需要执行 b[r + 1] - c,让a数组中 a[r + 1]及往后的区间再减去c(绿色部分),这样对于a[r] 以后区间的数相当于没有发生改变。
因此我们得出一维差分结论:给a数组中的[ l, r] 区间中的每一个数都加上c,只需对差分数组b做 b[l] + = c, b[r+1] - = c 。时间复杂度为O(1), 大大提高了效率。
差分数组
首先给定一个原数组a:a[1], a[2], a[3],,,,,, a[n];
然后我们构造一个数组b : b[1], b[2], b[3],,,,,, b[i];
使得 a[i] = b[1] + b[2] + b[3] + ,,,,,, + b[i]
也就是说,a数组是b数组的前缀和数组,反过来我们把b数组叫做a数组的差分数组。换句话说,每一个a[i]都是b数组中从头开始的一段区间和。
构造差分b数组
b[n] = a[n] - a[n - 1];
我们只要有b数组,通过前缀和运算,就可以在O(n) 的时间内得到 a 数组 。
后续补充:异或差分数组构造
题目链接:Face The Right Way G
题目相关细节:
- 构造差分数组:
2
3
4
cin >> a[i];
b[i] = a[i] ^ a[i - 1];
}
- 使用差分数组:
总结

二维差分
如果扩展到二维,我们需要让二维数组被选中的子矩阵中的每个元素的值加上c,同样可以达到O(1)的时间复杂度。
二维差分数组
a[][]数组是b[][]数组的前缀和数组,那么b[][]是a[][]的差分数组
原数组:a[i][j]
我们去构造差分数组:b[i][j]
使得a数组中a[i][j]是b数组左上角(1,1)到右下角(i,j)所包围矩形元素的和。
构造二维差分b数组
同一维差分,我们构造二维差分数组目的是为了让原二维数组a中所选中子矩阵中的每一个元素加上c的操作,可以由O(n*n)的时间复杂度优化成O(1)
已知原数组a中被选中的子矩阵为 以(x1,y1)为左上角,以(x2,y2)为右下角所围成的矩形区域;
假定我们已经构造好了b数组,类比一维差分,我们执行以下操作
来使被选中的子矩阵中的每个元素的值加上c
b[x1][y1]+ = c ;
b[x1,][y2+1]- = c;
b[x2+1][y1]- = c;
b[x2+1][y2+1]+ = c;
每次对b数组执行以上操作,等价于:
1 | for (int i = x1; i <= x2; i++) |
我们画个图去理解一下这个过程:
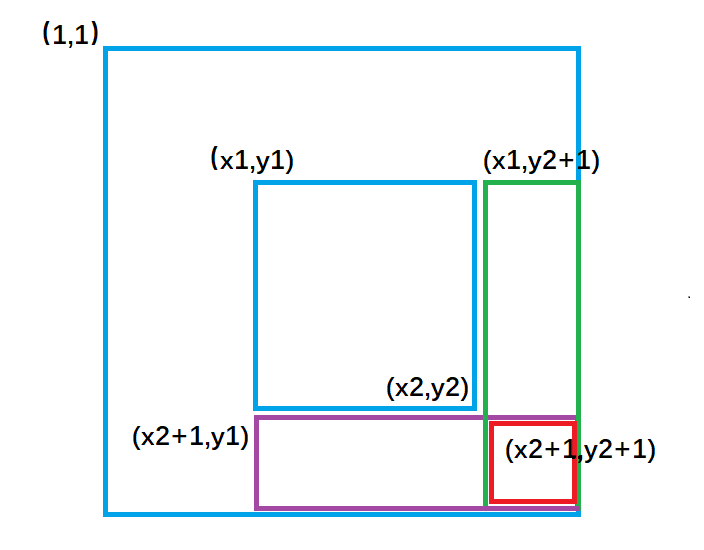
b[x1][y1] += c; 对应图1 ,让整个a数组中蓝色矩形面积的元素都加上了c。
b[x1,][y2 + 1] -= c ; 对应图2 ,让整个a数组中绿色矩形面积的元素再减去c,使其内元素不发生改变。
b[x2 + 1][y1] -= c ; 对应图3 ,让整个a数组中紫色矩形面积的元素再减去c,使其内元素不发生改变。
b[x2 + 1][y2 + 1] += c; 对应图4,让整个a数组中红色矩形面积的元素再加上c,红色内的相当于被减了两次,再加上一次c,才能使其恢复。
我们将上述操作封装成一个插入函数:
1 | void insert(int x1, int y1, int x2, int y2, int c) { |
我们可以先假想a数组为空,那么b数组一开始也为空,但是实际上a数组并不为空,因此我们每次让以(i,j)为左上角到以(i,j)为右下角面积内元素(其实就是一个小方格的面积)去插入
c = a[i][j],等价于原数组a中(i,j) 到(i,j)范围内 加上了a[i][j],因此执行 n*m次插入操作,就成功构建了差分b数组.
