
TinyML_for_frb
基于TinyML和视觉传感器的手语翻译器
背景说明
项目背景
在第一次答辩后,我们的第一个方案“非触屏输入设备”因适用范围的局限而建议更新观点,因此我们将书写文字识别进一步拓展为了手势识别,并将手语翻译器作为我们第二阶段的主体思路。
问题背景
交流是我们平时自然而然的行为,但对于某些人来说,这并不简单。全球听障失语人士人数如此惊人:目前,全球约有4.66亿人有听力损失,其中有3400万是儿童,预计到2050年,将有9亿人有听力损失
听力障碍可能由遗传、出生时的并发症、传染病、慢性耳部感染、使用药物、过度接触噪音和衰老引起,而发音障碍可能由气管插管、气管切开术或疾病或创伤造成的声带损伤引起。在某种程度上,发音障碍也可能是听力障碍的一种影响。尽管有许多方法和预防措施,但这些听障失语人士仍主要使用手语进行交流。
研究动机
使用手语,聋哑人可以以某种方式进行交流。但只有一部分人懂手语。如果需要聋哑人在公共场合讲话,往往需要请翻译来帮忙。如果利用可用的技术,为他们提供些较准确的手语翻译,将会给听障失语人士的交流沟通带来很大的方便。
方法实现调研
为可以提供较好的手语翻译。这意味着手语翻译方法必须是高效和准确的,同时对每个人都是可使用的,能接受的。
需要考虑的维度:准确性,经济性,便携性
笔谈
优:无成本,方便
缺:残障人士习惯的手语语法短时间较难理解;有些普通人可能很不适应与陌生人笔谈
线上手语翻译
优:多款社交产品支持,方案较多,视频通话技术壁垒弱
缺:缺乏手语人才、不能随时使用,效率太低、容易引起误会
传感器方案
(取决于传感器的种类与个数)
优:整体上经济性和便携性较好
缺:准确性一般
计算机视觉方案
(全球:微软、腾讯等等,方案较多)
优:方案很多,较为成熟;
缺:环境要求苛刻、交互场景单一、成本高;易受光线因素,视角因素影响;数据处理模型开销较大
肌电方案
(国内:2方案,16专利,没有产品化)
优:准确性高
缺:信号采集困难,无法识别大量手语;信号容易受到干扰;设备昂贵,经济性差
参考实现demo
相比于字符书写,手语识别需要更多的传感器,且手语表达过程本身也复杂了许多,因此,我选择了几个较为简单的手势来说明原理即可。
当前市场上没有手语翻译器这类产品,只有少数实验室在进行相关实验,甚至将视觉与加速度相结合利用机器学习训练的思路连论文都没有,具有一定的创新性。下面为参考实现的数据集:
你