代码如下:
1 | for (int i = 1; i <= n; i++) { |
当然关于二维差分操作也有直接的构造方法,公式如下:
b[i][j] = a[i][j] − a[i − 1][j] − a[i][j − 1] + a[i −1 ][j − 1]
二维差分数组的构造同一维差分思维相同,因次在这里就不再展开叙述了。
二维差分压缩
这部分为后来做题的补充,觉得比较重要,所以记录下来(其实觉得二维差分压缩为一维有点dp思想)
我们可以考虑将矩形压缩成一维,比如处理一个2行的矩形时,将a[i][j]与a[i-1][j]相加,成为一个新的数组f [ n ],再使用上述代码进行动态规划,找出局部最优解。
简单来说,就是在输入的时候,再次加上a[i-1][j],这样可以用减法来快速表示压缩的矩形。
具体代码如下:
1 | scanf("%d", &n); |
假设二维差分数组输入的是:
1 | 0 -2 -7 0 |
在经过前缀和处理之后,输出的是这个:
1 | 0 -2 -7 0 |
可以模拟一下,a[i][j] - a[i-k][j]正好是以i为最下面一行,往上k行的压缩结果,这就很方便地表示了压缩后的矩形。
1 | for (i = 1; i <= n; ++i) { |
总结

模板题
海底高铁
海底高铁
题目背景
题目描述
题目描述
该铁路经过 个城市,每个城市都有一个站。不过,由于各个城市之间不能协调好,于是乘车每经过两个相邻的城市之间(方向不限),必须单独购买这一小段的车票。第 段铁路连接了城市 和城市 。如果搭乘的比较远,需要购买多张车票。第 段铁路购买纸质单程票需要 博艾元。
虽然一些事情没有协调好,各段铁路公司也为了方便乘客,推出了 IC 卡。对于第 段铁路,需要花 博艾元的工本费购买一张 IC 卡,然后乘坐这段铁路一次就只要扣 元。IC 卡可以提前购买,有钱就可以从网上买得到,而不需要亲自去对应的城市购买。工本费不能退,也不能购买车票。每张卡都可以充值任意数额。对于第 段铁路的 IC 卡,无法乘坐别的铁路的车。
Uim 现在需要出差,要去 个城市,从城市 出发分别按照 的顺序访问各个城市,可能会多次访问一个城市,且相邻访问的城市位置不一定相邻,而且不会是同一个城市。
现在他希望知道,出差结束后,至少会花掉多少的钱,包括购买纸质车票、买卡和充值的总费用。
输入格式
第一行两个整数,。
接下来一行, 个数字,表示 。
接下来 行,表示第 段铁路的 。
输出格式
一个整数,表示最少花费
样例 #1
样例输入 #1
1
2
3
4
5
6
7
8
9
10
9 10
3 1 4 1 5 9 2 6 5 3
200 100 50
300 299 100
500 200 500
345 234 123
100 50 100
600 100 1
450 400 80
2 1 10
样例输出 #1
1
6394
提示
1 | 9 10 |
样例输出 #1
1
6394
提示
1 | 6394 |
到 以及 到 买票,其余买卡。
对于 数据 。
对于另外 数据 。
对于 的数据 。
AC代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
using namespace std;
int cnt[M];
int a[M], b[M], c[M];
int n, m;
ll ans = 0, t = 0;
int main() {
ios::sync_with_stdio(false);
cout.tie(NULL);
cin >> n >> m;
int pre, dst;
cin >> pre;
for (int i = 2; i <= m; i++) {
cin >> dst;
int maxi = max(pre, dst);
int mini = min(pre, dst);
cnt[mini]++;
cnt[maxi]--;
pre = dst;
}
for (int i = 1; i < n; i++) {
cin >> a[i] >> b[i] >> c[i];
}
for (int i = 1; i < n; i++) {
t += cnt[i];
ans += min(t * a[i], t * b[i] + c[i]);
}
cout << ans;
return 0;
}
1 |
|
- Title: prefix_sum_algorithm
- Author: Charles
- Created at : 2023-01-06 20:13:15
- Updated at : 2026-05-11 20:11:26
- Link: https://charles2530.github.io/2023/01/06/prefix-sum-algorithm/
- License: This work is licensed under CC BY-NC-SA 4.0.