好

能

帮助

再见

谢谢

对不起

功能实现细节
分类问题属于监督学习范畴,因此获得图像数据及其标签对于训练和测试目的至关重要。
数据采集
- 数据采集【低质量的相机在捕捉到的图像上有太多的噪声,可能会干扰特征提取】
- Kaggle数据集【公开的可使用的数据集很少】
- 通过数据增强来获得更多的数据,e.g:图像旋转
- 标准增强技术进行增强,如+/- 20°旋转
- OpenCV中的五种插值策略
预处理
-
图像裁剪或调整大小 图像尺寸缩小
保持输入内容基本不变
-
高斯滤波器
优:降低噪声;使图像产生平滑效果---------------缺:减少了细节
-
中值滤波器
优:过滤掉噪音,保持尖锐的特征-------------------缺:无误差传播
-
…
分割
-
灰度缩放
低计算量;简单的实现
-
阈值法
低计算量;性能快
e.g:Otsu算法
-
皮肤分割
优:实现简单--------缺:对光照敏感
-
形态滤波器
优:高效地增加受关注的区域------缺:特征可能不详细
-
背景减法
优:低计算量-------缺:取决于帧速率和物体速度;对光照敏感。
特征提取
-
主成分分析(Principal Component Analysis,PCA)
优:提高性能;减少过拟合-------缺:需要数据的标准化
-
加速鲁棒功能(accelerated Robust Features,SURF)
优:对不变数据有鲁棒特征;比SIFT更高效更快-------缺:有时可能会出现错误的匹配
-
卷积神经网络(Convolutional Neural Network, CNN)
分类
-
卷积神经网络
优:分类准确率很高。即使缺乏预处理也可以很好地工作-------缺:高计算量,需要庞大的硬件。
- 残差二值化网络
- 内存最优直接卷积
-
支持向量机(Support Vector Machine, SVM)
优:内存效率高,分类效率高-------缺:当数据中存在噪声时,性能较低
-
隐马尔可夫模型(Hidden Markov Model,HMM)
优:高效学习算法-------缺:高计算量,需很多训练数据
-
尺度不变特征变换(SIFT),小波矩,定向梯度直方图(HOG)和Gabor滤波器,决策树…
数据集
RWTH-PHOENIX-Weather 2014数据集
RWTH-PHOENIX-Weather 2014数据集是一个德语手语识别数据集,由德国亚琛工业大学(RWTH Aachen University)的计算机科学研究所和人类语言技术和语音技术研究所联合开发。该数据集包含了德语手语的动作序列、视频和手部关键点位置数据,是目前较为流行的手语识别数据集之一。该数据集的主要特点包括:
数据集规模较大:该数据集包含了大约约115小时的手语视频,共计大约27,000个手势序列。
多种手语类型:该数据集包含了不同类型的德语手语,包括数字、字母、词汇和短语等。
多种录制环境:该数据集使用了多种不同的录制环境,包括室内和室外,光线明亮和光线暗淡的环境等。
多种摄像头:该数据集采用了多种不同类型的摄像头进行录制,包括RGB、深度、红外等多种类型的摄像头。
多种标注信息:该数据集提供了多种标注信息,包括手部关键点位置、动作序列、手语文本等。需要注意的是,该数据集需要事先申请使用权限,申请方式和相关信息可以在数据集的官方网站上获得。
CSL
**● 发布方:**中国科学技术大学
● 发布时间:2015
**● 简介:**中国手语数据集(CSL)是由中国科学技术大学自2015年起利用Kinect采集的中国手语数据集,包含25K标记的视频实例,共有超过100个时长的视频,50个操作者拍摄,每个操作者重复5次,包含RGB、深度以及骨架关节点数据,分为孤立词和连续语句,其中单词有500类,每类含250个样例, 包含21个骨架关节点坐标序列;句子有100个,共 有5000个视频,每一个句子平均包含4~8个单词。
每一个视频实例都由专业的中国手语老师进行标注。
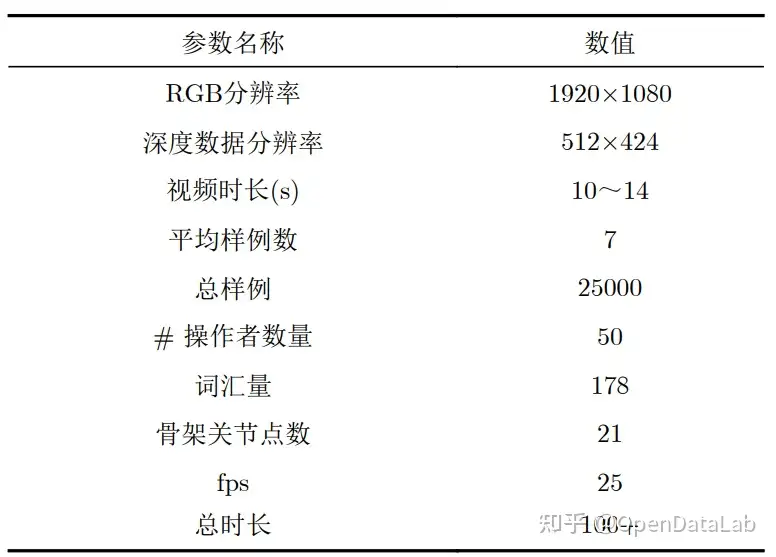
CSL数据集参数

CSL中国手语数据样例
SignLanguageRecognition/dictionary.txt at master · dluthwy/SignLanguageRecognition (github.com)
● 下载地址:
链接:https://pan.baidu.com/s/1RC0Ji3FnCNIKx3xkjSWDkQ 提取码:g3vq
链接: https://pan.baidu.com/s/1EJIbiFh0SGPUhteuux53Ug 提取码: 3qsu
● 论文地址:
Isolated SLR:
http://home.ustc.edu.cn/~pjh/publications/ICME2016Chinese/paper.pdf
Continuous SLR:
https://ieeexplore.ieee.org/doc
优势
在优势方面,目前研究的大多采用了以肌电信号为主要载体的手语分析(而且不知道有没有实物),肌电信号传感器本身价格十分昂贵(1200起步),成本很高,而且准确率也并没有很突出,而我们采用的视觉与加速度传感器本身则成本很低。
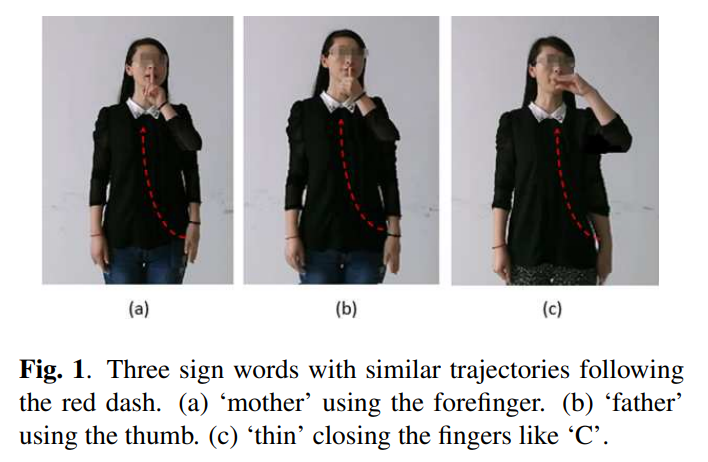
One cheap and helpful method is to use the color gloves. uses color gloves to make segmentation and hand tracking easily in American Sign Language recognition. But both data gloves and color gloves are wearable equipment and it may make signers feel uncomfortable.
视觉模型搭建
有哪些处理视频的神经网络
搭建用视频作为数据集的神经网络需要考虑到视频数据的时序性和空间信息,因此需要使用一些特定的神经网络结构。以下是一些常用的神经网络结构:
3D卷积神经网络(3D CNNs):
3D CNNs是一种可以处理带有时间信息的3D数据的神经网络。它的网络结构与2D CNNs类似,但在卷积层中添加了时间维度,以便捕捉视频数据中的时序信息。
LSTM神经网络:
LSTM神经网络是一种常用于处理序列数据的神经网络。它可以捕捉视频数据中的时间序列信息,并在各个时间步之间传递状态信息。
带注意力机制的神经网络:
带注意力机制的神经网络可以自动关注视频数据中最重要的部分。它可以通过计算每个像素点的重要性,来帮助模型更好地处理视频数据。针对不同的任务和应用场景,需要选择合适的神经网络结构,同时需要优化模型的超参数,例如学习率、损失函数、正则化等。此外,还需要使用适当的数据增强技术来扩充数据集,避免过拟合。
Bi-LSTM(双向长短期记忆神经网络);
3D神经网络如何搭建
以下是一个简单的用于视频分类的3D卷积神经网络的代码示例,使用的是Keras框架:
1 | pythonCopy code |
这个模型包含了两个3D卷积层和一个全连接层。输入数据的shape为(num_frames, height, width, num_channels),其中num_frames表示视频的帧数,height和width表示每一帧的高度和宽度,num_channels表示每一帧的通道数。在每个卷积层之后添加了一个3D池化层,以减少特征图的大小。最后通过全连接层将特征图映射到类别标签上。
如何将视频数据转化为可以投喂3D卷积神经网络的数据集
将视频数据转化为可以投喂3D卷积神经网络的数据集需要进行以下几个步骤:
视频预处理:首先需要对视频进行预处理,将其转换为模型可以接受的输入格式。通常情况下,需要将视频裁剪成固定长度的帧序列,使每个视频都可以表示为一个形状为(num_frames, height, width, num_channels)的张量,其中num_frames表示帧数,height和width表示每一帧的高度和宽度,num_channels表示每一帧的通道数(通常为3)。
数据增强:在进行模型训练之前,可以使用数据增强技术来扩充数据集,避免过拟合。例如,可以对每个视频进行随机裁剪、随机翻转、随机亮度、对比度等操作。
数据标准化:将视频数据标准化可以提高模型的训练效果。通常情况下,需要将每个像素点的值缩放到0和1之间,或者将其标准化为均值为0、方差为1的分布。以下是一个示例代码,可以将视频数据集转换为可以投喂3D卷积神经网络的数据集:
1 | pythonCopy code |
该函数读取视频文件,然后对视频进行采样和调整大小。最后将帧转换为张量,并进行标准化处理。
关于语句语序连续性的问题
手语机器翻译概述
手语机器翻译 (Sign Language Translation 简称 SLT),听起来这个词好像是一个常识性的词,但是其实这个词在2018年的时候,才在cvpr的一篇论文《Neural Sign LanguageTranslation》上首次提出,并在最近一两年做的人才渐渐多了起来。
那在2018年之前,研究者们都不做手语翻译任务嘛?答案是否定的,在SLT正式提出之前,人们在做的是Sign Language Recognition,简称SLR,也就是手语语言识别任务,大家更多的是把它当做图片/视频中动作、姿势的识别任务,而没有深入“手语语言”这个概念,《Neural signLanguage Translation》这篇论文提出了SLT的概念,并正式在SLR的基础上,加入了spoken language translation的模块。
可以先简单的理解为SLT就是在SLR之后,加入了一个translation的模块,输出的内容从一个简单的单词变成了一个完整的句子,SLT与SLR相比增加了任务的难度和完整性。但是在之后的研究中,这个框架也有一些变化,这里按下不表。
在2018年之后,不只是cv的研究者,nlp的研究者也参与进了SLT的研究工作中。
调研结果
首先SLR分为Isolated SLR和Continuous SLR两种,这是两种不同的技术,所以一般也不采用Isolated SLR组合形成句子的方法,我们所做的项目正是属于Isolated SLR领域。
其次,对于手语有一些不同于平时口语的特征,最常见的是语序颠倒和省略虚词。所以对于手语而言,在翻译时一个很长的句子也只是用几个词就可以表意了,比如“一本书”常用“书一”表示,“我开车时候很感觉不错”用手语表示为“开车感觉好”。
在这种情况下,如果真的需要解决语序问题可以进一步处理,我们所作的项目只做到SLR(手语机器识别),如果要实现SLT(手语机器翻译)需要通过NLP来实现。(可以将这些写到论文中)
NLP是自然语言处理(Natural Language Processing)的缩写,指的是计算机对自然语言的理解、处理和生成的一类技术。 NLP技术主要包括以下几个方面:
- 分词(
Tokenization):将一段连续的文本分成有意义的词汇单元。- 词性标注(
Part-of-speech tagging):对每个词汇单元进行词性标注,如名词、动词等。- 句法分析(
Syntactic parsing):将一句话分解成短语结构树,用于表示单词之间的关系。- 语义分析(
Semantic analysis):对文本进行语义分析,理解文本的含义和上下文。- 机器翻译(
Machine translation):将一种自然语言翻译成另一种自然语言。- 情感分析(
Sentiment analysis):对文本进行情感分析,判断文本的情感倾向。- 命名实体识别(
Named entity recognition):识别文本中的人名、地名、组织机构名等实体。 NLP技术在自然语言处理、机器翻译、信息检索、智能客服等领域有广泛应用。
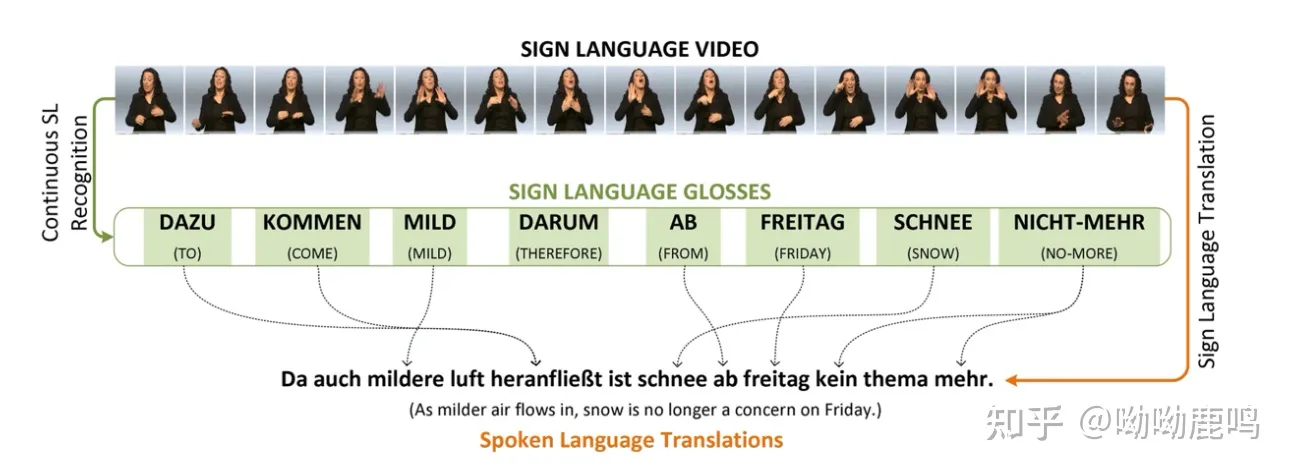
项目评价指标
评价SLR的指标是错词率( WordErrorRate WER):计算公式——WER=(DEL+INS+SUB)/Num。其中DEL,INS 和SUB 分别表示删除、插入和替换操作的次数;Num 表示一个语句中的单词个数。英文中,WER还分为token级别的和char级别的。
参考文献
基于佩戴式输入设备的手语识别方法 - 中国知网 (cnki.net)
基于肌电传感器和六轴陀螺仪传感器的手语识别研究 - 中国知网 (cnki.net)
sign language translation - 知乎 (zhihu.com)
dluthwy/SignLanguageRecognition: 中文孤立手语词识别;Bi-LSTM;SLR;500-CSL (github.com)
聋人用的手语的语法顺序和汉语有什么区别? - 一半喧嚣一半寂静的回答 - 知乎 https://www.zhihu.com/question/360714821/answer/940208251
- Title: TinyML_for_frb
- Author: Charles
- Created at : 2023-03-14 17:21:56
- Updated at : 2026-05-11 20:11:30
- Link: https://charles2530.github.io/2023/03/14/tinyml-for-frb/
- License: This work is licensed under CC BY-NC-SA 4.0.